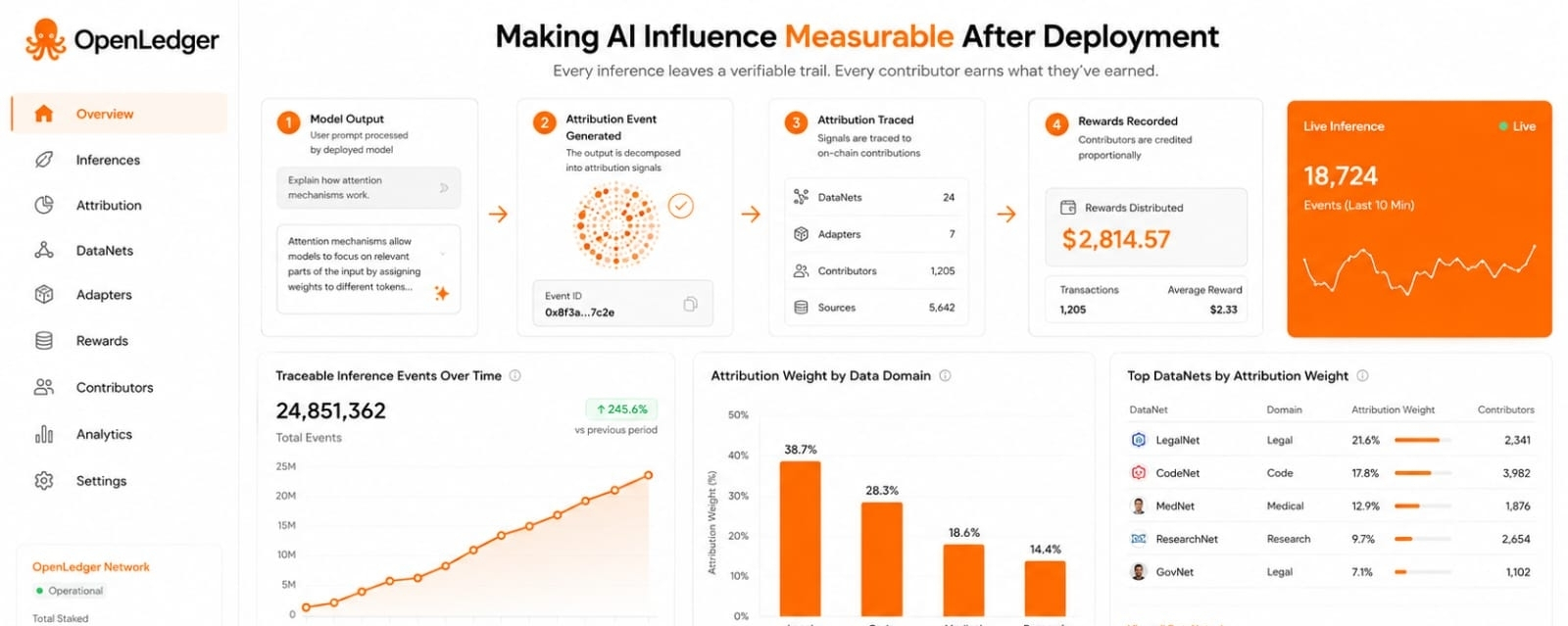
I keep coming back to one part of OpenLedger that feels quieter than the bigger phrases around AI blockchain. It is the attribution graph. My first reaction was that Proof of Attribution was mainly about payments to data contributors. That is still true but the stronger idea is that OpenLedger wants influence itself to become a visible record instead of a hidden assumption.
The official Proof of Attribution paper describes a public attribution graph where influence weights model data relations and inference events are stored. It also says this graph can support real time analytics for contributor reputation dataset saturation and underused niches. Leaderboards can also rank influential DataNets used adapters and rewarded contributors. That matters because it turns AI contribution into something people can inspect after a model is already working in the world. A dataset is not treated as a silent ingredient. It becomes part of a continuing record of use.
I find this more original than the basic reward story. Paying contributors is important but payment by itself can become vague if nobody can see why a reward happened. The attribution graph is the part that gives the payment logic a memory. It asks more specific questions. Which DataNet shaped this answer. Which contributor kept showing up across useful outputs. Which adapter helped a model perform a task. Those questions decide whether a data economy becomes trusted or becomes another black box with a token attached.
