
The version of OpenLedger that makes the most sense to me is not "build every AI workflow here."
Its smaller than that.
More practical too.
Use OpenLedger for the part that needs provenance. Keep the rest of the workflow where it already lives.
That sounds smart. Honestly, it probably is. Nobody serious is going to rip out every existing system just because AI provenance got better. Real businesses don’t work like that. They keep the old stack. They add new layers where the pain is highest.
Fine...
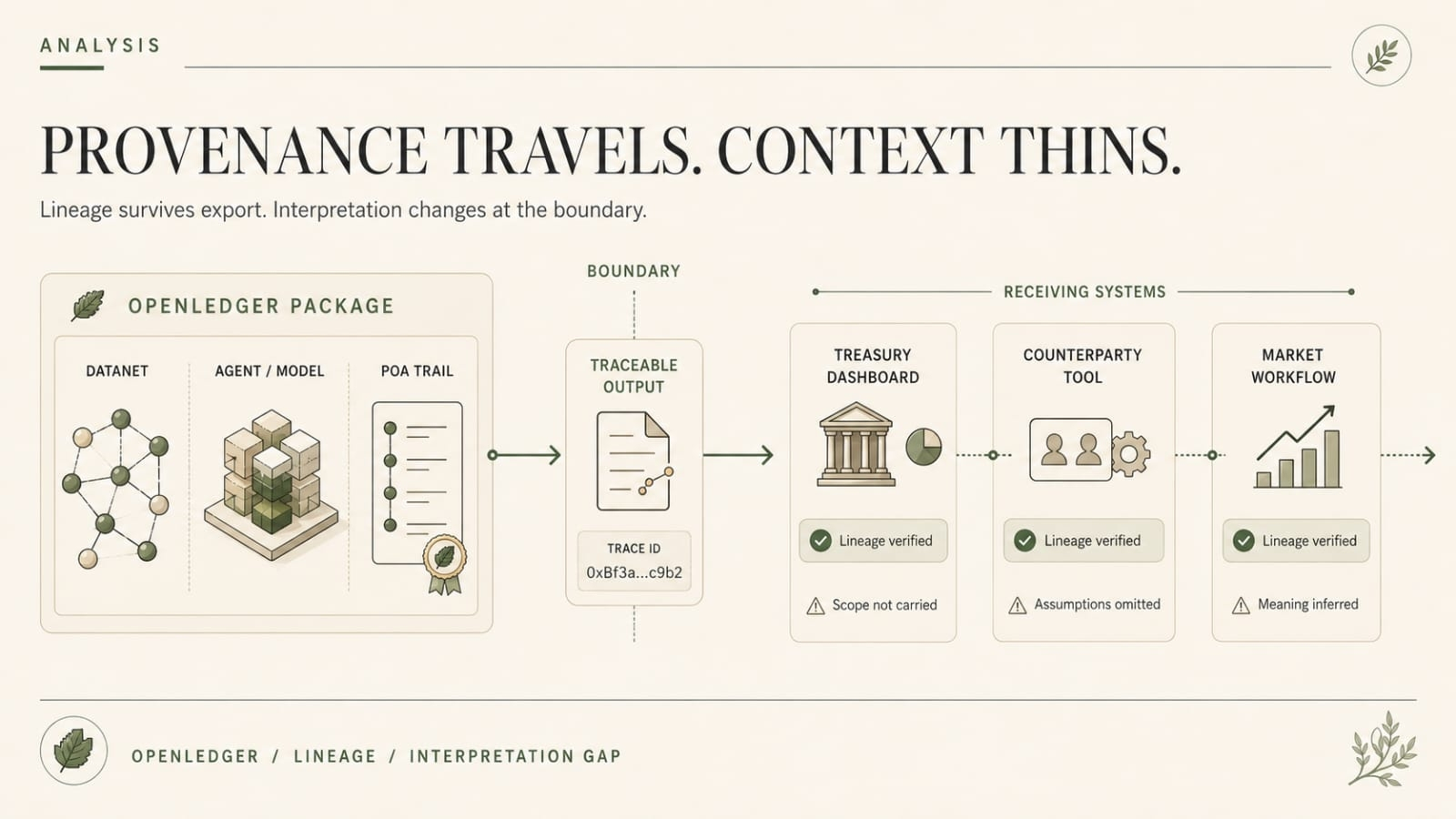
So if OpenLedger wants to matter, becoming an AI provenance and agent layer for existing workflows makes more sense than becoming a closed AI island.
But that also creates a new kind of mess.
Say one application uses OpenLedger to produce a traceable output. Maybe a Datanet-backed research agent sends a signal into a treasury dashboard. Maybe an OpenLoRA adapter output gets pulled into a marketplace ranking. Maybe a ModelFactory agent answer carries a clean PoA path and then gets treated like a go/no-go check somewhere else.
No black-box guesswork.
Just provenance, model lineage, the agent doing its job.
Everything looks clean right up until somebody asks a follow-up question the receiving system can’t answer.
Not "was the output traceable?"
Something worse.
What exactly did this output mean when you sent it to us?
Thats not theoretical either. One side can mean... this answer came from this Datanet and model path. The receiving side can quietly hear... this answer is safe enough to act on.
Those are not the same claim.
By then the route may already be open, the report already exported, the counterparty already shown the answer, or the agent already used as if lineage meant clearance.
