I’m sitting here thinking about how the world of artificial intelligence has been quietly splitting into two camps, and it’s something we’re all feeling even if we don’t have the words for it yet. On one side, you’ve got these massive centralized companies hoarding data and models like dragons sitting on piles of gold, and on the other side, you’ve got millions of developers, researchers, and everyday people who are generating incredible value but have no real way to capture it. That’s the problem OpenLedger walked into the room to solve, and honestly, the more I dig into what they’re building, the more I think they might actually pull it off. They’re not just making another blockchain with a catchy AI sticker slapped on it. They’re trying to build a permissionless and verifiable data infrastructure that turns the entire lifecycle of AI, from raw data all the way to autonomous agents, into something you can own, trade, and monetize. And they’re doing it in a way that feels almost inevitable once you understand the mechanics underneath.
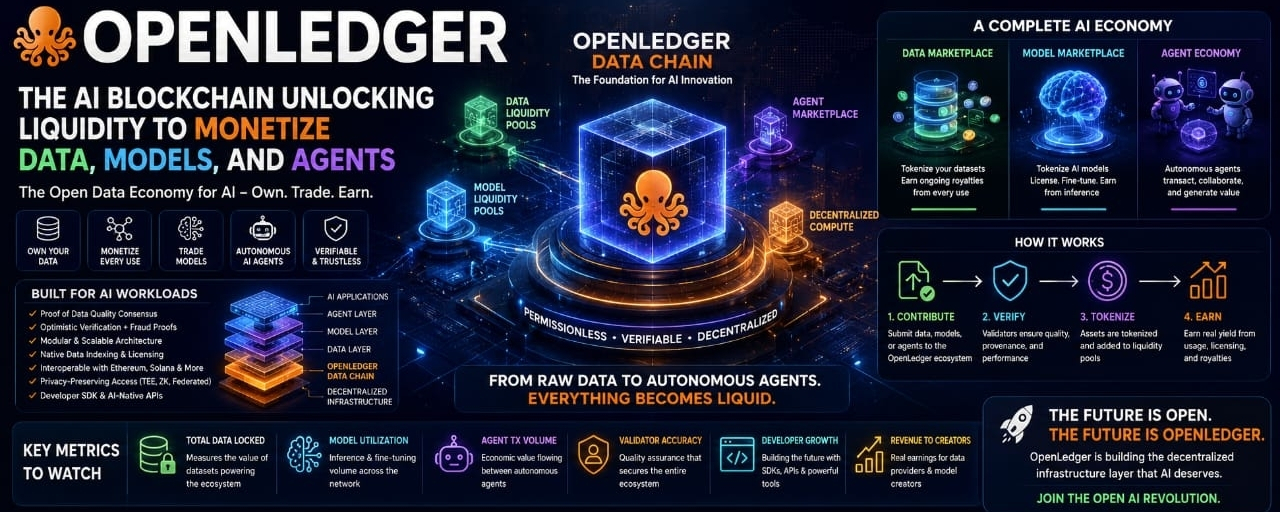
The core idea behind OpenLedger is beautifully simple even though the technology is anything but. They’ve created a specialized layer-1 blockchain that’s purpose-built for artificial intelligence workloads, and the entire network revolves around what they call the OpenLedger Data Chain. This isn’t just a place to store files or run smart contracts for DeFi applications. It’s a decentralized ecosystem where data becomes a liquid asset class, where AI models can be fractionalized and traded, and where autonomous agents can operate independently while generating real economic value. I’m talking about a system where the data you contribute to training a model earns you ongoing royalties, where developers can license specialized models without dealing with gatekeepers, and where AI agents can pay each other for services using native on-chain primitives. The vision is massive, but when you break it down step by step, it starts to make a lot of practical sense.
