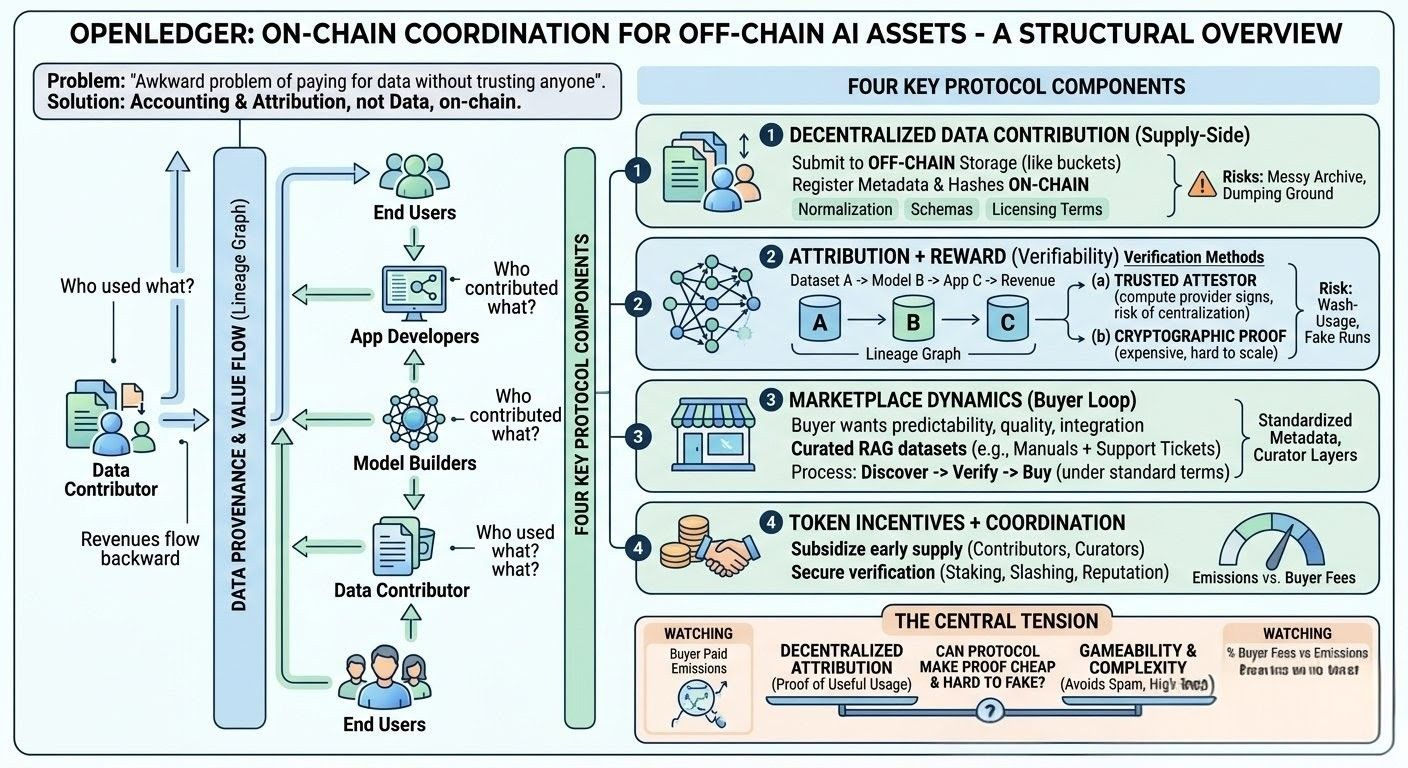
been going through openledger’s architecture notes and trying to translate it into “ok, how would this actually work when someone is training a model next month.” what caught my attention is that they’re not really trying to put datasets on-chain (thankfully), but to put the accounting layer on-chain: who contributed what, who used what, and how payments route back through that graph over time.
most people think openledger is just another ai + crypto token where you throw files into a bucket and farm emissions. i’m sure that dynamic will show up at the edges. but the more interesting thing is the long-term network design: can the protocol make data attribution credible enough that real buyers (not just token farmers) are willing to route their spend through it.
