
The AI industry keeps behaving like compute is the whole story.Every launch cycle sounds the same now. Faster tokens. Bigger context windows. More polished assistants. New multimodal demos with cinematic music and dramatic benchmark charts. Meanwhile the actual material feeding those systems the data itself is turning into a mess underneath the surface.
 Not because data is disappearing.
Not because data is disappearing.
Because useful data is becoming harder to separate from synthetic noise, recycled outputs, spam automation, engagement farming, and low-context garbage produced at industrial scale.
That part matters more than people want to admit.
You can already feel the shift happening across AI communities in 2026. Smaller teams are talking less about “infinite scaling” and more about data reliability, dataset freshness, provenance tracking, and controlled refinement loops. Quietly, the conversation changed.
That’s where openledger.xyz starts becoming interesting.
Not as another generic AI platform.
More as an attempt to redesign how contribution itself works inside AI training economies.
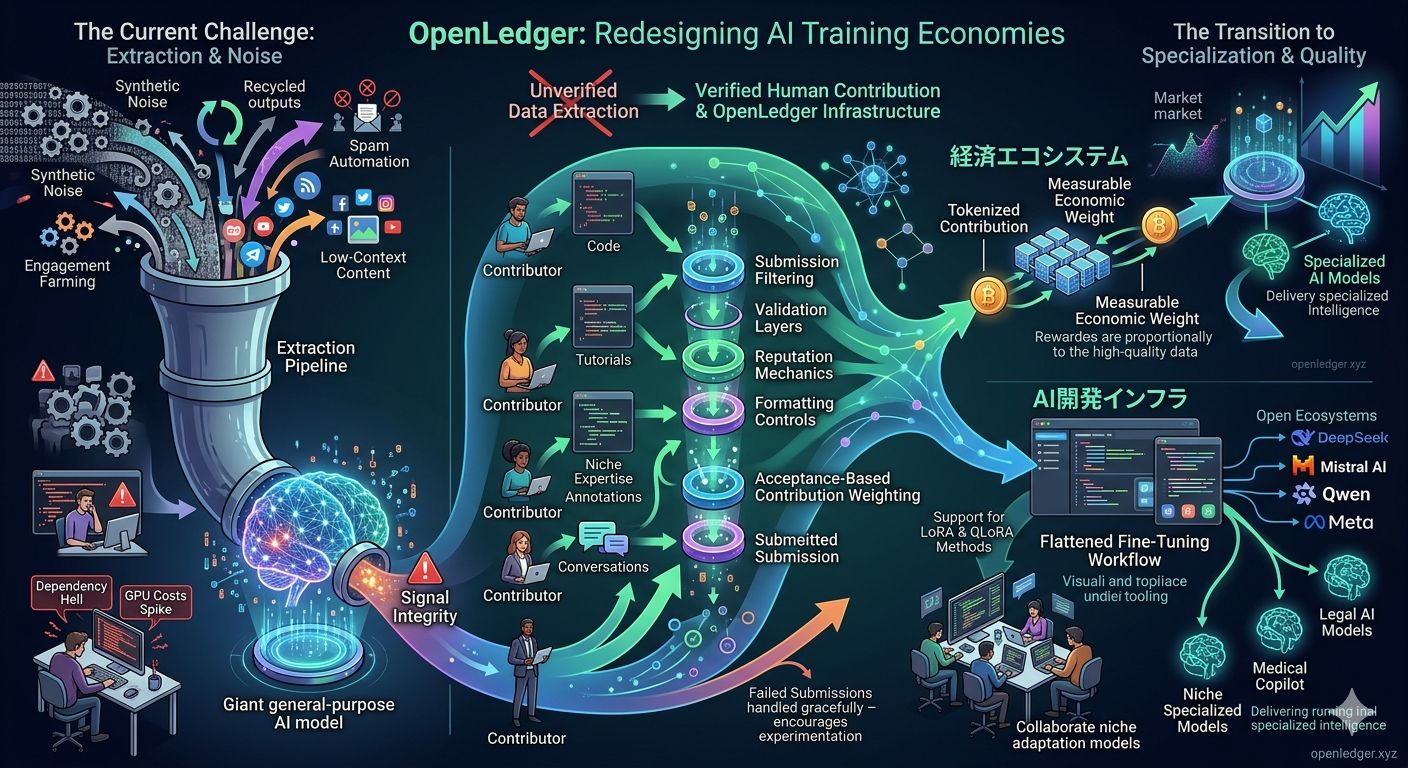
Most AI systems today still operate through a strangely one-directional structure. People create information constantly tutorials, conversations, code, corrections, niche expertise, community discussions, annotations and platforms absorb that value almost invisibly. Once the training pipeline starts, contributors vanish from the economic layer.
The internet becomes extraction fuel.
OpenLedger seems to be pushing against that assumption without turning the entire system into chaos.
And honestly, that balance is harder than it sounds.