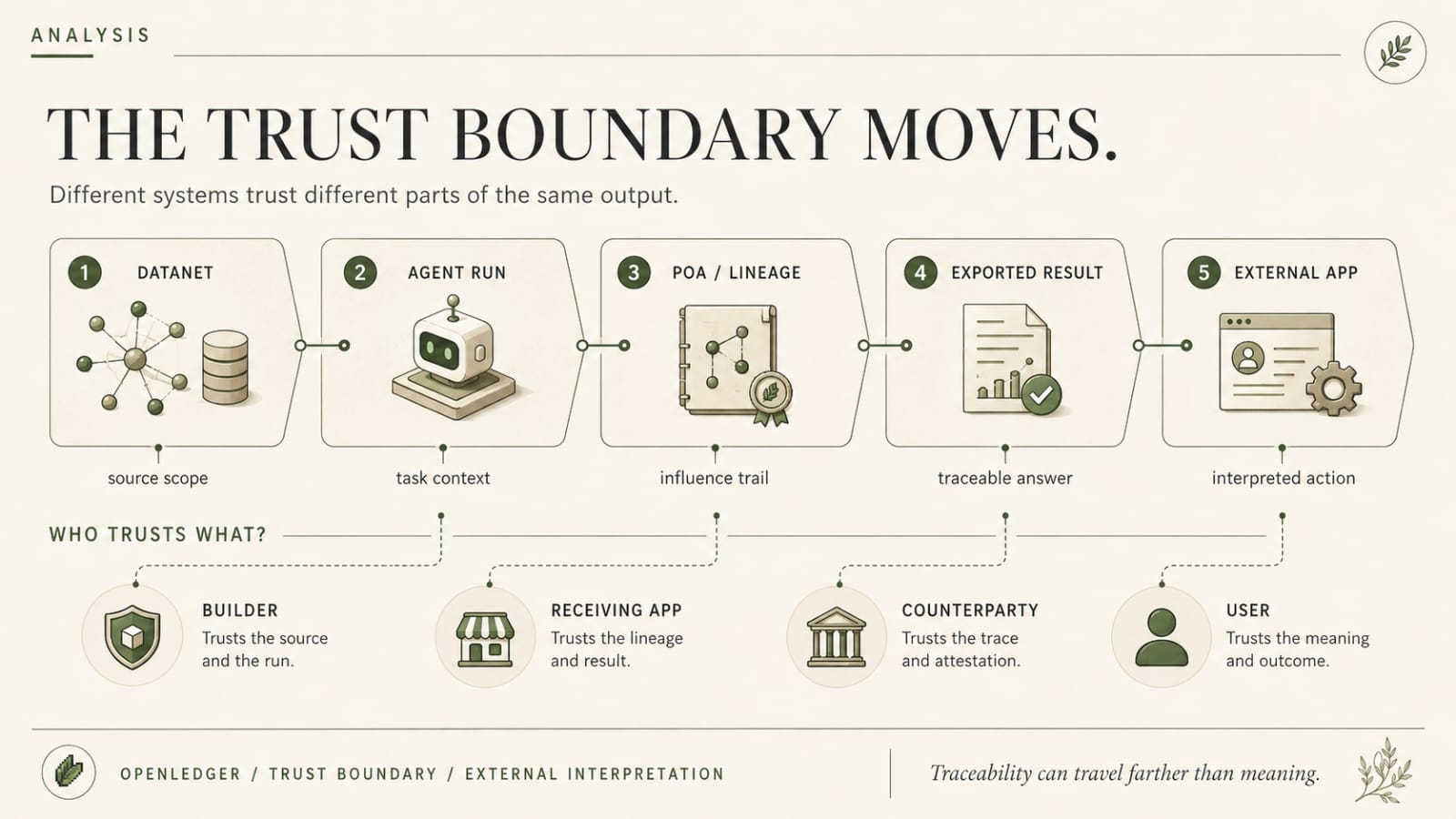
Thats where I think the trust boundary starts moving around in a way people are underestimating.
Because inside OpenLedger, maybe the assumptions were clear. The Datanet scope made sense inside the original agent. The adapter path was known inside that run. PoA traced contribution for that output. Fine.
But once that result gets routed outward, to another app, another market flow, another counterparty... interpretation starts to matter as much as verification. And interpretation is where responsibility gets slippery.
The builder says the trace only covered lineage.
The receiving app says it treated lineage as enough to proceed.
The builder says the adapter assumptions were never part of the export.
The counterparty says nobody explained the adapter assumptions well enough in the first place.
And now who owns that gap?
Lovely question.
Always arrives after something already moved.
Not PoA.
Not entirely the app.
Not entirely OpenLedger either.
Thats what makes this more serious than the usual “AI interoperability is good” conversation.
If OpenLedger pins hard as an AI provenance layer, its going to sit in the middle of workflows that already belong to other systems. At least that’s what I personally believe. Which means the hardest failures won’t always happen inside OpenLedger. They’ll happen one layer later, when a traceable output crosses into environments that only understand the result, not the full context behind it.
That is the part I'd want answered before trusting this at scale.
A closed AI app has one kind of accountability problem. A provenance layer has another. The second one is harder because every external dependency can reinterpret the edge of what was proven.
And once that starts happening, blame gets passed around fast.
The app says it only trusted OpenLedger.
OpenLedger says it only traced what it was asked to trace.
The other system says it acted on what it received.
The user is left staring at a workflow where every layer says the missing piece belongs somewhere else.
Thats not a provenance failure exactly.
Its a coordination failure made harder by provenance.
And that, to me, is where OpenLedger stops being an abstract AI thesis and starts becoming real infrastructure.
Not when people say they want traceable AI. Everybody says that.
When AI outputs start moving across system boundaries and someone has to explain why the lineage was valid, the result was accepted, and the story still doesn’t line up afterward.
Thats the part I want to see handled well.
Because if OpenLedger becomes the layer that routes AI provenance between other systems, it won’t just be judged by what it can trace.
It'll be judged by what happens when every party involved can point to a different boundary and say: we only trusted the part we were handed.