The intersection of Web3 and Artificial Intelligence has long suffered from a structural narrative flaw. Many projects claiming to merge the two technologies function merely as decentralized hardware brokers (renting out raw computational power) or as speculative wrappers around centralized enterprise engines. They do not change how AI learns, who owns its intelligence, or where the financial rewards of its outputs are distributed.
OpenLedger ($OPEN) approaches this problem from an entirely different paradigm. Positioned as a custom-built, AI-native Ethereum Layer-2 network constructed using the Optimism (OP) Stack, OpenLedger is designed to replace the standard data-harvesting model of Big Tech with an on-chain, auditable data economy. Supported heavily by its strategic integration within the Binance ecosystem, the protocol transitions AI away from corporate "black boxes" toward a standard known as Explainable AI.
Deconstructing the Technical Stack
To establish absolute data provenance—the verifiable tracking of a piece of data from its origin through its execution—OpenLedger structures its development pipeline into three interconnected layers. Each phase converts community-driven inputs into productive, high-liquidity financial assets on-chain.
1. The Collaborative Layer: Datanets
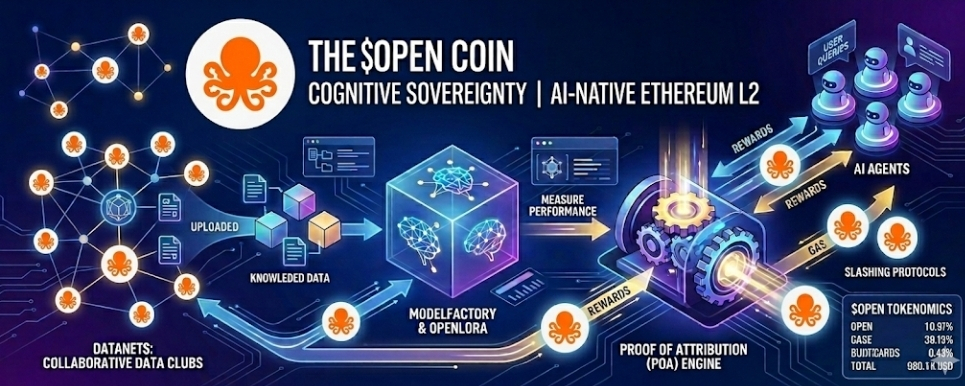
Standard foundation models rely on automated web scraping, a process that yields massive amounts of unverified, generic internet data. OpenLedger replaces this with Datanets, which function as sovereign, domain-specific "data clubs" hosted on-chain.
Communities form Datanets around precise verticals, such as smart contract exploit logs, specialized medical imagery, or regional compliance data. Contributors upload structured data arrays, tagging them with strict cryptographic metadata. This data is reviewed, cleaned, and verified by peer networks before it is hashed directly to the L2 state, producing a secure source of enterprise-grade training data.
2. The Refinement Layer: ModelFactory
Once high-utility datasets are secure within their respective Datanets, the network introduces ModelFactory. This acts as a code-free graphical interface layer enabling developers to fine-tune open-source neural architectures (such as LLaMA or DeepSeek models) using specific Datanet data clusters.
Rather than deploying capital-intensive, centralized clusters, ModelFactory optimizes computation through specialized adaptation techniques like OpenLoRA (Low-Rank Adaptation). OpenLoRA allows developers to train small, highly efficient weight changes to foundational models. This design means multiple hyper-specialized AI engines can operate simultaneously on single, decentralized GPUs, reducing computational overhead.
3. The Execution Layer: OctoClaw and Live Inference
Refined models are compiled and deployed as autonomous on-chain agents through an execution layer known as OctoClaw. When a consumer or third-party dApp initiates a query (inference) via an API call, OctoClaw coordinates the processing network.
Every single inference event is tracked dynamically on-chain, transforming standard chatbot queries or autonomous agent tasks into provable, monetizable network transactions.
The Protocol Innovation: Proof of Attribution (PoA)
The primary breakthrough within the OpenLedger ecosystem is its custom consensus layer: Proof of Attribution (PoA).
In traditional AI, data creators are rarely compensated because measuring the exact mathematical impact of a single training document on a final model response is incredibly difficult. OpenLedger embeds this calculation directly into the blockchain's execution logic.
How Proof of Attribution Operates:
When an agent processes a user prompt, the PoA cryptographic engine calculates the exact statistical influence that specific nodes and datasets within a Datanet had on the final output. The system acts as an automated accounting engine, instantly assigning financial credit across the data providers, curators, and hardware hosts responsible for the intelligence.
To prevent data poisoning—where bad actors attempt to upload low-quality or intentionally corrupted data to exploit the reward system—PoA enforces strict slashing protocols. Network validators and data curators must stake $OPEN tokens to verify data. If they approve malicious or fraudulent entries, their staked capital is programmatically confiscated and burned by the network.
The Structural Horizon: Navigating the Market Lifecycle
OpenLedger's distribution vector was heavily accelerated by its launch via the Binance HODLer Airdrop program, a move that distributed millions of $OPEN tokens directly to long-term BNB stakers. This strategic bootstrap immediately bypassed the traditional centralized distribution problem, placing ownership into a highly globalized network of independent validators and participants. Continuous ecosystem initiatives, like the 50,000 USDC CreatorPad campaigns on Binance Square, maintain high developer engagement.
However, as the network scales past millions of operational nodes and tens of thousands of deployed on-chain models, participants must track its structural token supply dynamics.
Following its initial Token Generation Event (TGE), the network's early ecosystem growth operated entirely on circulating community allocations. A critical architectural milestone arrives exactly twelve months post-launch, when the team and investor lockup cliffs expire.
This structural transition releases approximately 332.9 million previously locked tokens into a linear, 36-month vesting schedule, introducing roughly 9.2 million additional $OPEN tokens into the monthly ecosystem supply. To absorb this expanding liquidity smoothly, OpenLedger relies entirely on the organic demand generated by its underlying data engine: as more enterprises, Web3 protocols, and developers execute real-world queries through OctoClaw, the structural buy pressure from network gas usage and data licensing fees scales naturally alongside the network's token emission curve.