THE FOUNDATIONAL ARCHITECTURE AND WHY IT MATTERS
OpenLedger’s Data Chain operates as a sovereign proof-of-stake blockchain that was designed from the ground up to handle the unique demands of AI workloads, and this is where the technical choices really start to matter. Unlike general-purpose blockchains that treat data as an afterthought, OpenLedger integrates storage, computation, and verification directly into the consensus layer. When someone contributes a dataset to the network, it doesn’t just sit there as a blob of bytes waiting to be referenced by a smart contract. The data gets chunked, indexed, and fingerprinted using cryptographic proofs that allow downstream consumers to verify its integrity and provenance without needing to trust the original uploader. This is crucial because in the AI world, garbage data leads to garbage models, and if you’re going to build an economy around data monetization, you need ironclad guarantees that what you’re buying is authentic, unaltered, and properly attributed. The network uses a combination of zero-knowledge proofs and optimistic verification to make this work at scale, and the validators in the system don’t just secure the chain, they actively participate in verifying data quality and model outputs through a mechanism called Proof of Data Quality, which we’ll get into later.
Modular execution environment**: The chain separates consensus from execution by using a modular rollup architecture that allows AI-specific computation to happen off-chain while settling proofs on the main ledger, which means complex model training and inference tasks don’t clog the network or drive gas fees through the roof.
Native data indexing**: Every piece of data that enters the ecosystem gets automatically indexed with metadata tags, licensing terms, and usage history, creating a searchable global catalog that AI developers can query to find exactly what they need without intermediaries.
Interoperability bridges**: The network connects to major ecosystems like Ethereum and Solana through trust-minimized bridges, allowing assets and data to flow freely between OpenLedger and the broader Web3 world, which is essential for liquidity and adoption.
Decentralized identity layer**: Contributors and consumers operate through persistent on-chain identities that accumulate reputation scores based on data quality, model performance, and honest participation, creating a trust framework that doesn’t rely on centralized authorities.
Programmable licensing**: Data and models come with embedded smart contracts that automatically enforce usage rights, royalty distributions, and access controls, so creators can set terms once and let the blockchain handle enforcement forever.
HOW THE DATA MONETIZATION ENGINE ACTUALLY WORKS
Let me walk you through the actual flow of value because this is where things get really interesting and where OpenLedger distinguishes itself from every other data marketplace that came before it. Imagine you’re a research lab that has spent years collecting specialized medical imaging data, or maybe you’re a decentralized community that’s been crowdsourcing labeled datasets for a specific use case. In the traditional world, you’d either keep that data locked up or sell it once for a flat fee and watch the buyer build a billion-dollar company on top of your work. OpenLedger changes this completely by introducing what they call Data Liquidity Pools. When you contribute data to the network, it gets tokenized into fungible data tokens that represent fractional ownership of the underlying dataset. These tokens can be staked into liquidity pools where AI developers and model trainers can access the data by paying usage fees that flow back to token holders. The more your data gets used, the more fees you earn, and because everything is on-chain, the attribution and payment flows are completely transparent and automated.
Data contribution and validation**: You submit your dataset through the network’s ingestion pipeline, and validators run quality checks including deduplication analysis, bias detection, and completeness verification, and only data that passes these checks gets tokenized and added to the catalog.
Tokenization and fractional ownership**: The validated data is split into standardized chunks and represented as ERC-20 compatible tokens on the OpenLedger chain, allowing data ownership to be distributed across thousands of participants who can trade their shares on integrated decentralized exchanges.
Usage-based royalty streams**: Every time a developer accesses your data for training or fine-tuning, the smart contract governing that dataset records the usage and automatically distributes fees to token holders proportional to their stake, creating ongoing passive income from data you contributed once.
Dynamic pricing mechanisms**: The network uses an algorithmic pricing model that adjusts data access costs based on demand, uniqueness, quality scores, and historical performance, so high-value datasets naturally command premium prices without requiring manual price setting.
Privacy-preserving access**: Sensitive data can be accessed through secure enclaves and federated learning protocols that allow models to train on data without ever exposing the raw information, which opens up entire industries like healthcare and finance that couldn’t participate in open data markets before.
THE MODEL ECONOMY AND AGENT MARKETPLACE
Beyond just data, OpenLedger is building an entire economy around AI models and autonomous agents, and this is where I think the project’s long-term vision really shines. We’re seeing an explosion of specialized models right now, small language models fine-tuned for specific tasks, computer vision models trained on niche datasets, reinforcement learning agents that can navigate particular environments, and the list keeps growing. But the problem is that these models are scattered across Hugging Face repositories, private servers, and research papers with no unified way to discover, license, or monetize them. OpenLedger introduces Model Liquidity Pools that work similarly to the data pools but are designed for AI models. Developers can tokenize their trained models, list them on the marketplace, and earn fees whenever someone uses their model for inference or fine-tuning. What makes this particularly powerful is the composability aspect. A model on OpenLedger can directly reference and pay for the datasets it was trained on, creating an unbroken chain of value attribution from raw data all the way to the final application.
