OpenLedger è uno di quei progetti che ti fa fermare un secondo, non perché la presentazione sia completamente nuova, ma perché il problema sottostante è reale abbastanza da non poterlo scartare immediatamente.
E onestamente, questo è raro nel mondo crypto adesso.
Dopo alcuni cicli, inizi a sviluppare una sorta di allergia alle grandi narrazioni. DeFi avrebbe dovuto ricostruire la finanza. GameFi avrebbe dovuto portare onboard il prossimo miliardo di utenti. Le terre del Metaverso avrebbero in qualche modo dovuto sostituire il settore immobiliare. Le catene modulari avrebbero dovuto risolvere i problemi di scalabilità. Ora l'AI crypto è l'ultima fase in cui ogni progetto scopre improvvisamente che è sempre stato tutto incentrato sull'intelligenza artificiale.
Quindi quando qualcosa si definisce una “blockchain IA”, il primo istinto non è l'eccitazione. È sospetto.
Leggi la frase una volta e il tuo cervello si prepara immediatamente per il solito mucchio di buzzword: intelligenza decentralizzata, agenti aperti, sovranità dei dati, infrastruttura scalabile, proprietà della comunità, allineamento degli incentivi. Tutti ingredienti familiari. Tutte parole che suonano importanti finché non chiedi cosa stia realmente accadendo sotto la superficie.
Ma OpenLedger sta almeno puntando verso un problema che conta.
L'IA ha un problema di contributo.
Non è un problema di branding. Non è un problema di token. È un problema di contributo.
Ogni sistema IA utile è costruito sui dati, conoscenze, esempi, feedback, documenti, flussi di lavoro, etichette, correzioni e esperienza di dominio di qualcun altro. Questa è la parte che le persone amano saltare. Il modello viene presentato come il prodotto, ma il modello è realmente il risultato finale di una lunga catena di input invisibili.
Qualcuno ha creato i dati. Qualcuno li ha puliti. Qualcuno li ha organizzati. Qualcuno sapeva abbastanza sull'argomento per rendere l'informazione utile. Poi l'intero processo viene assorbito in un modello, e una volta dentro, il contributo originale diventa quasi impossibile da vedere.
Questo è il strano compromesso dell'IA moderna. Tutti contribuiscono allo strato di intelligenza, ma solo poche piattaforme catturano la maggior parte del valore.
OpenLedger sta cercando di costruire attorno a quella lacuna.
L'idea di base è che dati, modelli e agenti IA non dovrebbero semplicemente fluttuare come oggetti digitali vaghi. Dovrebbero essere tracciabili. Dovrebbero avere provenienza. Dovrebbero essere connessi alle persone o alle comunità che li hanno creati. E se generano valore successivamente, dovrebbe esserci qualche meccanismo per premiare i contributori dietro di essi.
Questo suona ovvio quando lo dici lentamente. Suona anche estremamente difficile quando pensi a come funziona realmente l'IA.
Perché l'attribuzione dell'IA è complicata.
Un modello non risponde a una domanda semplicemente estraendo un file da uno scaffale. Non dice: “Questa risposta proviene per il 12% dal dataset di Ali, per l'8% da questo report di audit, e per il 3% da quel post del forum.” Almeno non naturalmente. Gli output sono plasmati dai dati di addestramento, ottimizzazione, pesi, prompt, sistemi di recupero, adattatori, e qualunque altra cosa sia stata aggiunta alla pila.
