
I keep thinking about how much of the digital world runs on invisible labor—data being produced, collected, reshaped, and reused—without most people ever really seeing where it ends up. We tap, scroll, generate logs, train systems, and somehow all of that becomes “fuel” for AI models and applications. But the uneasy part is that the value created rarely finds its way back to the source in any meaningful or transparent form.
That’s where projects like OpenLedger start to feel less like technical experiments and more like attempts to answer a deeper coordination problem. Not just “how do we build better AI systems,” but “how do we decide who gets paid, who gets access, and who gets to reuse intelligence once it exists?”
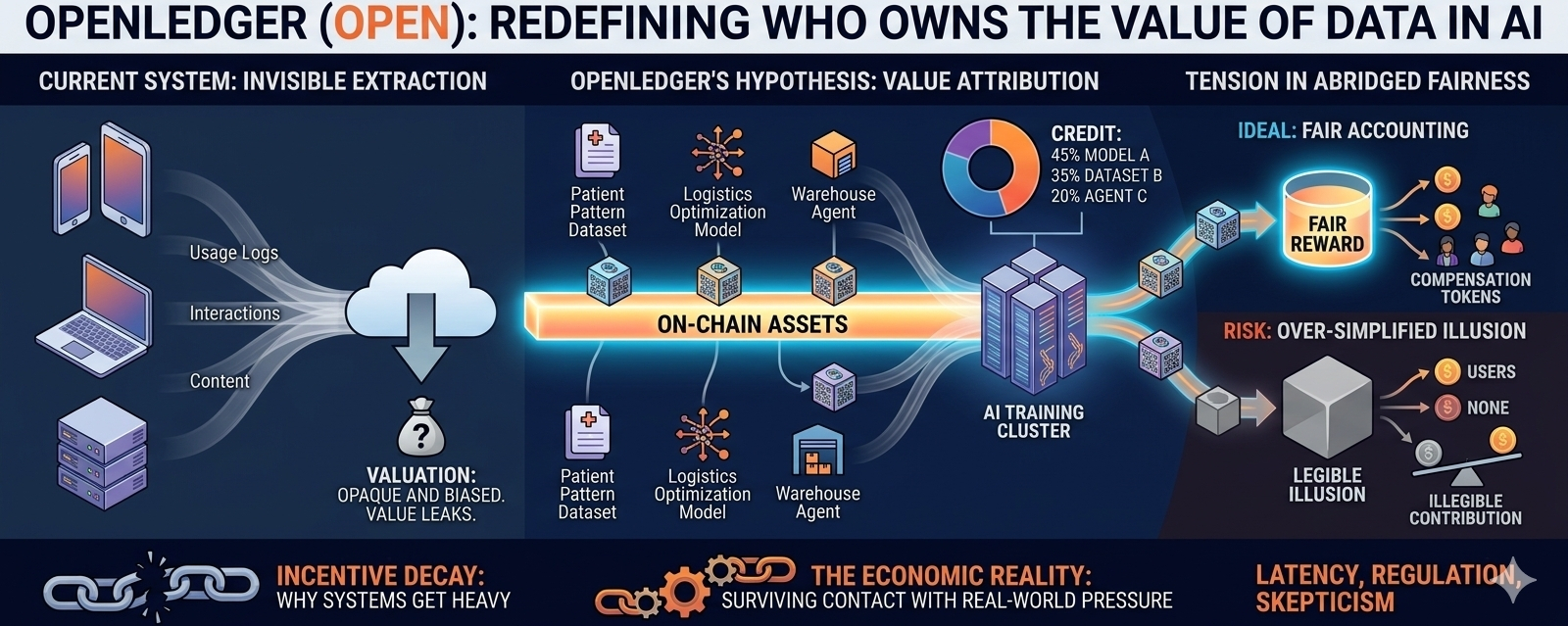
At its core, #OpenLedger is trying to address something messy: the ownership and monetization of data, models, and AI agents in a world where everything is becoming composable. On paper, it sounds elegant—turn data and models into on-chain assets so they can be tracked, licensed, and rewarded automatically. But in practice, this is not just a technical shift. It’s an economic one, and those are always harder to control than they look in whitepapers.
What makes this interesting is not the blockchain part by itself, but the attempt to make “usage” measurable in environments that are naturally chaotic. Think about a logistics network where multiple AI agents are optimizing delivery routes across warehouses, trucks, and last-mile couriers. Each model improves efficiency, each dataset refines predictions. But who exactly contributed what? And if a hospital uses an AI model trained partly on anonymized patient patterns from thousands of clinics, how do you fairly distribute credit—or cost—across all those invisible inputs?
OpenLedger is essentially betting that these questions can be partially structured. That instead of letting value leak through the system unnoticed, you can turn participation into something trackable and programmable.
But there’s a tension here that’s hard to ignore.
The moment you try to formalize contribution in complex systems, you also risk oversimplifying it. Data is not always cleanly attributable. Models don’t always behave in predictable lineage trees. Even AI agents evolve through interaction, not isolation. So the question becomes: are we building a fair accounting system, or just a more legible illusion of fairness?
Still, it’s hard to dismiss the need for something better than today’s situation. Right now, most data providers—whether they are users, companies, or devices—operate in systems where value flows upward but visibility flows downward. You contribute to intelligence you will likely never see again. That imbalance is exactly what projects like @OpenLedger are trying to challenge.
If you imagine a robotics fleet in a warehouse—hundreds of autonomous machines coordinating inventory, picking items, adjusting routes in real time—the coordination layer becomes incredibly valuable. Every decision is shaped by models trained on prior data, simulations, and shared learning across systems. If OpenLedger’s approach works, it could allow each contributing dataset or model update to be recorded, traced, and compensated in a way that doesn’t rely purely on centralized platform control.
But even in that scenario, a practical concern remains: will anyone actually want that level of complexity in production systems? Most engineers prefer reliability over philosophical completeness. Most businesses prefer systems that “just work,” even if they are not perfectly fair under the hood.
So the real test for OpenLedger is not whether it can design an elegant incentive structure, but whether that structure can survive contact with real-world pressure—latency constraints, regulatory uncertainty, enterprise skepticism, and the simple human tendency to ignore systems that feel too heavy to maintain.
There’s something almost paradoxical about it. The more you try to make value attribution precise, the more you risk making the system harder to adopt. But the more you simplify it, the closer you get back to the original problem of invisible extraction.
Maybe that is the uncomfortable space OpenLedger is operating in—not promising a perfect solution, but forcing a conversation that most AI infrastructure quietly avoids.
And perhaps that’s the real significance here: not the claim that data can finally be perfectly monetized, but the reminder that every AI system we build is also an economic system in disguise, deciding—silently—who gets recognized and who gets left out.

