C'è una cosa nell'architettura di OpenLedger che ogni analisi menziona, ma che nessuno approfondisce abbastanza: i Datanets. La maggior parte delle descrizioni si ferma al primo livello, dove gli utenti possono contribuire dati ai Datanets e ricevere $OPEN reward quando quei dati vengono utilizzati per addestrare il modello. Questa è una descrizione corretta. Ma tralascia qualcosa di più importante: i Datanets sono un mercato a doppio senso con un meccanismo di prezzo a strati naturale che, se funziona correttamente, creerà una sorta di moat non replicabile tramite tecnologia.
Per spiegare questo, devo partire da una domanda che l'analisi originale ha posto ma non ha risposto: perché i dati specializzati diventano incredibilmente preziosi? La risposta non è "perché l'IA ha bisogno di dati" nel senso generico. La risposta risiede nella microeconomia del mercato dei dati, specificamente nel concetto di scarsità dei dati e verificabilità.
I dati non hanno sempre lo stesso valore. Un milione di tweet sul tempo ha un valore molto diverso rispetto a mille note cliniche di un oncologo scritte in 20 anni. La differenza non è solo nel volume ma è bidimensionale: scarsità, ossia se questi dati possono essere trovati altrove, e verificabilità, ossia se il ricevente ha un modo per confermare che questi dati sono autentici e di qualità. I dati su internet sono molto abbondanti e molto difficili da verificare. I dati clinici di un esperto di dominio sono molto scarsi e se attribuiti nel modo giusto, sono molto verificabili. Queste due cose insieme creano un valore economico completamente diverso, e nessun sistema nel Web2 o gran parte del Web3 attuale ha un meccanismo per valutare questa differenza.
Questo è il punto in cui il PoA di OpenLedger non è solo un meccanismo di trasparenza, ma è anche un meccanismo di pricing. Quando ogni contributo di dati viene hashato on-chain con l'identità del contributore, quando i passi di addestramento vengono registrati, e quando l'output dell'inferenza può essere tracciato a fonti di dati specifiche, il sistema crea una catena di audit sufficiente per far sì che il mercato possa auto-valutare la rarità e l'autenticità di ogni Datanet. Un Datanet contenente dati da un piccolo gruppo di esperti di dominio verificati avrà un tasso di ricompensa premium molto diverso rispetto a un Datanet contenente contenuti estratti da internet, non perché OpenLedger lo imponga, ma perché i modelli addestrati su quei dati specializzati avranno una qualità di inferenza migliore e quindi saranno utilizzati di più, generando più eventi di inferenza, e quindi ulteriori pagamenti di attribuzione.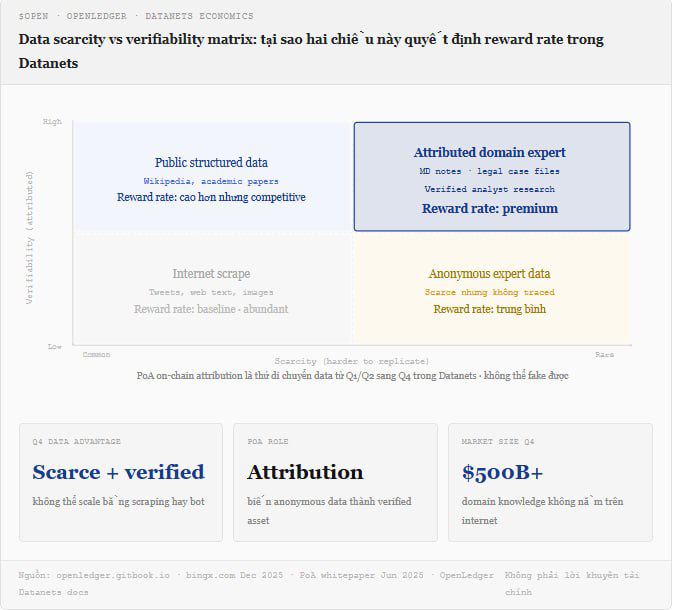
Questo è il punto in cui penso che l'analisi originale abbia ragione sulla direzione ma sottovaluti il meccanismo. L'analisi originale afferma che "non ogni settore ha bisogno di un modello IA generale di massa" e questa è una osservazione corretta. Ma perché i Datanets specializzati saranno realmente riempiti con dati di qualità invece di essere semplicemente riempiti con rumore per manipolare le ricompense? La risposta è che l'attribuzione del PoA crea una teoria dei giochi molto diversa rispetto al contributo anonimo. Quando l'identità del contributore è legata al contributo on-chain e il tasso di ricompensa del contributore dipende dalla qualità dell'inferenza dei modelli addestrati su quei dati, il contributore ha un incentivo a contribuire dati di qualità genuini piuttosto che volume. Questo è un mercato a doppio lato nel senso reale: l'offerta è rappresentata da esperti di dominio con dati di qualità, la domanda è rappresentata da sviluppatori di modelli che necessitano di addestramento specializzato, e il PoA è il meccanismo di clearing che determina il prezzo di ogni contributo basato sull'uso reale, non basato sulla qualità auto-riferita.
