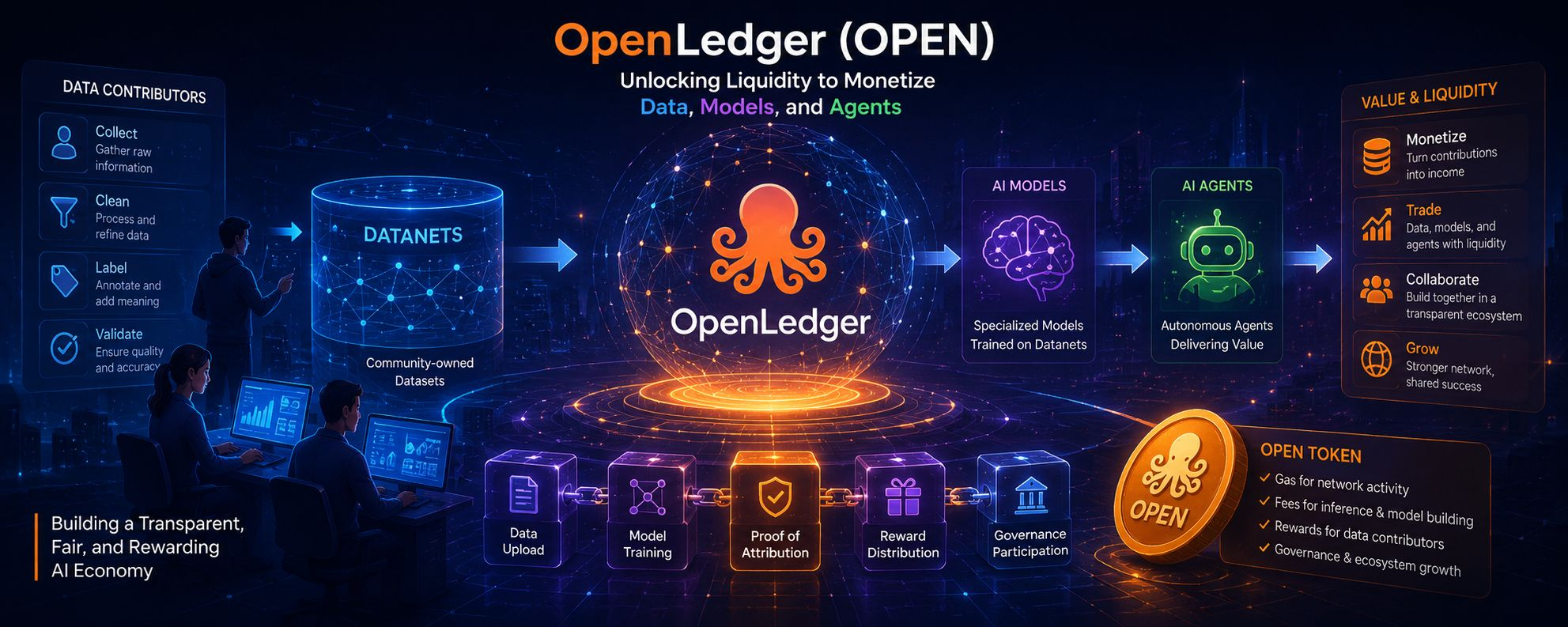
I’ve been thinking about OpenLedger as less of a crypto project and more of a response to a problem the AI world has not really solved yet. The project’s idea is simple enough to say out loud, but difficult to make real: data, models, and agents should not just exist as silent inputs and outputs. They should be traceable. They should carry value. They should leave a record of where they came from and who helped shape them. That is the heart of OpenLedger’s pitch, and I think that is what gives it some weight. It is not trying to decorate AI with blockchain terms. It is trying to turn contribution itself into something visible.
I have noticed that most conversations about AI still treat data as if it appears from nowhere. In reality, every useful system is built on layers of human effort: people collect the data, clean it, label it, correct it, test it, and feed it back into the model. Yet once the model starts producing results, those early contributors usually disappear from the story. OpenLedger is trying to interrupt that pattern. Its whole structure seems designed around the idea that contribution should be recorded and rewarded, not swallowed by the machine and forgotten.