The agent economy is where everything converges into something that feels almost like science fiction becoming reality. Autonomous AI agents on OpenLedger are not just scripts that execute predefined tasks. They’re on-chain entities with their own wallets, reputation scores, and economic relationships. An agent that needs to analyze satellite imagery can automatically discover and pay for access to the best available geospatial dataset, rent compute resources from the network’s decentralized compute layer, run its inference, and deliver results to the end user, all without human intervention. Agents can also hire other agents for specialized subtasks, creating a mesh of autonomous economic activity that runs 24/7 on the blockchain. The agents themselves can be tokenized, allowing investors to buy shares in a high-performing trading agent or a content generation model and earn dividends from its ongoing operations. This creates a direct bridge between AI capability and liquid markets, where the best-performing agents naturally attract more capital and resources.
Model tokenization and fractional ownership**: Trained models are converted into on-chain assets with verifiable performance metrics, allowing anyone to invest in promising AI models the same way they’d invest in a startup or a piece of real estate, with returns coming from usage fees and appreciation.
Composable AI pipelines**: Developers can chain together multiple models and datasets from the marketplace into complex workflows, with each component automatically receiving its fair share of the revenue based on on-chain usage tracking and predefined royalty splits.
Agent autonomy and economic agency**: Agents operate with their own on-chain identities and wallets, making independent economic decisions about which resources to use, which services to offer, and how to price their outputs, all governed by transparent smart contracts that their creators can configure but not unilaterally control.
Reputation and slashing mechanisms**: Agents and model providers build reputation over time based on performance, uptime, and honest behavior, and malicious or consistently underperforming entities face economic penalties through slashing mechanisms that protect the ecosystem’s quality.
Cross-agent collaboration**: The network supports standardized communication protocols that allow agents built by different teams to discover each other, negotiate terms, and collaborate on complex tasks, creating emergent behaviors and capabilities that no single developer could build alone.
TECHNICAL CHOICES THAT SHAPE THE NETWORK’S CAPABILITIES
The technical architecture of OpenLedger reflects a series of deliberate choices that prioritize verifiability, scalability, and developer experience, and understanding these choices helps explain why the project is positioned differently from competitors. The team chose to build a sovereign layer-1 rather than launching as a rollup on Ethereum or another existing chain, and this decision came down to sovereignty over the validator set and the ability to optimize the entire stack for AI-specific operations. When you’re dealing with data verification, model inference proofs, and agent coordination, the computational patterns are fundamentally different from what you see in DeFi or NFT applications. A general-purpose blockchain would force compromises on either security or performance, but by controlling the full stack, OpenLedger can implement custom precompiles for cryptographic operations commonly used in AI verification, optimize block space allocation for large data commitments, and design fee markets that make sense for long-running computational tasks rather than simple transfers.
The consensus mechanism incorporates a unique Proof of Data Quality system that extends traditional proof-of-stake with specialized validation duties. Validators in the OpenLedger network don’t just validate transactions and produce blocks. They’re also responsible for running quality assurance checks on newly submitted data, verifying model performance claims, and monitoring agent behavior for anomalies. Validators who consistently provide accurate assessments earn additional rewards, while those who approve low-quality data or fail to detect issues face slashing penalties. This creates a cryptoeconomic security model where the financial incentives of validators are directly aligned with maintaining a high-quality ecosystem rather than just maximizing block production. The network also uses a technique called optimistic data verification where data and model claims are assumed valid unless challenged within a dispute window, during which challengers can submit fraud proofs to trigger a more thorough verification process. This keeps the system efficient under normal conditions while maintaining strong security guarantees.
Sovereign layer-1 design**: Complete control over the protocol stack allows for AI-optimized execution environments, custom cryptographic precompiles, and fee structures that accommodate the unique economic patterns of data and model marketplaces without being constrained by the design choices of a host chain.
Proof of Data Quality consensus**: Validators earn rewards proportional to their accuracy in assessing data quality and model performance, creating a self-policing ecosystem where the economic incentives naturally drive out spam, fraud, and low-quality contributions over time.
