
OpenLedger starts with a problem that the AI market keeps trying to walk past.
I’ve watched crypto recycle narratives for years. Storage, compute, data, DePIN, AI agents, “ownership,” “open networks.” Most of it becomes noise after a while. Another chart, another thread, another project claiming it found the missing piece. So when a project says it is building for AI, my first reaction is not excitement. It is fatigue.
OpenLedger is at least pointing at a real wound.
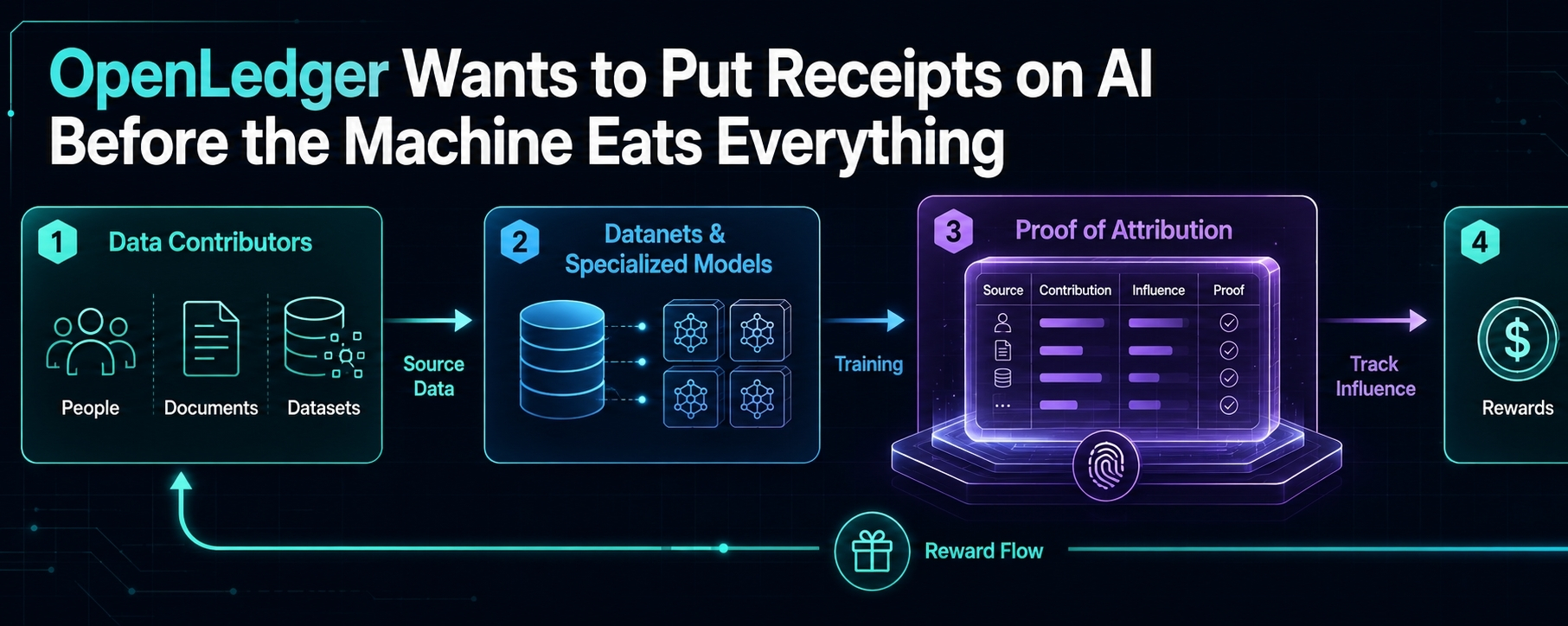
The project is focused on attribution. Not the shiny kind people mention in pitch decks, but the boring, heavy kind that decides whether contributors actually matter after their data has been used. In most AI systems, the model gives the answer, the platform captures the value, and the people or datasets behind that answer fade into the wall. That is the normal machine now. It eats knowledge, compresses it, monetizes it, and moves on.
OpenLedger is trying to slow that process down and leave a trail.
That trail is the core of the project. If a dataset helps train a model, if a contributor adds useful knowledge, if a smaller specialized model improves the final output, OpenLedger wants that influence to be visible. More than visible, actually. It wants it to become part of the reward system.
This is where the idea gets interesting.
Not loud. Interesting.
Because attribution is not some decorative feature. If AI becomes an economy, attribution becomes accounting. Who contributed? What was used? What created value? Who deserves a piece of the upside? These are not soft questions. These are the questions that decide whether AI becomes another extraction machine or something slightly less one-sided.
And yes, I know how that sounds. Crypto has promised fairer markets before. Many times. Usually, the promise turns into emissions, insiders, confusing dashboards, and a slow grind down the chart. So I’m not handing OpenLedger a free pass just because the concept sounds clean.
The real test, though, is whether Proof of Attribution can work when things get messy.
And AI is messy.
A single output does not come from one neat source. It can be shaped by training data, fine-tuning, prompts, tools, model adapters, retrieval layers, and whatever else got bolted onto the stack last week. Measuring who influenced what is not easy. Anyone pretending it is easy is probably selling something.
That is the friction OpenLedger has to survive.
If the attribution feels vague, contributors will not trust it. If the reward path feels too small, nobody serious will care. If the system feels too technical, builders will ignore it and keep using whatever is faster. Crypto users have a very low tolerance for noble infrastructure that does not pay, does not work, or takes too much effort to understand.
Still, there is something here.
OpenLedger’s idea of data networks makes sense because AI is not only moving toward bigger models. It is also moving toward narrower ones. Specialized models. Focused datasets. Agents trained for specific jobs. Crypto research, legal workflows, medical notes, gaming behavior, on-chain risk, developer activity — all of these areas need cleaner knowledge than a broad general model can usually provide.
That is where contributor-owned data starts to matter.
If a community builds a useful dataset, that dataset should not become dead material after one upload. It should carry weight. It should have memory. It should be able to keep earning if it keeps helping. That is the part of OpenLedger I find most practical, assuming the mechanics hold up.
But that assumption is doing a lot of work.
I’m looking for the moment this actually breaks into real usage. Not campaign activity. Not people farming points. Not temporary hype because AI is hot again. Real usage. Developers building on it because it solves a problem. Contributors adding data because the reward path feels worth the grind. Models using the system because attribution is not just morally nice, but economically useful.
That is the line.
OpenLedger is not interesting because it says AI. That word has been drained almost dry. It is interesting because it asks a question most of the market avoids: if intelligence is built from everyone’s knowledge, why does the value keep ending up in so few hands?
Maybe OpenLedger answers that.
Maybe it becomes another clean idea buried under execution problems.