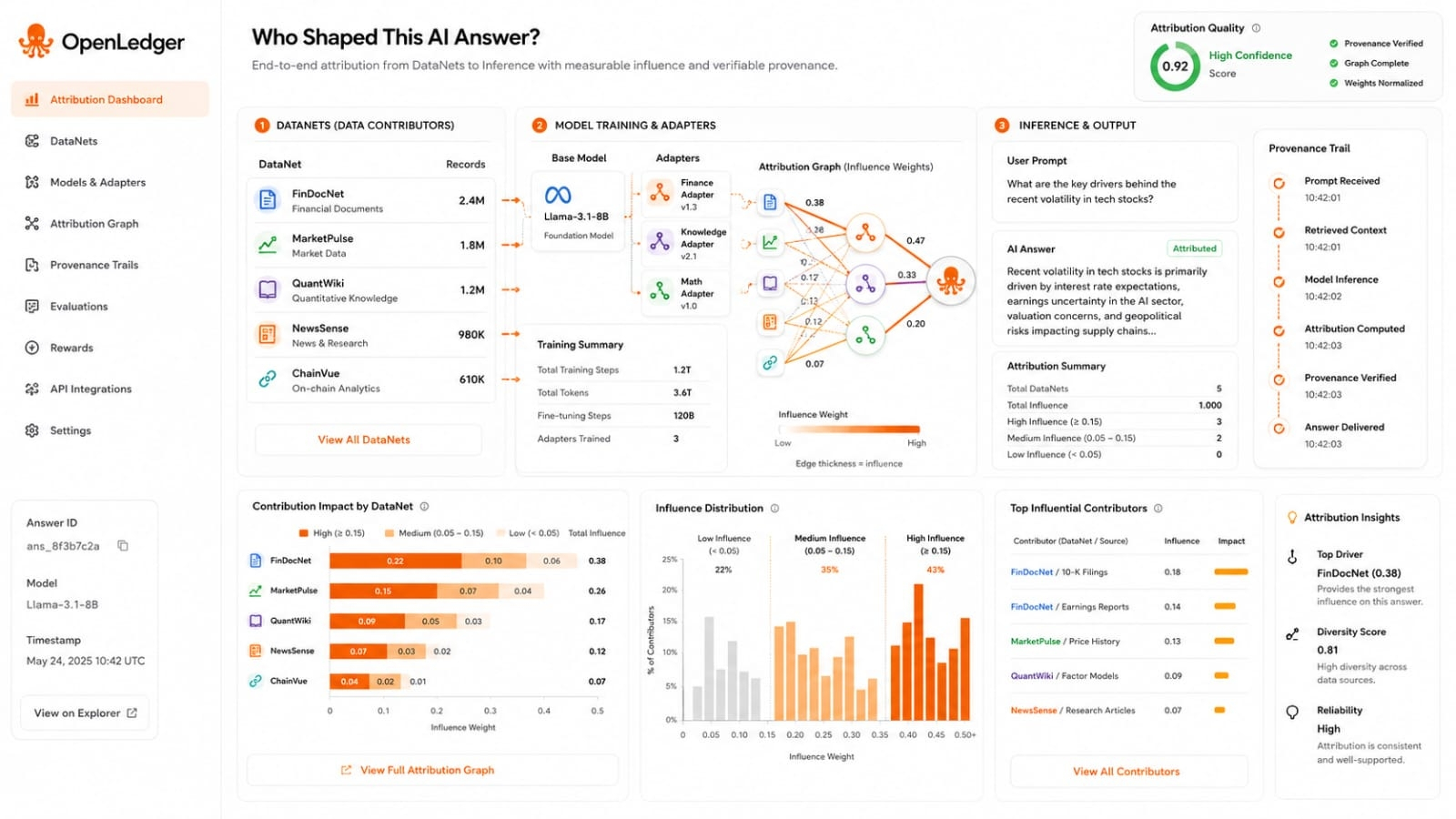
OpenLedger builds toward this through DataNets. In the paper a DataNet is described as a modular onchain dataset created through community contribution. Each DataNet is focused on a specific domain or task such as legal contracts code snippets medical transcripts sensor streams or question answer pairs. When contributors upload data the record can include contributor identity upload timestamp license terms preprocessing status and optional quality scores. The DataNet Registry then tracks dataset identifiers contributor records usage logs and attribution records so developers can inspect training sources while contributors can verify whether their data is being used. Attribution cannot work well if every input is messy and anonymous. The graph needs clean origin records before it can become a useful signal.
