A research agent returns clean output.
Three minutes later the same OpenLoRA adapter gets hit again.
Then the same Datanet spikes.
Great. The data path is clean and the exhaust is still talking.
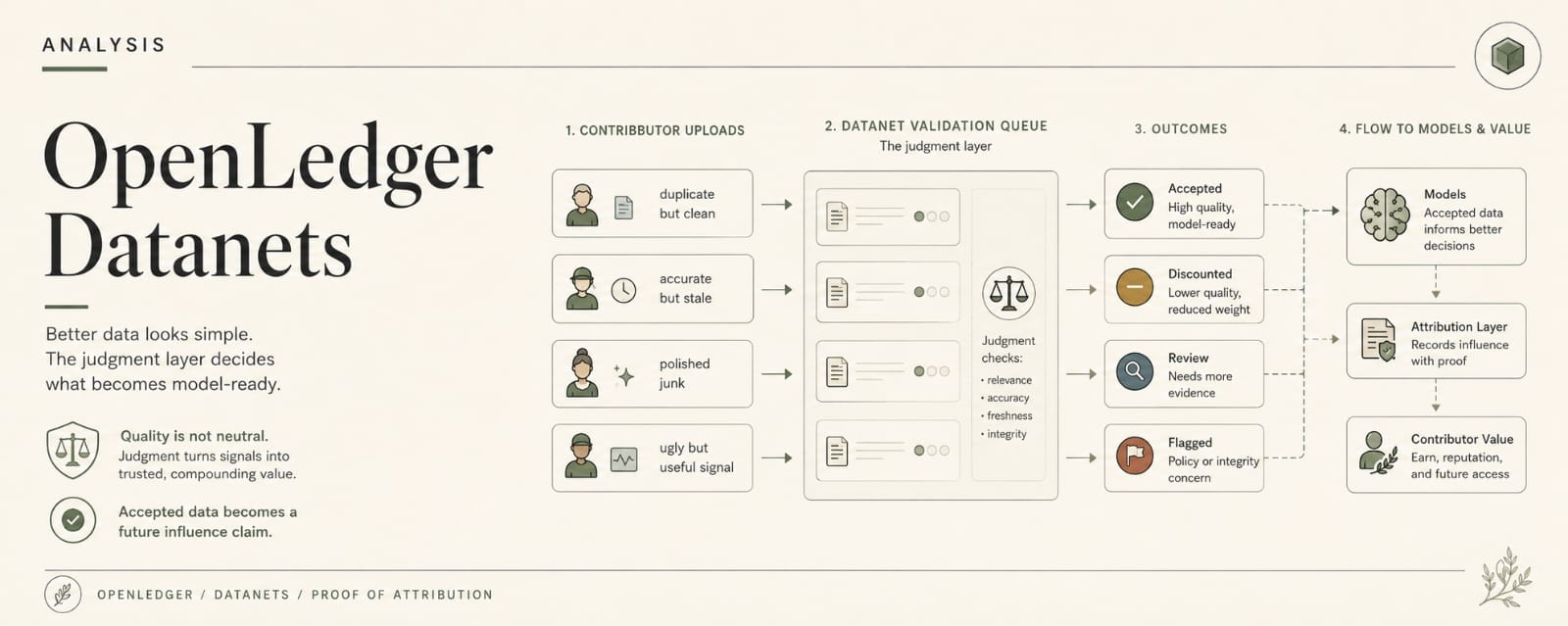
That is the version of OpenLedger that keeps getting harder to ignore. Not the nice clean provenance pitch. Not the one where Datanets stay organized, PoA traces contribution, the model path looks legible, the output lands... and everyone gets to feel like the hard part is over. Good. OpenLedger should be good at that. Centralized AI still makes too many workflows feel like somebody cooked the whole decision in a sealed kitchen and handed everyone else a plate with no receipt.
Alright.
The part nobody likes talking about is everything around the output.
Timing. Sequence. Frequency. Which adapter got called. Which Datanet spiked. Which route got retried. Which agent always seems to pause right before something else moves. The data path can stay clean and the pattern around it can still talk plenty.
