The upload didn’t fail. That was the uncomfortable part.
The files went through. The structure held. The Datanet accepted the contribution without drama. No missing format warning. No broken schema. No obvious rejection from the workflow.
From the outside, this looked like a clean start.
Data submitted. Contributor record created. Domain context attached. The raw material now had a place to sit inside OpenLedger instead of disappearing into another private folder, another research archive, another lab pipeline where useful data becomes useful only after someone else absorbs it.
But then the question came later.
“Where does this data go now?”
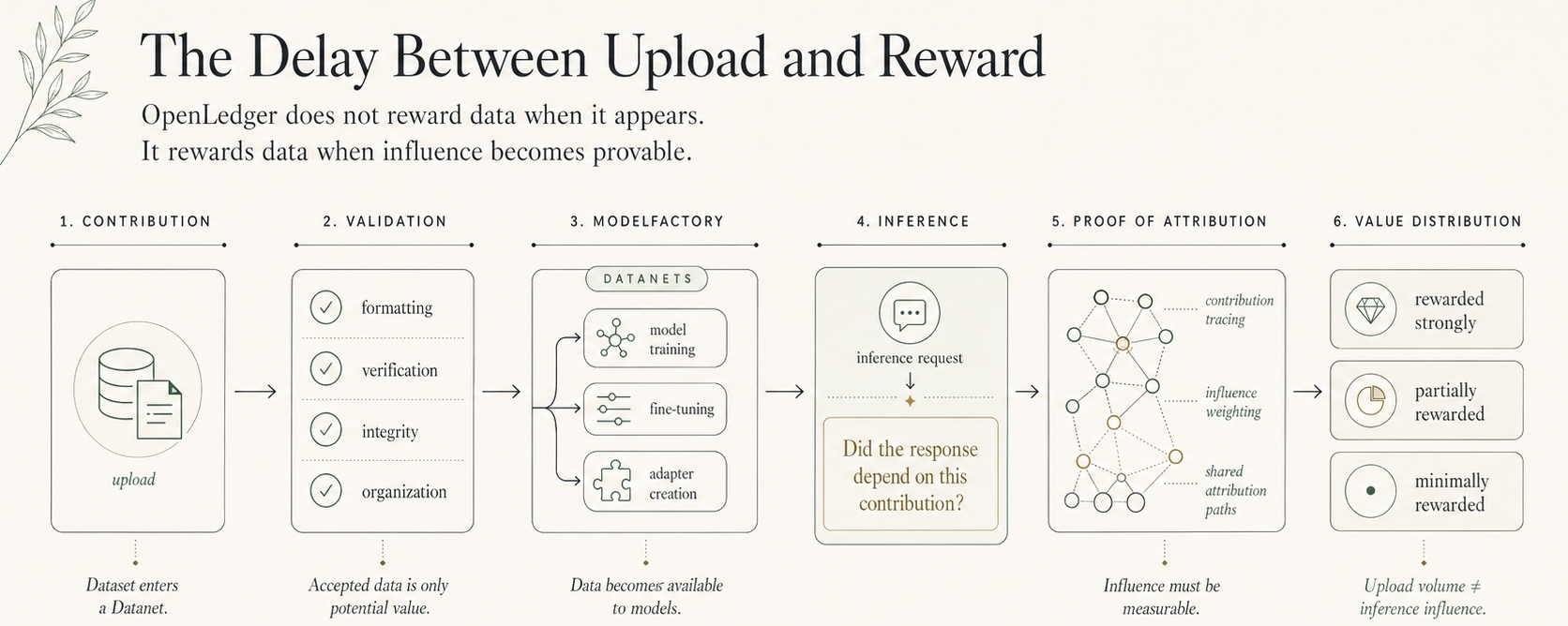
Not technically. Technically, it had gone somewhere. It had entered a Datanet. It had a protocol-native route, a contributor trail, a position inside a system built for AI data liquidity. That part was clear enough.
The harder question was economic.
Who finds it?
Who trains on it?
Which model needs it badly enough for the contribution to matter beyond storage?
I stared at the flow longer than I expected. The data was no longer completely raw. That mattered. It had crossed the first boundary. On OpenLedger, a Datanet is not just a container for files. It is where domain data starts gaining an identity before the model improves, before the agent acts, before an inference event creates visible demand.
That was my first wrong read.
I thought the important moment would come later. ModelFactory training. Agent usage. OPEN rewards landing after the data had already proven itself in a live workflow. The cleaner story starts there because revenue is easier to notice after something answers.
But the pressure begins earlier.
It starts at origination.
