Been going through openledger’s architecture, mostly around the data attribution and contributor incentive side. at first glance it is easy to throw it into the “ai + crypto token” bucket, but that feels a bit too simple.
Most people think openledger is just another ai infrastructure project with a token attached. maybe partly true, but the more interesting part is the coordination layer underneath: who supplies useful data, who verifies it, who uses it in models, and how value gets routed back through the network.
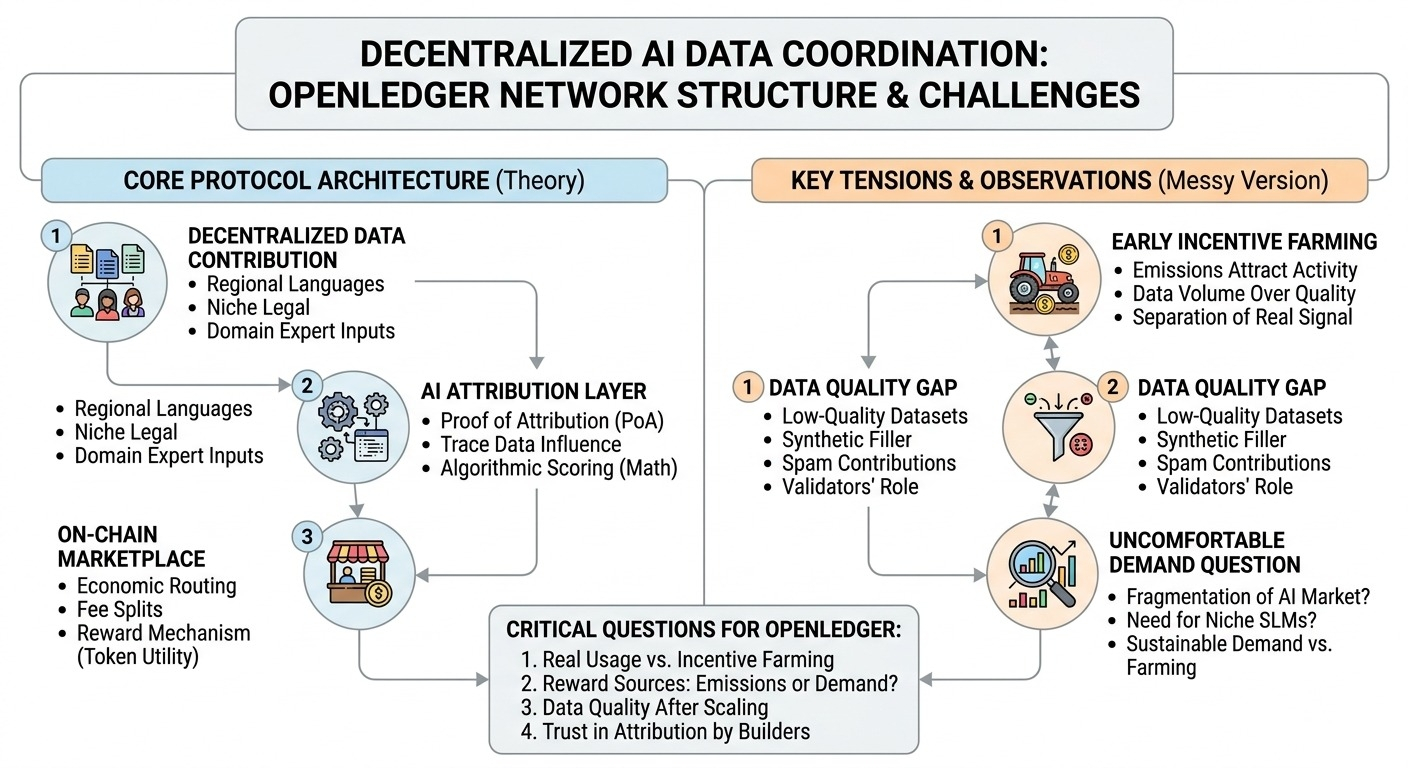
What caught my attention is the decentralized data contribution model. openledger seems to be aiming at a world where contributors can provide datasets, feedback, annotations, or domain-specific inputs that ai models can actually use. in theory, this could matter for data that centralized platforms do not easily capture: regional language samples, niche legal documents, industry-specific labels, or small expert datasets.
But the contribution layer is only useful if the attribution layer works.
And this is the part i keep thinking about: ai attribution is not like tracking a transaction. if someone contributes 5,000 annotated insurance claims, and a model later performs better on claims analysis, how do you know how much of that improvement came from that dataset? was it volume, uniqueness, formatting, validation, or just overlap with existing training data?
Openledger’s reward mechanism seems to depend on answering that question well enough that contributors believe the system is fair. not perfectly fair, because that is probably impossible, but fair enough to keep high-quality contributors engaged.
The marketplace side adds another layer. Ideally, data contributors, model developers, validators, and users all interact through some kind of on-chain economic routing. model developers pay for useful inputs or access, users create demand through inference or applications, and contributors earn based on verified impact.
That is the clean version.
The messy version is that early token rewards attract activity before real demand exists. people upload data because rewards are available, not because model developers are actively paying for it. then the network has to separate real signal from farming behavior, which is hard. low-quality datasets, duplicated uploads, synthetic filler, and spam contributions become rational if the scoring system can be gamed.
Honestly, this is where the long-term design ets interesting. the protocol has to avoid becoming just a reward machine for data volume. it needs verification, quality scoring, provenance checks, and maybe some way to measure downstream model usefulness. but every added filter introduces complexity, and possibly centralization pressure.
Who actually creates value here? the data contributor? the validator who filters bad inputs? the model builder who turns data into usable outputs? the user whose demand creates fees? probably all of them, but the reward split has to stay believable over time.
The biggest assumption is that ai demand becomes fragmented enough to need this kind of network. if most valuable ai systems remain closed and vertically integrated, decentralized data coordination might stay niche. but if smaller specialized models need external, attributable, high-quality data, openledger’s design starts to make more sense.
watching:
* real model usage versus incentive farming
* contributor reward sources: emissions or actual demand
* quality of data after incentives scale
* whether attribution remains trusted by serious builders
No perfect conclusion yet. openledger might be building a sustainable coordination layer for ai data markets, or it might be testing whether token incentives can pull demand into existence before the demand is really there.