A fully open contribution system looks attractive in screenshots and whitepapers. In practice, they often decay fast. Anyone who spent time inside poorly moderated crypto ecosystems during the previous cycle already knows what happens next: rewards attract volume, volume attracts spam, and eventually nobody can tell whether the system is improving or just getting louder.
OpenLedger’s structure feels unusually aware of that danger.
The restrictions are not subtle either. Submission filtering. Validation layers. Reputation mechanics. Formatting controls. Acceptance-based contribution weighting.
Some people will immediately call that anti-decentralization. I don’t think that criticism really survives contact with reality anymore.
Because unrestricted participation does not automatically create useful systems. Sometimes it creates landfill.
That’s the blunt truth most projects avoid saying out loud.
One thing I found surprisingly thoughtful is how the platform appears to handle failed submissions. Rejections don’t seem designed to permanently crush contributor standing. That sounds like a tiny design choice until you watch how humans actually behave inside incentive systems.
Punishment-heavy systems eventually train people to avoid risk.
And once contributors stop experimenting, the quality ceiling drops quietly over time.
There’s a subtle psychological difference between: “Your submission wasn’t useful.”
and
“You are now less valuable.”
A lot of platforms accidentally merge those two ideas together.
OpenLedger appears to keep them separate.
That alone changes contributor behavior more than people realize.
The other side of the project — the model training infrastructure — may actually matter just as much.
Because AI tooling still remains weirdly hostile to normal builders.
Even now, in 2026, there are too many workflows where someone spends three hours troubleshooting dependencies instead of training anything meaningful. One package update breaks another package. CUDA errors appear from nowhere. Terminal logs become unreadable halfway through. Then somebody on a forum says the fix only works on Ubuntu from six months ago.
Very glamorous industry.
OpenLedger seems to be trying to flatten some of that friction by making model interaction and fine-tuning feel more operationally visual instead of deeply engineering-dependent.
That changes participation patterns.
The moment model adaptation becomes easier to navigate, the distance between “consumer” and “builder” starts shrinking fast. Crypto ecosystems amplify that effect because incentives move people quickly once barriers drop low enough.
And the timing makes sense.
The market itself is shifting toward smaller specialized systems anyway.
Large general-purpose models still dominate headlines, but underneath that media layer, niche adaptation is exploding. Legal workflows. Medical annotation systems. Local-language assistants. Finance-specific copilots. Industrial monitoring tools. Internal enterprise reasoning models. Small focused systems trained on tighter feedback loops are improving much faster than many expected.
That’s why OpenLedger’s support for LoRA and QLoRA methods feels strategically realistic instead of performative.
Most independent developers are not retraining giant foundation models from scratch. They can’t afford to. Lightweight specialization is where actual experimentation happens now.
Especially once GPU costs spike again. Which they probably will.
And there’s another detail here people overlook.
Open ecosystems become far more interesting when compatibility stays broad.
OpenLedger’s connections across ecosystems tied to models from DeepSeek, Mistral AI, Qwen, and Meta widen the experimentation surface considerably. Once developers can move between different model families without rebuilding everything from zero, strange and useful workflows start appearing naturally.
That’s usually where innovation comes from anyway.
Not from giant coordinated roadmaps.
From random builders discovering something weird at 1:17 a.m. while testing a niche dataset nobody else cared about.
There’s also a larger market pressure forming in the background now: synthetic saturation.
AI-generated content is flooding the internet so aggressively that many training pipelines are starting to recycle machine-produced outputs back into newer models. Researchers have been warning about this loop for over a year, and by 2026 the concern feels much less theoretical.
The value of verified human contribution is increasing, not decreasing.
Which means systems capable of filtering, validating, ranking, and economically organizing trustworthy data may end up becoming more important than another marginal benchmark improvement.
That’s partly why OpenLedger feels less like a pure AI product and more like infrastructure trying to emerge early.
Still, none of this guarantees the model succeeds.
Actually, the hardest part probably hasn’t started yet.
Contribution economies behave differently once real money arrives at scale. Reputation systems become targets. Farming behavior increases. Governance pressure grows. Coordinated manipulation appears. Low-quality optimization strategies multiply incredibly fast once incentives mature.
Crypto history is full of systems that looked elegant before financial gravity hit them.
So the real test is not whether OpenLedger can attract contributors during the early phase.
The real test is whether quality survives once contribution itself becomes economically competitive.
That’s where most decentralized systems start wobbling.
But at least this project seems to understand the core problem clearly: AI systems do not improve infinitely through scale alone. Eventually the bottleneck becomes signal integrity.
Better filtration.
Better validation.
Better incentive alignment.
Better contribution design.
That layer has been strangely ignored while everyone races to build larger and louder models.
Maybe OpenLedger scales well. Maybe governance becomes difficult later. Maybe the contribution economy gets distorted under heavier financial pressure. All of those outcomes are possible.
But the larger idea underneath it already feels important.
The industry is slowly moving toward a future where data itself stops behaving like invisible background material and starts behaving more like productive infrastructure with measurable economic weight attached to it.$OPEN #OpenLedger @OpenLedger $PEPE $USDC

