
我发现大多数人在分析@OpenLedger 的时候,注意力总是会被它的代币经济或者数据归因机制给吸引走。但是吧最近我反复啃了几遍它的白皮书,让我意识到一个被严重低估的视角:那就是项目真正的杀手锏其实藏在底层的OpenLoRA性能架构里。我个人觉得这不是单纯的工程优化,而是一套让整个去中心化AI经济得以真正跑起来的经济性引擎,没有这一层下边一切归因、激励、合规的故事其实都站不住脚。$OPEN#OpenLedger
为了便于理解,我把OpenLoRA的性能价值拆解为五个相互咬合的关键维度,我看到他的每一环都在直接降低AI的运行成本,同时把节省下来的空间转化为$OPEN的使用场景,下边我简单说说看。
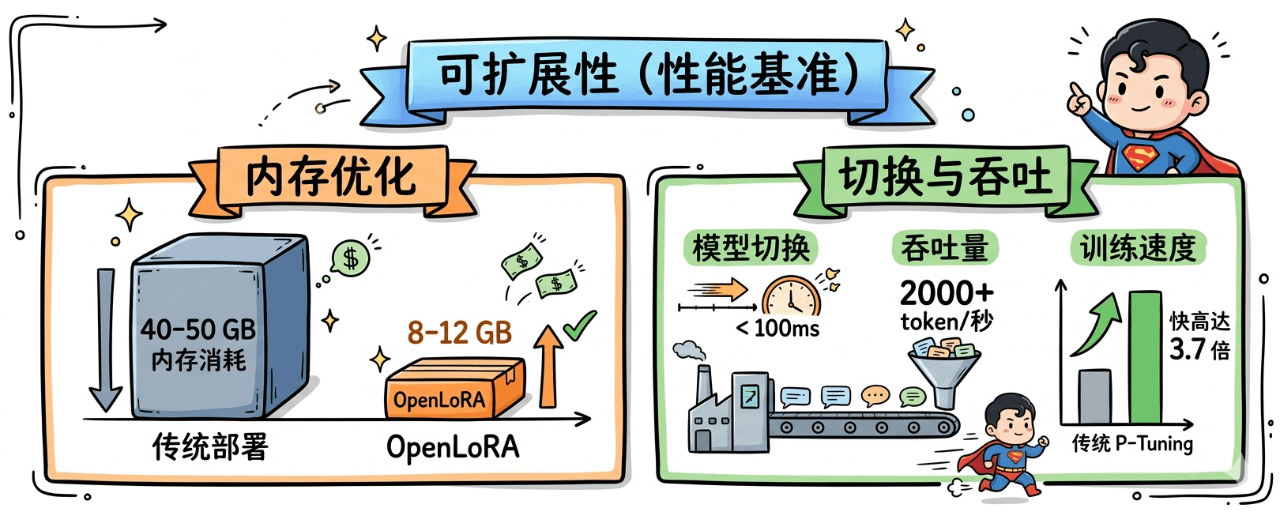
第一层 内存层,我说说8-12GB对比40-50GB背后的颠覆
我觉得可以这么说内存就是AI部署的入场券。传统模式下边部署一个微调模型动辄需要40-50GB的显存,这就意味着只有大厂或者有钱的机构才玩得起,普通开发者基本上是被挡在门外的。但是我看到OpenLoRA把这个数字直接压到了8-12GB,相当于砍掉了70%以上的硬件成本。这一刀下去,意义是非常巨大的——以前一台A100只能跑1个模型,现在同样的硬件可以并行跑4到5个模型。我个人觉得这才是真正让千模并发从PPT走向现实的关键,没有这一步后边的Datanets、ModelFactory就只是空谈而已。
第二层 切换层,我说说小于100ms的模型切换意味着什么
你想想看在去中心化AI场景里边,不同用户、不同代理调用的是完全不同的模型,如果每次切换都要重新加载几十秒,整个体验就崩了。我看到OpenLoRA把模型切换时间压缩到了100ms以内,这是一个什么概念呢,基本上就是人眼几乎察觉不到的延迟。这一点我觉得非常关键,他让一台GPU可以像CPU调度进程那样去调度成百上千个微调模型。说白了,这才让Agent经济、个性化AI服务这些应用场景从理论变成可执行的方案。
第三层 吞吐层,每秒2000+ token的实战意义
我觉得吞吐量这个指标很多人看不明白,但其实他直接决定了商业化的天花板。每秒2000+ token是个什么水平呢,基本上已经追平甚至超过了一些中心化API服务的响应速度了。你想想看这就意味着OpenLedger上跑的AI模型,无论是在DeFi里边做策略生成,还是在游戏里边做NPC对话,响应速度都不输Web2的成熟产品。我个人觉得这才是去中心化AI能不能从理想走到日活百万产品的分水岭,没有吞吐就没有用户,没有用户后边的代币消耗就是无源之水。
第四层 训练层,3.7倍于传统P-Tuning的速度优势
我觉得训练速度其实比推理速度更被低估。传统的P-Tuning微调一个垂直模型可能要好几天,而OpenLoRA把这个流程加速了3.7倍,这就意味着原来一周的迭代周期被压缩到了两天以内。你想想看在AI这种日新月异的赛道里边,迭代速度就是生死线。我看到这个加速对ModelFactory里边那些非技术贡献者尤其友好,他们可以用更低的成本、更快的节奏去试错、去优化自己的模型,整个生态的创新密度会被指数级放大。
第五层 经济层,性能优势如何转化为OPEN的真实需求
当前面四层性能优势全部跑通之后,OPEN代币的需求逻辑就变得无比扎实。你想想看以前别人质疑去中心化AI最大的痛点是什么呢——就是贵和慢。但是OpenLoRA直接把成本砍掉70%、把速度提到中心化水平之上,这就让链上AI服务第一次具备了和Web2正面竞争的资格。每一次模型调用、每一次切换、每一次推理,全部都在消耗OPEN,而前面提到的性能优势会持续把更多的开发者、更多的应用、更多的真实用户拉进生态里边来,这种从基础设施反推代币需求的逻辑,我觉得才是最健康的飞轮。
我认为@OpenLedger 的真正护城河不是某一项叙事的领先,核心是它在底层用OpenLoRA这种工程级的优化,把去中心化AI不可能商业化这个魔咒给打破了。今天你看它可能只是一组冷冰冰的性能数字,明天它可能就是支撑起整个链上AI经济跑起来的那条主动脉。我觉得这层价值,市场远远还没有反应过来 。