What interests me most is the way the project uses the word “liquidity.” In this setting, liquidity does not just mean trading volume or token movement. It means making data and model contributions easier to value, easier to exchange, and easier to build on. That is a meaningful shift. If data can be linked to outcomes, and if those outcomes can be measured in a way people trust, then the contribution becomes more than a one-time donation to a platform. It becomes an asset with a history. That is a much more serious idea than the usual noise around AI and crypto.
I have also found the Datanet concept to be one of the more practical parts of the project. Rather than treating all data as one huge undifferentiated pile, OpenLedger describes community-owned datasets built for specific purposes. That matters because strong AI systems rarely come from generic input alone. They usually depend on narrow, well-shaped, carefully selected data. A model trained for one task often needs a completely different kind of information than a model trained for another. OpenLedger seems to understand that specialization is not a weakness. It is often where the real value lives.
The same is true of its attribution model. The phrase “Proof of Attribution” sounds technical, but the basic idea is easy to grasp. If a dataset or contribution helps shape a model, that contribution should not vanish into the background. It should be traceable. It should be counted. It should have a way to translate influence into reward. I think that is an appealing direction, especially at a time when so many AI systems are opaque by default. People want to know not just what a model can do, but how it got there. OpenLedger is betting that the answer should be written into the system itself.
That said, I do not think this is a simple problem dressed up in advanced language. Attribution sounds clean until you try to apply it to a real model. A model does not behave like a ledger entry. It is shaped by layers of preprocessing, architecture choices, tuning decisions, and inference behavior. Sometimes the contribution of one dataset is clear. Sometimes it is diluted by everything else around it. So when OpenLedger talks about making AI more transparent and more fair, I hear an ambitious claim that still has to survive difficult technical and economic tests. The idea is strong. The execution is where things will be judged.
I also appreciate that the project does not seem content to stay abstract. It offers tools that suggest it wants builders to actually use the network, not just admire the concept. ModelFactory, for example, points toward a more approachable way to fine-tune models without making the process feel like a machine-room ritual reserved for specialists. OpenLoRA adds another practical layer by focusing on efficient model serving. That tells me the team understands something important: people will not adopt a system like this just because the philosophy is good. They will adopt it only if it helps them work faster, cheaper, or with more control than the alternatives.
The token design fits into that same logic. OPEN is not presented as a detached speculative object. It is tied to the network’s activity, fees, and rewards. That makes the token feel more like an operational part of the system than a decorative one. I think that distinction matters. Plenty of projects say the token is “utility,” but then the utility ends up vague or thin. Here, the intended role is clearer: support network usage, power model-related activity, and compensate the people whose data or contributions matter to the system’s output. That creates a tighter loop between the technology and the economics around it.
Still, I would be cautious about treating any of this as solved. The hardest part of systems like this is not drawing the architecture. It is keeping the incentives honest. Once rewards are attached to attribution, people start optimizing for the reward. That can be good when it encourages better data and better curation. It can also go wrong if the system starts rewarding volume, gaming, or superficial signals instead of real quality. This is where many elegant ideas lose their shape. They work in principle, and then the ecosystem around them slowly bends the rules until the original purpose becomes harder to recognize.
That is why I find OpenLedger interesting in a more serious way than I usually find projects in this category. It is not just saying that AI needs decentralization. It is asking a more grounded question: how do we make contribution legible? How do we give people credit in a system that normally obscures them? How do we connect data, model behavior, and value without pretending those things are easier to track than they really are? Those questions are not flashy, but they are necessary.
I have come away from OpenLedger thinking that its real value is in how it reframes ownership. Not ownership in the narrow sense of who holds a token, but ownership in the broader sense of who has a visible stake in the intelligence being built. That is a more human idea than most people expect from blockchain projects. It suggests that datasets are not dead material, that models are not isolated machines, and that agents are not weightless abstractions. They are built things, shaped by people, and therefore part of a chain of responsibility.
That is what gives OpenLedger a voice of its own. It is trying to make AI less anonymous. It is trying to give economic form to contribution. It is trying to turn the invisible labor behind machine intelligence into something measurable and shareable. I do not think that is easy, and I do not think it will be solved by slogans. But I do think it is worth taking seriously, because the question underneath it is one the AI industry has avoided for too long.