the components i keep coming back to:
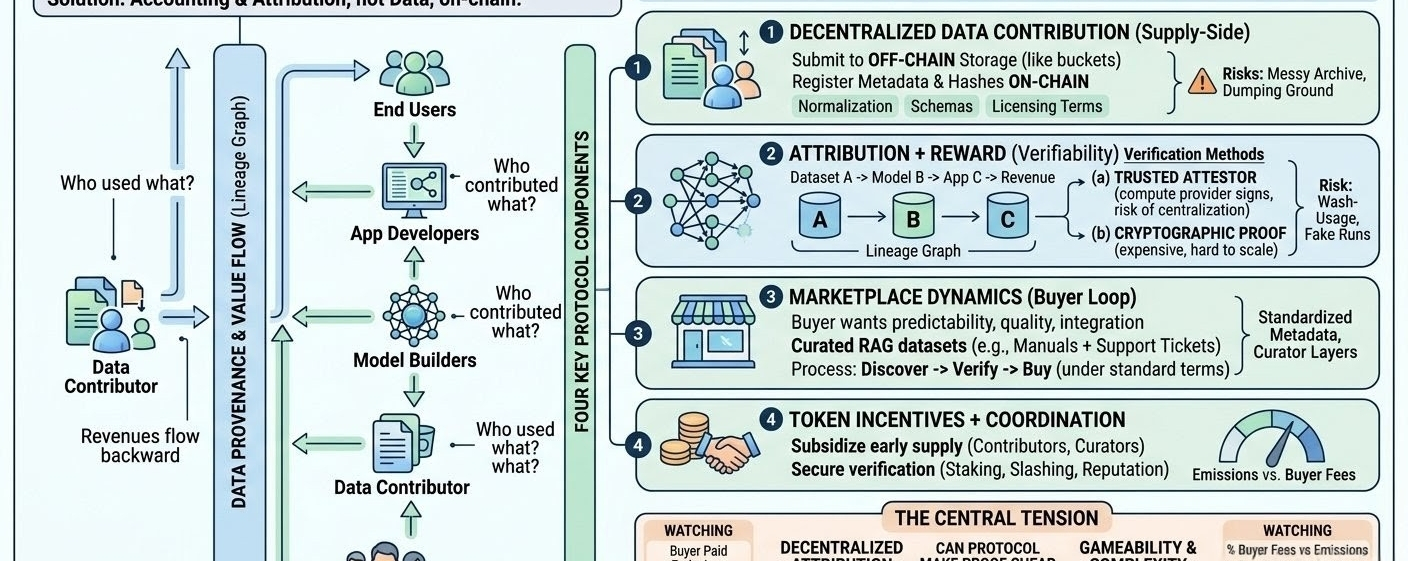
first, decentralized data contribution. this seems like a pipeline where contributors submit datasets/labels/evals to off-chain storage, then register metadata + hashes + some structured descriptors on-chain. the hard part isn’t storage, it’s normalization: schemas, versions, licensing terms, maybe even “intended use” tags. without that, you don’t get composability, you get a messy archive. i don’t yet know how strict openledger plans to be here, but strictness is kind of the difference between a market and a dumping ground.
second, attribution + reward. openledger’s pitch implies a lineage graph: dataset A was used to train model B, model B served inference for app C, revenues flow backward. honestly, attribution is the part i keep thinking about, because “used in training” is not a naturally verifiable event. you either (a) trust an attestor (compute provider, trainer, auditor) to sign what data was used, or (b) you try to prove it cryptographically, which gets expensive fast. so the design question becomes: what are the acceptable trust assumptions? if attribution depends on a small set of attestations, you risk re-centralizing. if it’s fully open, you risk wash-usage (people “using” their own data in fake training runs to trigger rewards).
third, marketplace dynamics (data + models). for this to be more than a registry, there has to be a buyer loop. a real buyer wants predictable licensing, quality signals, and low integration friction. i can imagine a model builder paying for a curated rags dataset (say, product manuals + support tickets with clean chunking and retrieval evals), because that saves time and reduces legal uncertainty. but then the protocol has to make it easy to: discover it, verify it’s not junk, and buy it under terms their lawyers don’t hate. centralized platforms solve this with contracts and gatekeeping; openledger is trying to solve it with standardized metadata + on-chain coordination + maybe curator layers.
fourth, token incentives + coordination / verification. the token seems to do two jobs: subsidize early supply (pay contributors/curators) and secure some verification process (staking, slashing, reputation). i’m a little skeptical about sustainability here because emissions can fake product-market fit. the system needs to converge toward “buyers fund rewards,” otherwise it’s just a redistribution program with extra steps.
who creates value, really? probably not the average uploader. value is created by (1) contributors with hard-to-get data or high-effort labeling, (2) curators who make datasets usable (dedupe, redaction, evals, packaging), and (3) builders who turn that into models or endpoints people pay for. openledger’s job is to make (1) and (2) investable: “if your dataset becomes important, you keep earning.” but that only holds if attribution stays trustworthy at scale.
the tension: openledger is basically betting on future ai demand that cares about provenance and attribution enough to route spending through a neutral protocol. maybe true in regulated verticals. but if most demand continues to be “good enough, cheapest, fastest,” the network will lean on incentives longer than it should. and spam is not hypothetical: any open contribution system will get hit with duplicated, low-quality, or rights-unclear data the moment rewards are meaningful.
no clean conclusion. i like the direction (on-chain coordination for off-chain ai assets), but the verification/attribution layer is where the whole thing either becomes durable or collapses into incentive gaming.
watching:
- percent of contributor rewards coming from buyer fees vs emissions
- share of datasets/models with repeat paid usage (not just one-time)
- dispute rate around licensing/ownership and how it’s resolved
- concentration of rewards (do a few curators/datasets dominate)
and i guess the question i’m left with: can openledger make “proof of useful usage” cheap and hard to fake, without quietly turning into a permissioned data platform with a token on top?