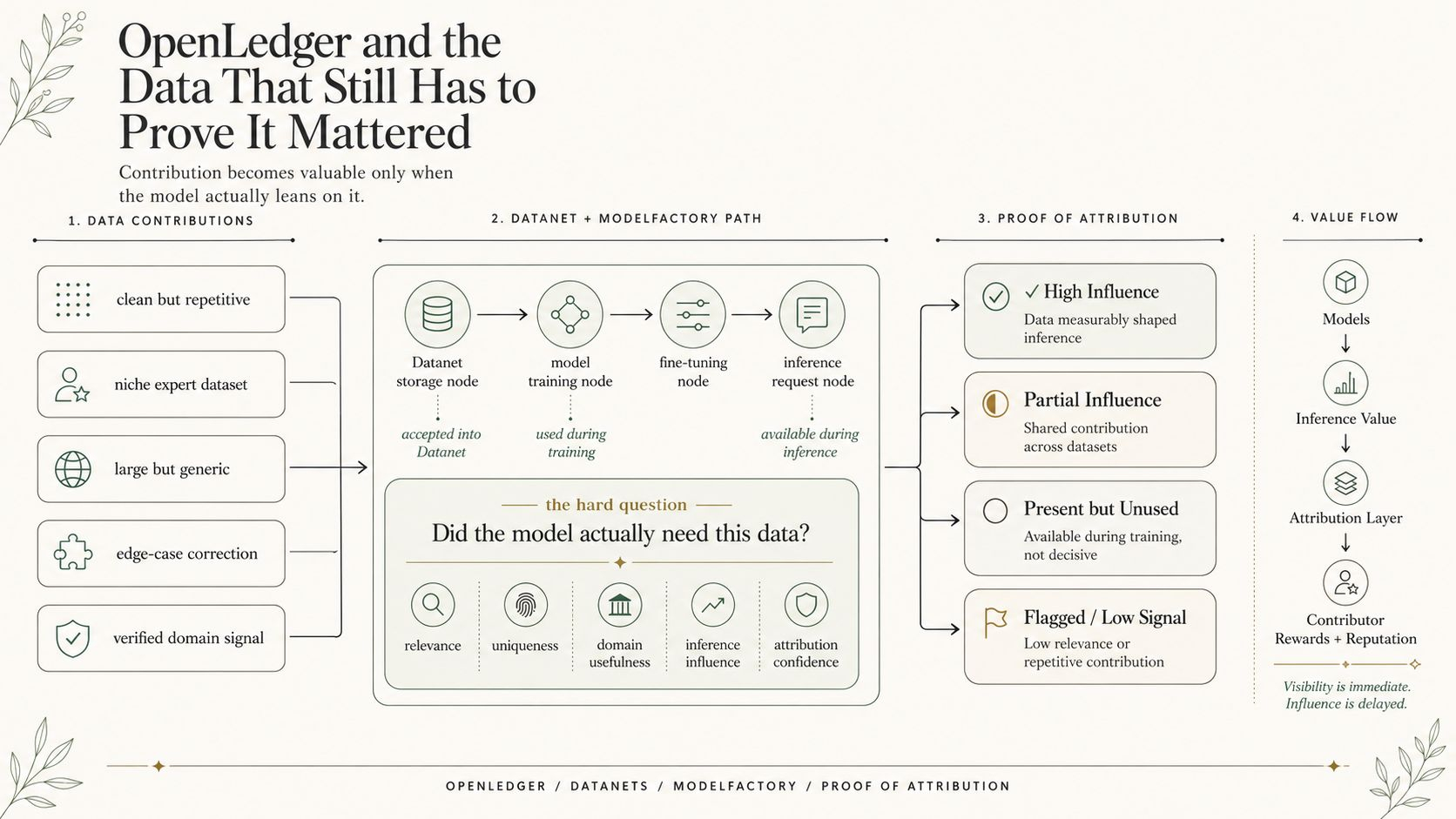
Most useful data lives in a strange dead zone before training. It may be valuable, but not liquid. It may improve a model, but not yet be priced. It may belong to contributors who understand the domain better than anyone else, but the system around them usually has no clean way to keep that contribution visible once the data enters someone else’s AI stack.
That is where a Datanet changes the route.
Not by magically making every dataset valuable. That would be too easy. Bad data can still be bad data. Redundant data can still sit there doing nothing. A contributor record does not guarantee demand.
But it does change the starting condition.
The data is no longer just “uploaded.” It is originated.
There is a difference.
An upload waits for someone to remember it exists. Origination gives the data a structured entry point into future model demand. It creates a trail before training begins, so that if the data later improves a model, supports an agent, or shapes an inference path, the contributor is not erased from the economic story.
That sounds small until you compare it with the normal AI pipeline.
In the old route, raw data gets collected first and valued later, usually by the party powerful enough to centralize it. Contributors see the request, the submission, maybe the one-time payment, and then the asset vanishes into a training process they cannot inspect. If the model becomes useful, the upside moves away from the origin.
OpenLedger pushes against that leakage at the first step.
The Datanet becomes the place where training data starts carrying memory. Not human memory. Economic memory. A record of where it came from, what domain it belongs to, and how it can later connect into model creation, agent execution, and OPEN-linked reward flows.
That is why the first liquidity event is not the model answer.
It is the moment raw data gets structured enough to become reusable.
I didn’t like that conclusion at first because it feels less exciting than the agent doing something on-chain. No visible execution. No dramatic output. No trade, no automation, no final answer to point at.
Just a dataset entering a rail.
But maybe that is exactly the part most people miss.
AI markets do not only fail at the model layer. They fail earlier, when valuable inputs have no native path into demand. Data sits outside pricing. Contributors sit outside attribution. Models improve later, and nobody can cleanly explain which origin points helped create that improvement.
On OpenLedger, the Datanet is where that path starts tightening.
A contributor is not only giving the system files. They are placing data into an AI Blockchain environment where usefulness can be tracked forward instead of forgotten backward. If that data later feeds ModelFactory, improves a specialized model, or becomes part of an agent workflow, the original contribution has a better chance of remaining economically attached to the outcome.
Not perfectly. Not automatically. Demand still has to arrive.
That is the part I kept circling back to.
A Datanet can give data identity, but the market still has to test whether the data deserves liquidity. Structure is not the same as value. Contributor records are not the same as usage. OPEN rewards only become meaningful when the data actually moves into model or agent demand.
And that is where OpenLedger’s origination layer becomes interesting.
It does not treat raw data as valuable because someone uploaded it.
It gives the data a route where value can be discovered, reused, measured, and eventually rewarded if the contribution proves useful inside the AI economy.
The upload had worked.
The record existed.
The Datanet was live.
But the real question had only started.
Not “was the data accepted?”
That was already answered.
The harder question was whether the data could become liquid enough to matter after origination, when a model, an agent, or an inference path finally needed what the contributor had placed there first.
