
Something has been bothering me about the way people talk about AI infrastructure lately.
Every discussion somehow ends up at the same place. Compute. Chips. Inference costs. Model size. Speed. Fine. Those matter. Obviously. But markets have a weird habit of obsessing over the thing that is easiest to measure while quietly ignoring the thing that becomes economically painful later.
I have seen this before in crypto.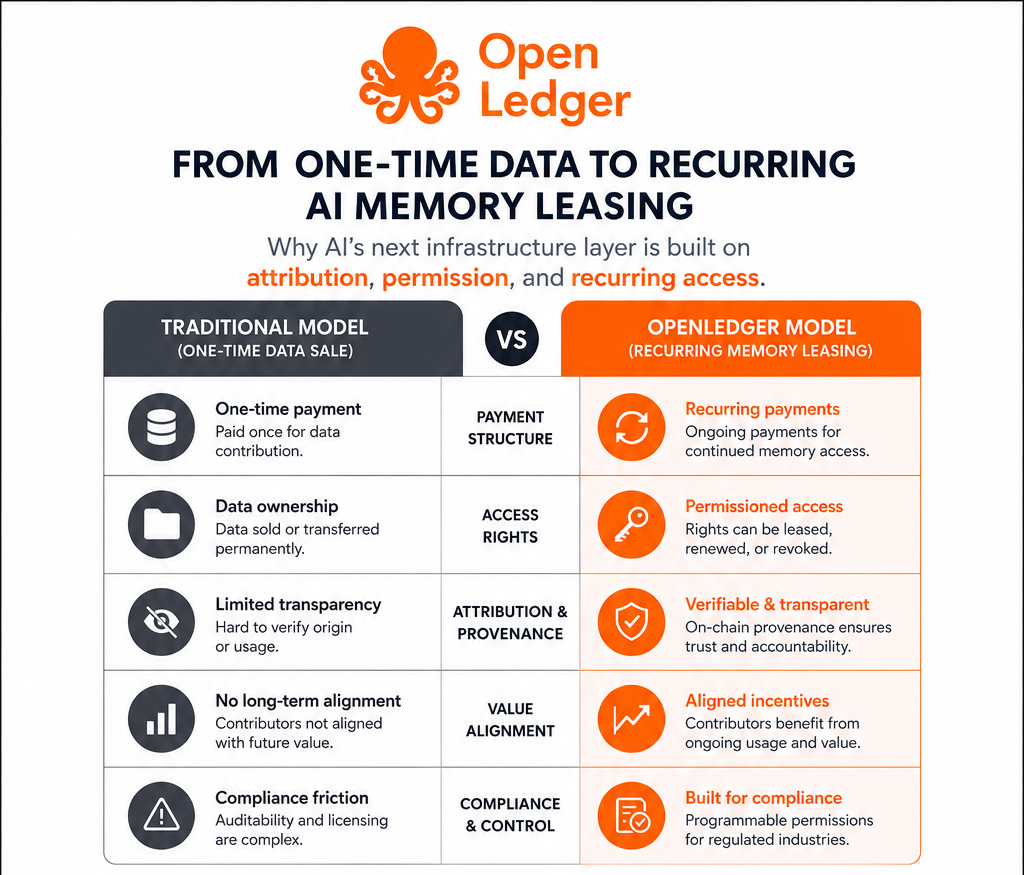
Back when people treated blockspace like the only story that mattered, almost nobody spent enough time asking who would actually pay continuously for trust coordination. Everyone loved throughput charts. Much fewer cared about recurring settlement behavior. Then eventually the conversation matured.
AI feels similar right now.
The strange part is that most people still think about AI data like a one-time fuel source. Feed model. Train model. Reward contributor. Move on. Clean story. Very internet-native logic. Content goes in, intelligence comes out.
But the more I think about it, the less realistic that model feels.
Because useful AI is not behaving like disposable software anymore.
If an enterprise model learns internal compliance workflows, proprietary research methods, negotiation logic, customer decision trees, or domain-specific operational habits, what exactly happened economically? Did the company buy information? License capability? Rent behavior?
That distinction sounds semantic until money gets involved.
A simple example makes this easier.
Imagine a hospital licenses structured clinical protocols into an AI workflow assistant. Not public medical facts. Their internal decision logic. Escalation patterns. Edge-case judgment rules developed over years.
Now six months later that assistant is deeply integrated into operations.
Question: was that knowledge sold once?
Or is the hospital effectively leasing economically useful memory?
I think this is where the conversation gets uncomfortable.
Because AI does not behave like a PDF archive.
Once knowledge becomes embedded into machine behavior, it becomes harder to think in clean ownership language. The system is not "accessing a file" in the traditional sense. It is expressing learned behavior shaped by prior information exposure.
That is messier.
Law gets weird here too.
Copyright works reasonably well when copying is visible. Licensing works when access boundaries are clear. SaaS contracts make sense when vendors and customers are identifiable. AI breaks those assumptions in annoying ways.
And if autonomous agents become real economic participants, honestly, things get even stranger.
Because then memory is not just passive storage.
It becomes operational infrastructure.
A trading agent remembers execution preferences. A legal agent remembers contract review heuristics. A supply chain agent remembers vendor risk logic. A compliance agent remembers escalation triggers.
