上周一个做零售ERP的朋友约我喝酒。
他那天状态特别差。
饭吃到一半的时候,他突然开始骂人。
不是骂竞争对手。
是在骂他们自己公司销售。
我问怎么了。
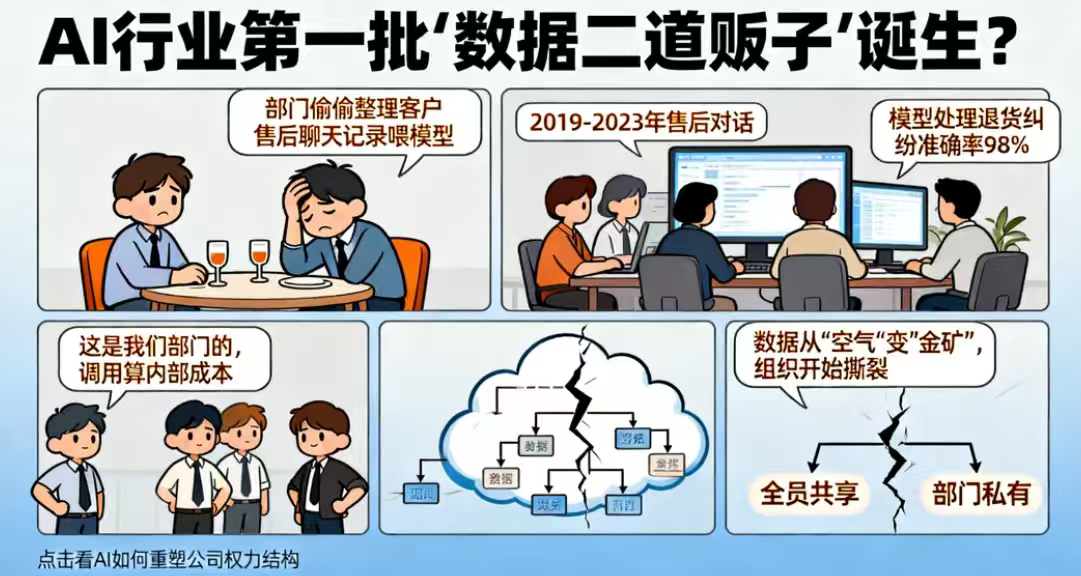
他说最近公司内部出了件特别离谱的事。
他们有个团队,偷偷把客户过去几年的售后聊天记录整理了一遍。
然后拿去喂模型。
结果后来发现。
这个模型在处理退货纠纷的时候,准确率高得离谱。
真正麻烦的地方在后面。
那个团队开始不愿共享数据了。
理由也很现实:
“这是我们部门自己整理出来的。”
再后来。
甚至有人提议:
其他部门如果想调用,要算“内部成本”。
我听到这里的时候,脑子里突然有点发麻。
因为这已经不是“AI提效”了。
这是组织结构开始变了。
以前公司里的数据,大部分时候其实像空气。
没人真正在意。
客服能看。
运营能调。
销售偶尔也会拿去做分析。
因为所有人默认:
数据只是业务副产品。
但AI进来以后。
很多公司突然发现。
有些历史数据一旦喂进模型。
真的能直接提高赚钱效率。$OPEN
整个味道一下就变了。
我后来想起前几年做供应链金融的时候,也见过特别像的一幕。
那时候很多企业原来根本不在意订单流。
后来银行开始拿订单数据做授信。
公司内部立刻开始:
锁数据。
卡权限。
做归属。
因为一旦一个东西能换钱。
所有人都会重新定义:
“这是谁的。”
最近我重新翻OpenLedger关于归因路径和Data Intelligence那部分资料的时候,这种感觉越来越重。 ([openledger.xyz](https://www.openledger.xyz/?utm_source=chatgpt.com))
很多人现在聊OpenLedger。
还停留在:
AI链。
数据网络。
Agent经济。
但我最近越来越觉得。
它真正碰到的,可能是另一个特别现实的问题:
谁有资格卖数据。
注意。
不是谁“拥有”数据。
而是谁有资格:
* 整理数据
* 定义数据
* 标注数据
* 打包数据
* 解释数据
这个差别特别大。
因为很多企业的数据,其实天然是混乱的。
脏。
碎。
旧。
重复。
真正值钱的,从来不是“原始数据”。
而是:
谁能把这些垃圾,重新变成AI能吃的东西。
这里面最容易被忽略的一点是。
这个过程特别像以前的贸易行业。
真正赚钱的人,经常不是生产的人。
而是:
中间整理货的人。
我小时候家里有人做过服装尾货。
有些厂根本卖不掉的库存。
到了中间商手里。
重新分类。
重新打包。
重新配货。
利润立刻就出来了。
AI数据现在越来越像这个逻辑。
很多公司真正有价值的东西。
其实一直都躺在服务器角落里。
没人整理。
没人清洗。
没人知道怎么用。
但一旦有人开始能把这些东西:
* 做结构化
* 做标注
* 做归因
* 做训练适配
新的角色就会开始出现。