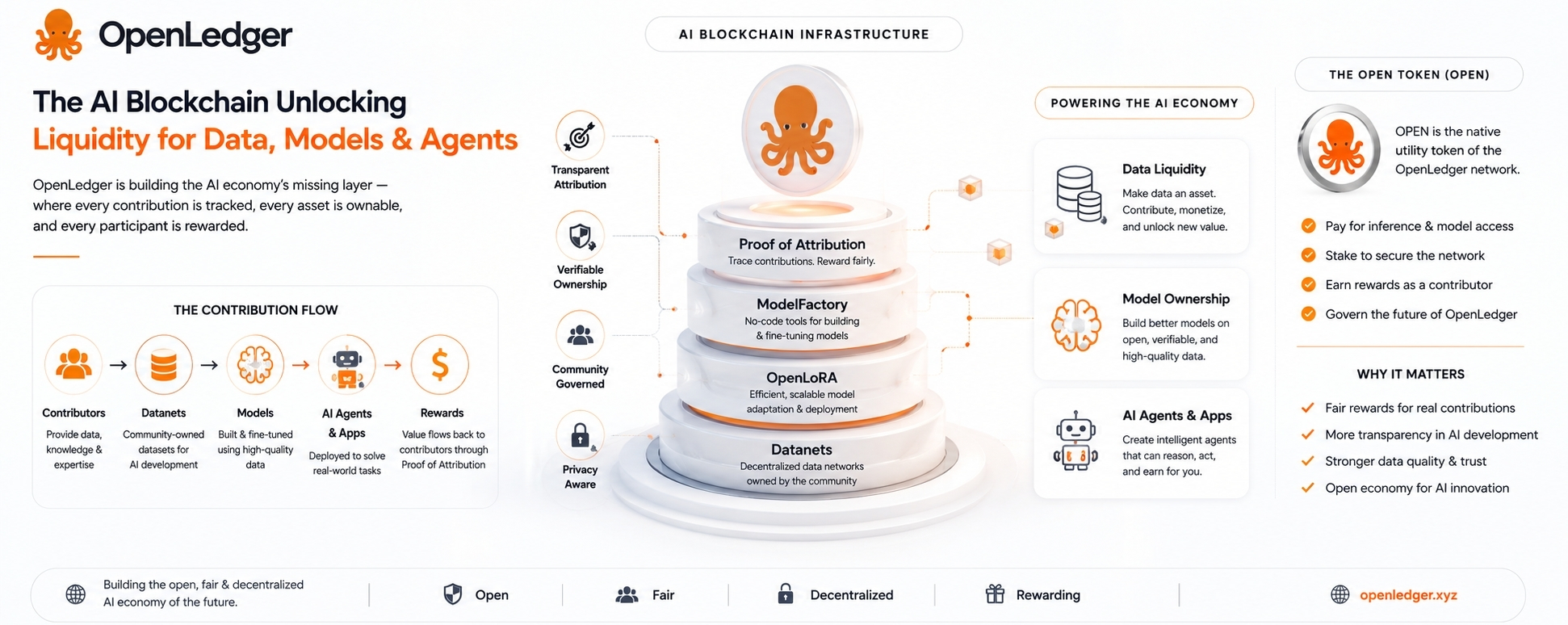
Quindi quando OpenLedger parla di Proof of Attribution, quella è la parte a cui vale la pena prestare attenzione, ma anche la parte che merita il massimo scetticismo.
L'idea è identificare quali dati hanno influenzato un output IA e premiare i contributori basandosi su quell'influenza. Se funziona, è significativo. Se diventa un vaghezza, è solo un altro sistema di punti tokenizzati con un linguaggio migliore.
Questa è la linea che OpenLedger deve seguire.
Tuttavia, l'inquadratura non è vuota. L'IA ha bisogno di uno strato di contabilità migliore. In questo momento, internet è piena di valore che i sistemi IA consumano, comprimono e monetizzano. L'output sembra pulito, ma la storia degli input è sfocata. E man mano che gli agenti IA diventano più comuni, quella sfocatura diventa un problema più grande.
Se un agente IA aiuta a auditare un contratto smart, da dove proviene la sua conoscenza sulla sicurezza?
Se un assistente al trading IA riconosce un modello, i cui dati l'hanno aiutato a insegnarlo?
Se uno strumento legale IA esamina un contratto, quali documenti hanno plasmato il suo ragionamento?
Se un assistente medico dà un suggerimento, quale conoscenza c'era dietro quella risposta?
Queste non sono più domande filosofiche. Diventano domande economiche nel momento in cui le persone iniziano a pagare per l'output.
Ecco perché i Datanets di OpenLedger sono interessanti.
Un Datanet è fondamentalmente una rete di dati di proprietà della comunità costruita attorno a un argomento o caso d'uso specifico. Invece di raccogliere silenziosamente dati da un'unica azienda centralizzata, i contributori possono aggiungere informazioni utili in uno strato di dati condiviso. Questi dati possono poi essere utilizzati per addestrare o ottimizzare modelli.