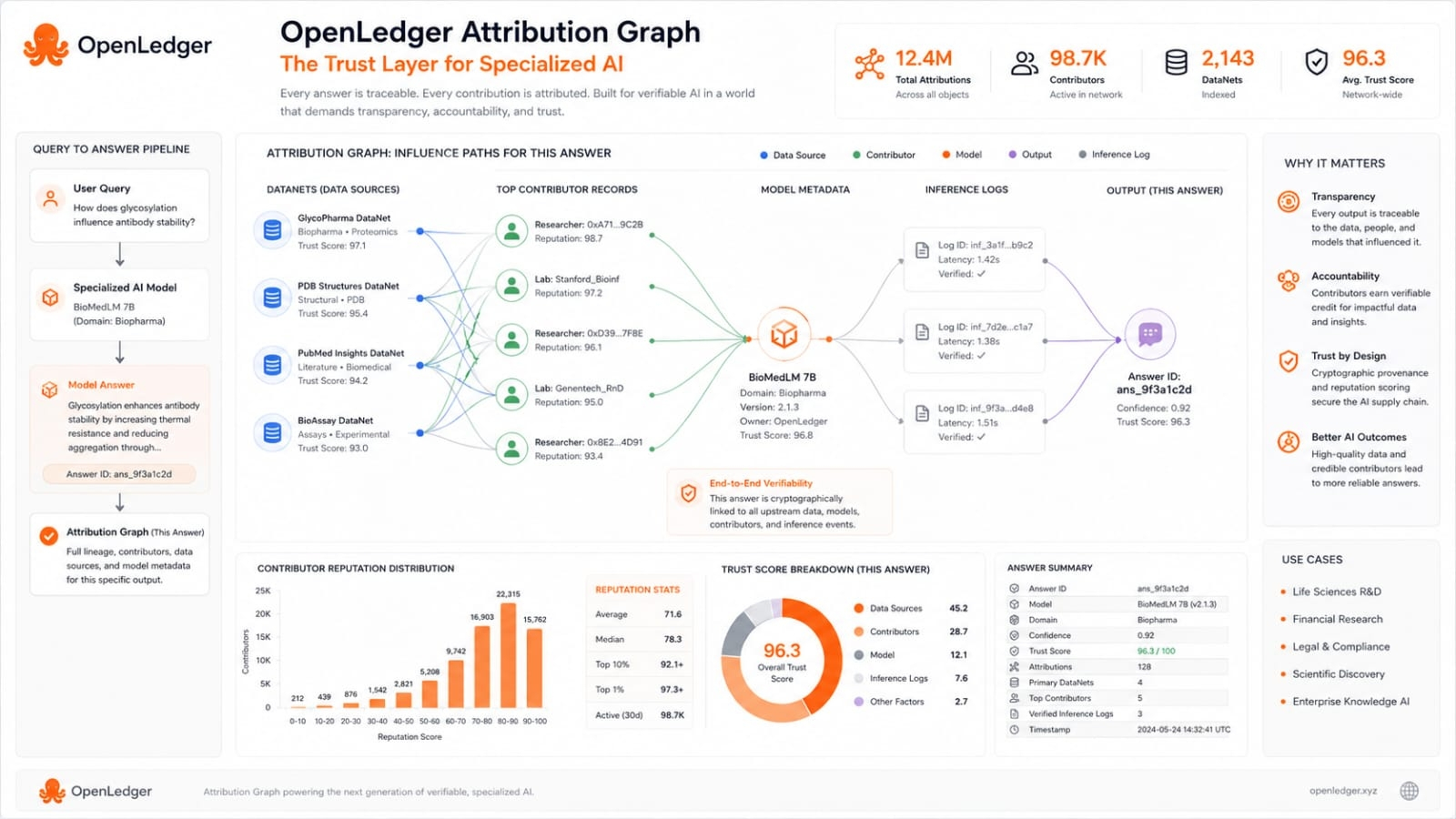
This is where the short term and long term pictures separate. In the short term the attraction is visibility. Builders want to know which data sources are worth using. Contributors want to know whether their work is being recognized. Communities want to know whether a DataNet is becoming useful or just collecting uploads. A public graph gives them a shared reference point. It does not guarantee quality by itself but it creates a place where quality can be observed over time.
The long term question is more demanding. If OpenLedger succeeds then the attribution graph could become a market signal for specialized AI. A strong DataNet would show real influence across model outputs. A strong contributor would keep appearing in useful inference traces. A strong adapter would show repeated downstream value. That is a cleaner way to think about AI data markets because it rewards demonstrated utility rather than assumed importance.
The technical logic behind this is not casual. For small specialized models OpenLedger discusses influence based attribution. For medium and large specialized language models it describes Infini gram as a suffix array based attribution method that helps trace token level influence and preserve provenance. Infini gram is meant to complement neural models rather than replace them because attribution is a layered problem rather than one simple trick.
Rewards then flow from those measured influence scores. OpenLedger says attribution is aggregated at the DataNet level so contributor rewards governance structures and analytics can work around community curated datasets rather than isolated samples. The paper describes influence scores being normalized across contributing DataNets and recorded onchain with model identifiers output hashes and metadata. At inference time this creates a trail from training data to model output.
The risk is that graphs can look precise before the underlying measurement is mature. If attribution methods produce noisy signals then leaderboards could reward the wrong behavior. If low quality data slips through then the graph may amplify clutter instead of expertise. OpenLedger partly addresses this by designing DataNets around metadata quality scores validation and curation. Still I would not treat the attribution graph as magic. It depends on clean inputs useful models and honest measurement.
What makes the idea timely is that OpenLedger is no longer only talking about passive model outputs. The official site presents OctoClaw as live for building automating and executing with AI agents in real time. Once agents start taking actions the need for provenance becomes stronger. It is one thing to know where an answer came from. It is another thing to know which data and model path influenced an automated action.
My thesis is that OpenLedger’s most underrated data layer may be the graph that records influence after deployment. DataNets give contributions structure. Proof of Attribution gives outputs traceability. Rewards give contributors an economic reason to participate. But the attribution graph turns all of that into a visible history that builders and communities can inspect. In the near term I would watch whether the graph can make contribution quality easier to judge. Over the longer term I would watch whether it becomes a real reputation layer for specialized AI. That is where OpenLedger’s idea becomes more than data ownership. It becomes data performance that can be seen.