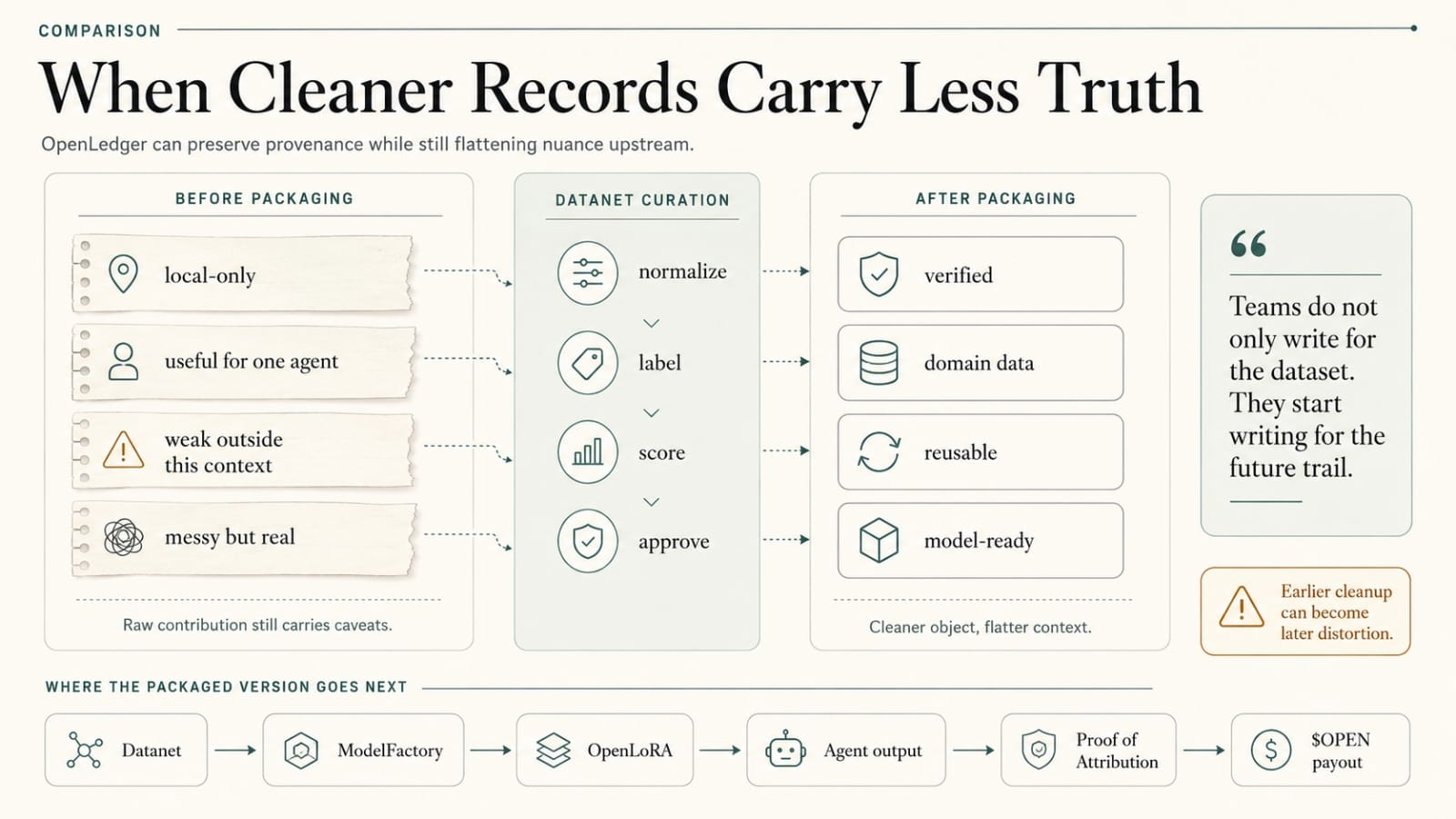
That is where the nice provenance story starts looking a little fake.
Say a team builds a trading or research agent on OpenLedger. The underlying source path stays legible. Good. Maybe a Datanet feeds a niche signal. Maybe an OpenLoRA adapter handles the specialized run. Maybe PoA can explain what shaped the output after the run. Good. But that does not stop the run itself from leaving a rhythm.
Very OpenLedger.
Very sensible.
Now stop staring at the trace for a second and look at the outer shell.
A desk uses the agent before rebalancing. The answer stays clean. But every time the workflow shifts from one Datanet family to another, the same adapter-call burst appears before the strategy changes. Nobody needed the raw input. They got the shape.
One agent route always adds the same delay before a high-confidence output.
One supposedly harmless retry pattern always shows up before the agent changes source mix. Okay....
One niche Datanet spikes before the agent changes its source mix, and now a watcher can infer which signal family mattered before the output says anything.
One class of adapter calls keeps bunching around the same kind of event.
After a while you do not need the raw input. You just need the rhythm and a reason to care.
And that is where it starts getting annoying.
OpenLedger's provenance layer protects the source story from becoming total guesswork. Fine. Great even. Cadence is another problem. Same with retries. Same with adapter choice. The outer shell still talks. A Datanet can stay properly attributed while the surrounding usage traces still leak enough for somebody patient to reconstruct what kind of workflow is probably happening. Not every detail. Does not need every detail. Just enough shape to make the clean trace feel late.
That is the nasty part. The trace may arrive clean after the run. The exhaust may have already told someone where the agent was leaning.
And people absolutely do this.
Markets do it.
Counterparties do it.
Competitors do it.
Analysts with too much time definitely do it.
Hide the raw input, fine.
Hide the exact weighting, alright.
Hide the private config... maybe.
Can you hide that the same OpenLoRA adapter gets hit three minutes after a known off-chain signal?
Can you hide that a weak-confidence path leaves the same retry scar every time it wakes up?