In teoria, potresti avere un Datanet per gli exploit dei contratti smart, un altro per documenti legali, un altro per flussi di lavoro sanitari, un altro per mappare i dati, un altro per l'analisi del rischio DeFi, e così via.
L'idea non è solo raccogliere dati. Tutti raccolgono dati. L'idea è mantenere un registro di chi ha contribuito cosa, poi collegare quel contributo all'uso futuro del modello.
Questa è la parte che sembra più seria rispetto al solito pitch di “IA più token”.
Perché se l'IA specializzata è realmente dove sta andando il mercato, allora i dati specializzati diventano estremamente preziosi. I modelli generali sono già abbastanza buoni per compiti ampi. La prossima battaglia non riguarda chi può far dire belle cose a un chatbot. Riguarda chi può costruire modelli che comprendono a fondo domini specifici.
Un'IA generale può spiegare il rischio dei contratti smart. Un modello specializzato addestrato su dati di exploit reali potrebbe realmente aiutare a rilevarlo.
Un'IA generale può parlare di finanza. Un modello specializzato addestrato su comportamenti di mercato strutturati e dati di rischio potrebbe diventare più utile.
Un'IA generale può riassumere contenuti sanitari. Un modello clinico specializzato, supponendo che privacy e conformità siano gestite correttamente, potrebbe fare qualcosa di molto più prezioso.
Quindi OpenLedger sta puntando a una vera tendenza: il passaggio dall'IA generale a un'intelligenza specifica per dominio.
Ma ancora, l'esecuzione conta.
Il crypto ha l'abitudine di trasformare ogni problema valido in un'economia di token eccessivamente progettata. A volte il token è essenziale. A volte è solo del nastro adesivo su un mercato che potrebbe aver funzionato senza di esso.
OPEN, il token nativo, dovrebbe stare all'interno dell'economia di OpenLedger. Può essere utilizzato per commissioni di rete, accesso ai modelli, pagamenti di inferenza, staking, governance e ricompense per i contributori. Questo ha senso strutturalmente. Se la rete viene realmente utilizzata, il token ha un ruolo.
Ma la frase “se la rete viene realmente utilizzata” sta facendo molto lavoro qui.
Un token non crea domanda semplicemente esistendo. Un mercato non diventa prezioso perché un cruscotto dice che i contributori possono guadagnare. La parte difficile è far sì che le persone contribuiscano dati di alta qualità, far sì che gli sviluppatori costruiscano modelli da quei dati, far sì che gli utenti paghino per quei modelli e assicurarsi che le ricompense fluiscano in un modo che sembri giusto piuttosto che arbitrario.
Questo è dove molti progetti crypto falliscono.
Possono progettare incentivi per la prima ondata. Possono attrarre i primi contributori. Possono far sembrare i grafici vivaci. Ma il valore a lungo termine arriva solo se il sistema produce qualcosa che la gente al di fuori del loop di incentivazione desidera realmente.
Il futuro di OpenLedger dipende da se può produrre sistemi IA utili, non solo dataset ben etichettati.
ModelFactory è parte di quel tentativo. È pensato per rendere più semplice la messa a punto, specialmente per le persone che non vogliono affrontare pesanti infrastrutture di machine learning. Questa è una buona direzione perché la maggior parte degli esperti di dominio non sono ingegneri ML.
La persona che comprende i contratti legali potrebbe non sapere come ottimizzare un modello.
Il trader che comprende la struttura di mercato potrebbe non sapere come implementare l'infrastruttura di inferenza.
Il ricercatore di sicurezza che comprende gli exploit potrebbe non voler gestire adattatori e GPU.
Se OpenLedger può facilitare a queste persone trasformare la conoscenza in asset IA utilizzabili, questo è importante.
OpenLoRA è un altro pezzo pratico. Modelli specializzati sono utili, ma eseguirli può diventare costoso. La messa a punto basata su LoRA è già uno dei percorsi più realistici per creare molte variazioni di modelli leggeri. Se OpenLedger può supportare il deployment efficiente di molti modelli ottimizzati, questo fornisce all'ecosistema una base più pratica.