Optimistic verification with fraud proofs**: Data and model claims are accepted optimistically to maximize throughput, but anyone can challenge suspicious claims by posting a bond and triggering a verification game that resolves disputes through economic incentives rather than centralized arbitration.
Decentralized compute integration**: The network integrates with decentralized compute providers who offer GPU and CPU resources for training and inference, with payments and scheduling handled entirely on-chain through smart contracts that match resource providers with consumers.
Developer SDK and abstraction layers**: A comprehensive software development kit abstracts away blockchain complexity, allowing AI developers to interact with the network using familiar Python libraries and APIs while the underlying infrastructure handles tokenization, licensing, and payment flows automatically.
KEY METRICS AND INDICATORS WORTH WATCHING
If you’re trying to understand whether OpenLedger is actually gaining traction or just generating hype, there are several metrics that tell a much more honest story than any marketing materials ever could. The first and most fundamental metric is Total Data Locked, which measures the cumulative value of datasets that have been tokenized and deposited into the network’s liquidity pools. This is analogous to Total Value Locked in DeFi protocols, but instead of measuring idle capital sitting in lending pools, it represents productive data assets that are actively being used to train and improve AI models. A growing TDL indicates that data providers see real economic value in contributing to the ecosystem rather than keeping their data private or selling it through traditional channels. The quality of this data matters tremendously too, so I’d also watch the average quality score of newly onboarded datasets and the percentage of data that gets challenged or rejected during the verification process.
Model utilization rates provide another crucial window into ecosystem health. It’s not enough for models to be tokenized and listed on the marketplace. They need to actually be used for inference, fine-tuning, or as components in larger AI pipelines. High utilization rates suggest that the marketplace is efficiently matching supply with demand and that the models available on OpenLedger are genuinely useful for real-world applications rather than being speculative assets that sit idle. I’d also pay close attention to the volume and diversity of agent-to-agent transactions, because this metric reveals whether the autonomous agent economy is actually functioning or if it’s mostly theoretical. If agents are consistently paying each other for services, discovering new collaboration partners, and generating revenue that flows back to their token holders, that’s a strong signal that the ecosystem has achieved a level of self-sustaining economic activity that goes beyond simple speculation.
Total Data Locked and data quality scores**: The cumulative value and average quality of tokenized datasets on the network, which together indicate whether the ecosystem is attracting genuinely valuable data assets rather than just accumulating low-quality filler content.
Model utilization and inference volume**: The frequency with which tokenized models are actually called for inference or fine-tuning, revealing whether the marketplace is serving real AI development needs or functioning primarily as a speculative trading venue.
Agent-to-agent transaction volume**: The total economic value flowing between autonomous agents on the network, which measures the maturity and self-sustainability of the agent economy independent of human-initiated transactions.
Validator participation and accuracy rates**: The number of active validators and their historical accuracy in assessing data quality and model performance, which directly reflects the security and reliability of the network’s verification layer.
Developer activity and integration growth**: The number of active developers building on OpenLedger, the growth rate of new integrations with external platforms and tools, and the diversity of applications being deployed, all of which indicate long-term ecosystem health.
Revenue per data provider and model creator**: The actual earnings flowing to contributors, broken down by category and over time, which reveals whether the monetization promises are translating into real economic outcomes for participants.
RISKS AND CHALLENGES THE PROJECT MUST NAVIGATE
I want to be honest about the risks here because no project in this space is without serious challenges, and OpenLedger is attempting something extraordinarily ambitious that touches on some of the hardest unsolved problems in both blockchain and artificial intelligence. The first and most obvious risk is the cold start problem that plagues every marketplace business. A data marketplace without data is useless to model developers, and a model marketplace without models is useless to application builders, and an agent economy without economic activity is just a collection of idle smart contracts. OpenLedger needs to bootstrap liquidity on multiple sides of its marketplace simultaneously, and while the token incentives can help jumpstart participation, sustaining genuine economic activity beyond the initial incentive period requires building a product that’s actually better than the centralized alternatives. If the user experience is too complex, if the data quality isn’t competitive with what developers can get from established sources, or if the cost savings aren’t significant enough, the network could struggle to retain participants once the initial rewards dry up.