Can you hide that one supposedly ordinary Datanet is obvious from frequency alone once somebody watches long enough?
People glide past that because it ruins the nice version.
OpenLedger does not escape that just because the provenance core is stronger. In some ways it makes the outer pattern matter more. Once the output path gets easier to verify, observers start learning from shape. From repetition. From sequence. From the boring exhaust around the thing they are no longer forced to trust blindly.
And now the pattern is doing the talking.
Not is the trace valid.
More like... how much can I still infer without the trace spelling it out?
That matters economically too. A counterparty does not need perfect visibility if the metadata already gives them enough to form a view. Same with a market participant. Same with anyone trying to decide whether an agent is actually independent or just hiding a source dependency.
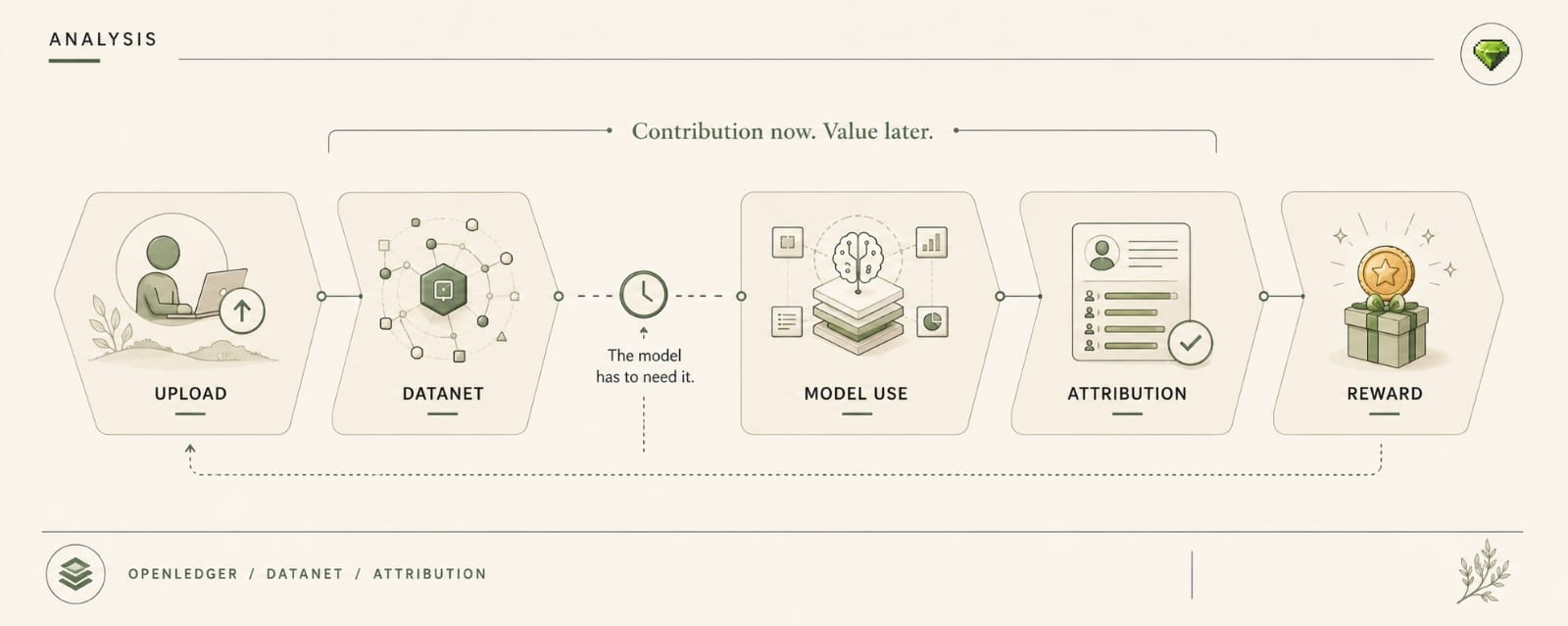
A traceable system can still be useful and still leak enough through pattern to create pricing consequences, strategic consequences, even basic social consequences around who is using what and when.
Great.
The data path is clean.
Shame about the footprints.
Now the leak is not “data exposed.” Worse. Source dependency exposed. Confidence pressure exposed. Agent intent exposed before the output even matters.
So no, I do not think OpenLedger’s hard problem is just tracing the data.
It is actually dealing with the story the system keeps accidentally telling through inference timing, adapter calls, retry behavior, Datanet spikes, marketplace routing, all the little external traces nobody puts in the hero graphic because that part is harder to sell than “AI provenance is fixed.”
And if OpenLedger gets real adoption in serious environments... trading agents, research markets, data-heavy automations, any of it... that problem gets bigger, not smaller. More volume means more pattern. More pattern means more chances for someone to stop caring about the raw input and start learning from the rhythm around it.
That is the part I can’t really stop looking at.
Because once source rhythm is enough, the raw data can stay hidden, PoA can stay clean, and the agent can still leak its strategy through the plumbing.