我现在越来越怀疑。
AI行业接下来很可能会冒出一批特别奇怪的公司。
他们不做模型。
也不做应用。
专门做:
“数据翻新。”
听起来有点土。
但真实商业世界里。
很多大行业最赚钱的环节,本来就不性感。
比如供应链里的分销商。
比如金融里的资产打包。
比如互联网里的流量代理。
都是一样。
因为市场真正缺的,往往不是原材料。
而是:
把原材料变成“可流通商品”的能力。
而#OpenLedger 最近那套归因逻辑,最让我后背发凉的地方就在这里。
因为它开始让“谁处理过数据”这件事,第一次变得可记录了。
以前很多数据加工,其实没人看得见。
一个运营花半年整理知识库。
最后离职。
公司甚至不知道哪些内容是他做的。
但如果未来:
* 数据处理路径能记录
* 使用收益能回流
* 贡献影响能被追踪
那整个行业会开始出现一种新的身份:
“AI数据中间商。”
他们不拥有数据。
但他们知道:
怎么让数据更值钱。
这里最危险的地方,其实不是技术。
而是组织关系。
因为以前很多部门之间的数据共享,是建立在:
“反正也不值钱。”
可一旦有人发现:
某些数据经过处理后,真的能提高模型效果。
所有人一定会开始:
藏数据。
甚至抢数据。
我最近已经开始看到一些很细小的变化了。
有公司开始:
* 限制导出历史聊天记录
* 单独给知识库做权限
* 记录谁调用了哪些数据集
表面上是安全。
但底层逻辑其实已经变了。
大家开始默认:
数据以后可能是资产。
而资产一定会带来边界。
最有意思的是。
过去互联网行业一直有个幻觉:
数据越开放,效率越高。
但真实商业世界里。
一个东西只要开始值钱。
第一件事一定是:
先围墙。
这一幕其实特别像以前电商刚起来的时候。
最开始所有人都愿意共享供应链。
后来爆款越来越值钱。
大家立刻开始:
藏工厂。
藏渠道。
藏库存。
AI行业现在也开始有那个味道了。
尤其很多企业内部。
已经开始出现一种特别微妙的情绪。
表面上都在说:
“AI协同。”
但实际很多人已经开始偷偷留后手。
因为所有人都怕一件事:
自己整理出来的数据资产,最后变成别人部门的生产力。
所以我现在越来越觉得。
@OpenLedger 真正碰到的。
可能不是AI效率革命。
而是:
AI时代第一次“大规模数据流通关系重构”。
这东西一旦真的跑起来。
最后一定会出现新的产业层。
以前互联网最赚钱的是平台。
后面最赚钱的是流量分发。
再后来是支付。
AI时代下一批真正赚钱的人。
可能是:
那些最懂怎么“加工数据”的人。
当然。
这里面一定也会开始长泡沫。
因为只要“数据处理”开始值钱。
市场一定会出现:
* 虚假标注
* 数据包装
* 低质量清洗
* 伪归因
* 指标套利
这几乎是所有新资产行业的宿命。
但不管怎么说。
我现在越来越确定一件事。
AI行业接下来最先暴涨的。
可能不是模型公司。
而是:
第一批真正会“倒腾数据”的人。