Voglio essere chiaro sui rischi di questo meccanismo prima di andare avanti, perché non dirlo renderebbe l'analisi non onesta. Un mercato a doppio lato funziona solo quando entrambe le parti hanno abbastanza partecipanti. Se gli sviluppatori di modelli non costruiscono abbastanza modelli sui Datanets, le ricompense di attribuzione saranno basse e gli esperti di dominio non avranno abbastanza incentivo a contribuire dati di alta qualità. Se gli esperti di dominio non contribuiscono, i modelli addestrati non saranno abbastanza buoni da attrarre gli sviluppatori di modelli. Questo è il classico problema del pollo e dell'uovo dei marketplace, e OpenLedger lo sta risolvendo bootstrapando con ricompense comunitarie dall'allocazione dei token. La domanda è se questo periodo di bootstrap sarà abbastanza lungo affinché il volano organico inizi a girare prima che le ricompense in token si esauriscano.
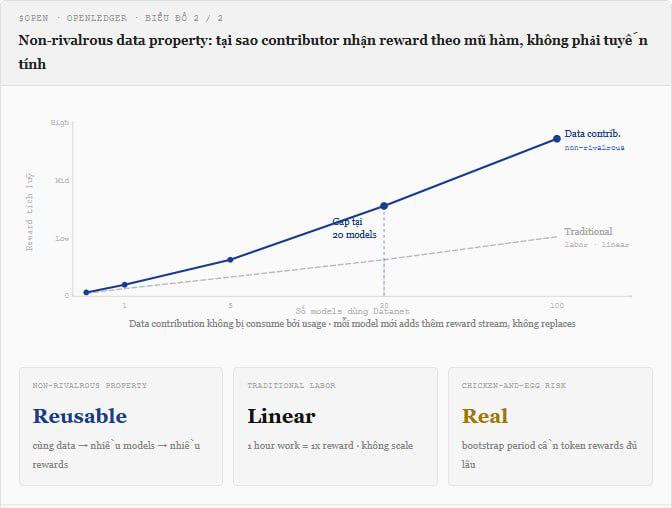
Ma ecco cosa vedo come un vero vantaggio strutturale che l'analisi originale non ha analizzato chiaramente: i Datanets hanno una proprietà che i marketplace normali non hanno, cioè i dati sono non rivali, ossia quando le note cliniche del contributore A vengono utilizzate per addestrare il modello X, non impedisce al modello Y di usare gli stessi dati. Questo significa che un Datanet di alta qualità non solo ricompensa il contributore una volta, ma lo ricompensa ogni volta che quei dati vengono inclusi in un'operazione di addestramento e ogni volta che il modello addestrato su quei dati viene utilizzato per l'inferenza. Questa è una proprietà del mercato dei dati che il mercato del lavoro tradizionale non ha: un medico può visitare solo un paziente alla volta, ma le loro note cliniche possono addestrare centinaia di modelli contemporaneamente e generare ricompense da milioni di chiamate all'inferenza in parallelo.
 L'analisi originale si conclude con la frase "almeno stanno cercando di risolvere un vero problema strutturale." Sono d'accordo con questa osservazione, ma voglio affinarla. Il problema strutturale che OpenLedger sta risolvendo non è solo "proprietà dei dati" nel senso astratto, ma la mancanza di un meccanismo di pricing per la scarsità e la verificabilità dei dati, due cose che il Web2 non ha incentivi per costruire poiché la concentrazione è il loro modello di business, e gran parte del Web3 non riesce a risolvere perché manca di un'infrastruttura di attribuzione per distinguere la qualità dal rumore.
L'analisi originale si conclude con la frase "almeno stanno cercando di risolvere un vero problema strutturale." Sono d'accordo con questa osservazione, ma voglio affinarla. Il problema strutturale che OpenLedger sta risolvendo non è solo "proprietà dei dati" nel senso astratto, ma la mancanza di un meccanismo di pricing per la scarsità e la verificabilità dei dati, due cose che il Web2 non ha incentivi per costruire poiché la concentrazione è il loro modello di business, e gran parte del Web3 non riesce a risolvere perché manca di un'infrastruttura di attribuzione per distinguere la qualità dal rumore.
I Datanets con PoA sono un tentativo di costruire quel meccanismo di pricing dall'infrastruttura. Non è un successo garantito. Il problema del pollo e dell'uovo è reale, il rischio di bootstrap è reale, e l'adozione aziendale dell'infrastruttura IA richiede più che una buona tecnologia. Ma se il mercato dell'IA specializzata è effettivamente frammentato come molti prevedono, ciò che deciderà chi vince non è il miglior modello IA ma chi ha un meccanismo di pricing per i dati specializzati sufficientemente buono da aggregare e mantenere la sua offerta nel tempo.
La domanda fondamentale è se OpenLedger può bootstrap sufficienti esperti di dominio contributor nei Datanets mentre le ricompense in token sono ancora abbastanza allettanti, affinché poi il volano organico dall'attribuzione dell'inferenza possa sostenere l'incentivo senza bisogno di sussidi in token, o se i Datanets continueranno a contenere per lo più dati di commodity dalla Q1 della matrice perché i contributori premium non vedono abbastanza motivi per passare da un contributo anonimo a un'identità attribuita on-chain.