Questo è dove il progetto inizia a sembrare meno un puro gioco narrativo e più un tentativo di costruire un'intera pila di produzione IA.
I dati arrivano tramite Datanets.
I modelli sono creati o ottimizzati tramite strumenti come ModelFactory.
OpenLoRA aiuta con il deployment.
Gli agenti e le applicazioni IA si trovano sopra.
La catena registra contributi, utilizzo e ricompense.
Questa è la mappa, almeno.
Se il territorio assomiglia a quello è un'altra questione.
La parte più difficile rimane l'attribuzione. È facile scrivere “Proof of Attribution” in un whitepaper. È molto più difficile far fidare i contributori che il sistema stia misurando accuratamente l'influenza. Se le ricompense sono troppo vaghe, la gente perderà interesse. Se il sistema può essere manipolato, dati di bassa qualità inonderanno. Se solo i grandi contributori ne traggono beneficio, l'angolo comunitario si indebolisce. Se l'attribuzione è troppo costosa o troppo lenta, gli sviluppatori potrebbero evitarla.
C'è anche il problema della privacy. Alcuni dei dati IA più preziosi sono sensibili. Dati sanitari, registri finanziari, materiale legale, flussi di lavoro aziendali — queste non sono cose che le persone lanciano casualmente in una rete aperta. OpenLedger avrà bisogno di forti percorsi di autorizzazione, privacy e conformità se desidera una seria adozione oltre ai dataset nativi crypto.
Poi c'è il problema di mercato. L'IA crypto è affollata. Ogni settimana c'è un'altra piattaforma di agenti, un mercato di dati, una rete di inferenza, uno strato di calcolo decentralizzato, o un protocollo di proprietà del modello. Alcuni sono riflessivi. Molti sono solo involucri narrativi. Investitori e utenti sono stanchi, anche se continuano a inseguire la prossima rotazione.
Quindi OpenLedger deve dimostrare che il suo meccanismo centrale conta davvero.
Non in teoria.
Nell'uso.
Qualcuno può costruire un modello migliore grazie a OpenLedger?
Un contributore può guadagnare perché i suoi dati hanno realmente migliorato un output?
Un sviluppatore può lanciare un agente IA più velocemente o a un costo inferiore?
Un utente può fidarsi della provenienza di ciò con cui sta interagendo?
Il sistema può attrarre dati che non sarebbero apparsi altrove?
Queste sono le domande che contano.
E forse è per questo che OpenLedger vale la pena di essere osservato senza lasciarsi trasportare.
Non è automaticamente rivoluzionario. Non è garantito che diventi il livello base della proprietà dell'IA. Non è immune ai soliti problemi crypto di speculazione, attività eccessivamente incentivata e inflazione narrativa.
Ma sta girando attorno a un problema reale.
L'IA sta creando enorme valore da input invisibili. L'attuale sistema non ha un modo giusto o trasparente per tracciare quegli input. OpenLedger sta cercando di costruire quel livello mancante utilizzando binari blockchain, logica di attribuzione e incentivi a token.
Potrebbe funzionare. Potrebbe non funzionare.
Ma il problema è abbastanza reale da meritare un tentativo più serio di una rapida bocciatura.
Il modo più chiaro di pensare a OpenLedger è questo: vuole dare all'IA una memoria economica.
Non solo memoria nel senso del modello, ma memoria del contributo. Chi ha aggiunto i dati? Chi ha plasmato il modello? Chi ha costruito l'agente? Chi merita una parte quando il sistema diventa utile?
Questa è un'idea convincente, specialmente in un mondo dove l'IA sta diventando più potente e più centralizzata allo stesso tempo.
Il scettico in me vuole ancora prove. Uso reale. Contributori reali. Modelli reali. Domanda reale. Non solo campagne, punti, emissioni di token e screenshot di partner dell'ecosistema.
Ma il ricercatore in me capisce perché questa categoria è importante.
Se la prossima fase dell'IA è costruita su dati specializzati e agenti autonomi, allora proprietà e attribuzione non sono caratteristiche marginali. Diventano infrastruttura.
OpenLedger sta scommettendo su questo.
E dopo aver letto abbastanza whitepaper da sapere quanto spesso queste cose collassano nel rumore, questo almeno lascia dietro di sé una domanda che rimane: