Look, I understand why projects like OpenLedger suddenly sound attractive.
Artificial intelligence is booming. Crypto has been searching desperately for a believable story since the last speculative cycle imploded. Put the two together and suddenly every investor deck starts sounding like the future of civilization. AI plus blockchain. Decentralized intelligence. Data ownership. Fair attribution. Shared economies.
It sounds tidy. On paper, at least.
But I’ve seen this movie before.
Every few years, Silicon Valley and crypto circles rediscover the same basic fantasy: that technology can somehow remove messy human trust from complicated systems by adding another technical layer on top. Usually a token appears somewhere in the middle. Then venture capital arrives. Then the white papers get longer. Then the explanations become harder to follow precisely because the underlying economics do not work cleanly in the real world.
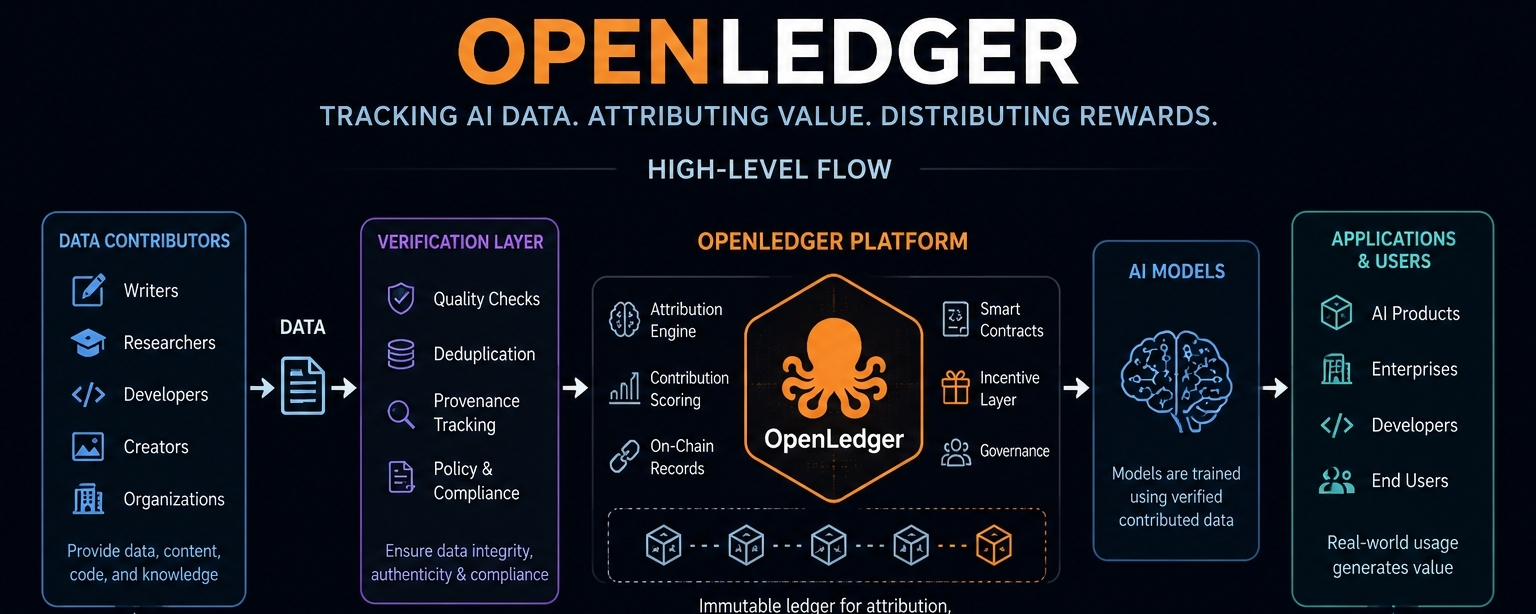
OpenLedger is the latest version of that cycle.
The pitch goes something like this: AI companies use massive amounts of data. The people supplying that data rarely get compensated. OpenLedger wants to track who contributed what, measure how valuable that contribution was, and distribute rewards through blockchain infrastructure.
Simple enough.
Except it really isn’t.
The core problem they claim to fix is real. That part matters. Modern AI systems are built on oceans of scraped information pulled from websites, forums, code repositories, articles, research archives, videos, and public conversations. Companies train giant models on all of it, package the outputs into products, and generate billions in value while the original contributors receive nothing.
That imbalance is becoming impossible to ignore.
Artists are suing AI firms. Publishers are furious. Software developers are watching code-generation systems train on years of unpaid labor. Even regulators are starting to ask uncomfortable questions about ownership, attribution, and consent.
So OpenLedger steps into the room claiming it can solve this through blockchain accounting.
And this is where my skepticism kicks in hard.
Because the second someone says they can “accurately track contribution” inside a modern AI model, alarms should start ringing.
Let’s be honest. The AI industry itself barely understands how these systems make decisions. Large language models are statistical black boxes trained on absurd quantities of data. Even the engineers building them struggle to explain why a model produces one answer instead of another. Researchers still argue about interpretability because the internal mechanics remain deeply opaque.
Now OpenLedger comes along saying it can not only trace contributions across these systems but also assign economic value to them.
That is an enormous claim.
And the marketing skips past the ugly part.
How exactly do you determine that one paragraph from a forum post contributed 0.00003% of a model’s intelligence? How do you separate one contributor’s influence from millions of overlapping data points compressed into neural weights? What happens when datasets conflict? Or when synthetic data contaminates the system? Or when contributors game the incentives by flooding the network with garbage?
Because they absolutely will.
Crypto incentives always attract farming behavior. Always.
I watched this happen with play-to-earn gaming. I watched it happen with NFT ecosystems. I watched it happen with decentralized storage networks where people optimized rewards instead of usefulness. Once tokens become attached to contribution systems, the system starts attracting people who care less about quality and more about extraction.
That is human nature. Not a bug. A certainty.
And OpenLedger adds another complication on top of an already unstable industry. AI infrastructure is expensive enough without inserting blockchain coordination into the middle of it.
Think about the stack here for a second.
AI models already require massive compute infrastructure, expensive GPUs, high energy consumption, complicated training pipelines, and constant optimization. Now add decentralized verification, token economics, validators, attribution mechanisms, staking systems, governance layers, and blockchain settlement.
At some point you have to ask a basic question.
Does this make the system better?
Or just heavier?
Because complexity has a cost. Operationally. Financially. Legally.
That part rarely makes it into the glossy diagrams.
The other thing that bothers me is the quiet centralization hiding underneath the decentralization narrative.
OpenLedger talks heavily about distributed contribution networks and shared AI economies. Fine. But who actually controls development? Who defines attribution standards? Who maintains the protocol upgrades? Who owns large portions of the token supply? Who benefits most if the token price rises?
Follow the incentives.
Early investors usually get in cheap. Founders receive large allocations. Venture firms secure strategic positions before retail users even understand the system exists. Then the project talks about “community ownership” while insiders sit on massive percentages of supply.
Again. I’ve seen this movie before.
Crypto projects love using decentralization as branding while relying heavily on centralized leadership structures behind the scenes. And to be fair, that may even be necessary. Building infrastructure requires coordination. The problem is that the rhetoric often drifts very far from reality.
Then there’s the regulatory issue lurking underneath everything.
OpenLedger’s entire model depends on tracking data provenance and economic ownership relationships across borders. That sounds manageable until lawyers enter the room. Suddenly you run into copyright law, privacy regulations, AI governance frameworks, securities questions, and cross-jurisdictional compliance nightmares.
And blockchains are terrible at ambiguity.
That is the uncomfortable truth nobody likes discussing. Legal systems operate through flexibility, reversibility, negotiation, and human judgment. Blockchains operate through permanence and automation. Those two worlds collide constantly.
What happens when copyrighted material enters the network? What happens when attribution calculations are disputed? What happens when regulators decide the token resembles an unregistered security? What happens when enterprises realize they may be exposing proprietary training pipelines through transparent infrastructure?
The marketing decks rarely linger there.
Because the catch is bigger than the technology itself.
The catch is that OpenLedger assumes the AI industry wants openness at the exact moment the industry is becoming more secretive, more competitive, and more centralized.
Large AI companies guard their datasets aggressively because those datasets are strategic assets. Their training methods matter. Their model optimizations matter. Their infrastructure matters. These firms are locked in an arms race measured in billions of dollars.
OpenLedger is effectively asking them to adopt systems built around transparency, shared attribution, and decentralized coordination.
Maybe parts of the industry eventually will. Particularly in regulated sectors where auditability matters. Healthcare perhaps. Financial systems maybe. Industrial compliance environments. But the broader AI race right now is driven by speed and competitive advantage, not ideological openness.
That tension matters more than most people realize.
And there’s another uncomfortable possibility here. The real product may not be the infrastructure at all. It may simply be the token narrative surrounding the infrastructure.
Because crypto markets are very good at monetizing future possibilities long before those possibilities become economically useful. Investors buy stories. Traders buy momentum. Communities form around speculative belief systems remarkably quickly.
Meanwhile the underlying systems often remain unfinished, underused, or commercially unproven.
That does not mean OpenLedger is fraudulent. Important distinction. The problem is subtler than that. A project can be technically serious and still economically unrealistic. It can solve a real problem while introducing five new ones. It can attract intelligent developers and still fail because human systems do not behave the way protocol designers expect them to.
Technology history is full of graveyards filled with brilliant architectures nobody actually needed badly enough.
And right now, that feels like the uncomfortable question hanging over OpenLedger.
Not whether the idea sounds smart.
Whether the real world is willing to absorb the cost, friction, and complexity required to make it matter at scale.