That memory is producing value repeatedly.
Which keeps pulling me back to a very simple question.
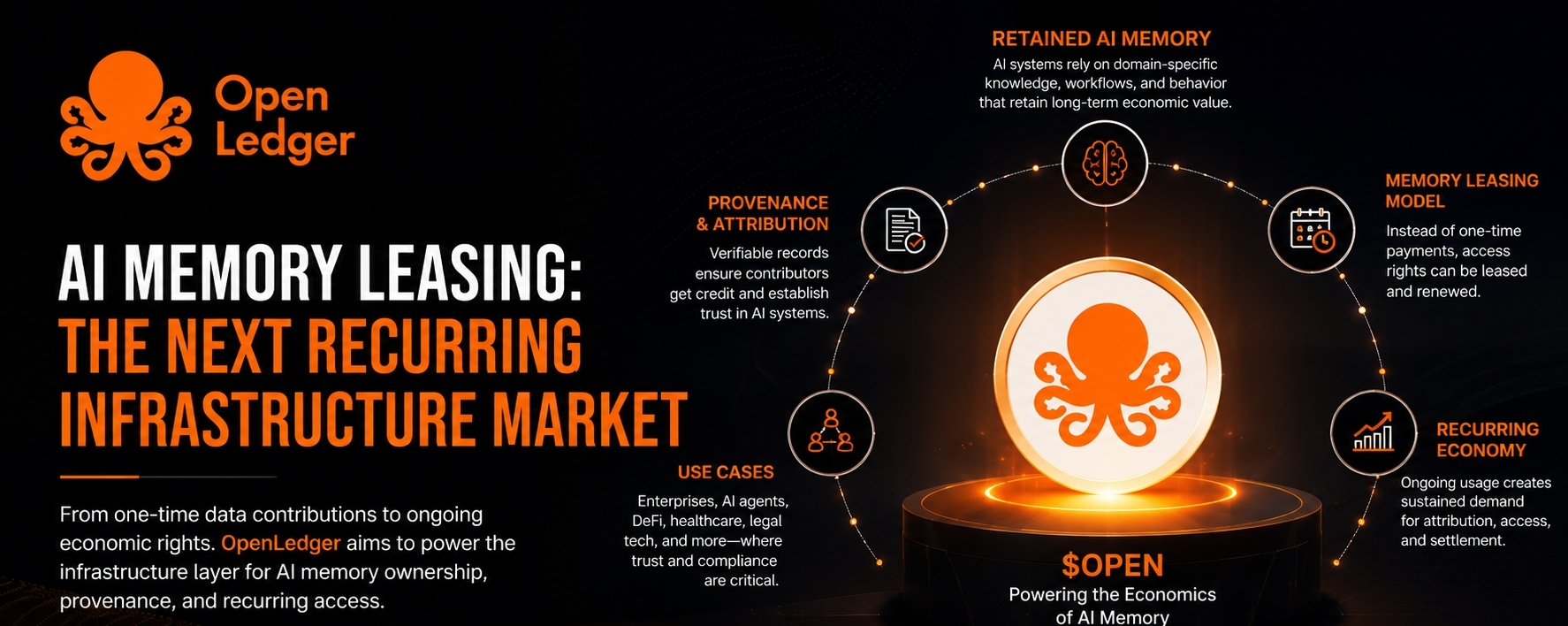
Why would recurring economic output be priced as a one-time event?
That logic feels broken.
This is where OpenLedger started looking different to me.
Most commentary around OpenLedger focuses on attribution. Provenance. Data contribution. AI accountability. Those are fair descriptions, but they still feel surface-level to me.
Attribution alone is not the business model.
Plenty of systems can record who contributed something. A database can do that. Paperwork can do that. Even a mediocre enterprise dashboard can fake enough of it for internal compliance.
The harder question is whether attribution changes economic behavior.
That is the real dividing line.
Because if attribution becomes part of permission enforcement, then something more interesting happens. Now the issue is not simply "who helped train this model?" It becomes "what economic rights remain active because that contribution still matters?"
Different question entirely.
And honestly, much bigger.
I keep thinking about music licensing because people understand that instinctively. A song played once in your headphones is one thing. A song repeatedly broadcast commercially creates a different economic relationship.
AI memory might end up working closer to that than people expect.
Not identical. Definitely not legally identical. But economically? Similar tension.
Persistent use changes pricing logic.
If OpenLedger can help create infrastructure where machine memory retains verifiable economic lineage, then $OPEN might be connected to a recurring permissions market instead of a one-off contributor rewards narrative.
That would matter.
Crypto infrastructure tends to become strongest when it monetizes dependency, not activity spikes.
Validators get paid because trust needs maintenance. Oracles get paid because data freshness matters repeatedly. Settlement layers work because finality is not a one-time event.
Recurring dependency creates durable economics.
But I am not fully convinced yet.
The biggest problem is enforcement.
This is always where elegant infrastructure ideas hit reality.
What stops developers from simply ignoring attribution rails if integration creates cost and competitors move faster without them?
That is not a theoretical concern. Markets route around friction all the time.
Then there is the uglier technical question.
Can you actually isolate machine memory cleanly enough to lease it?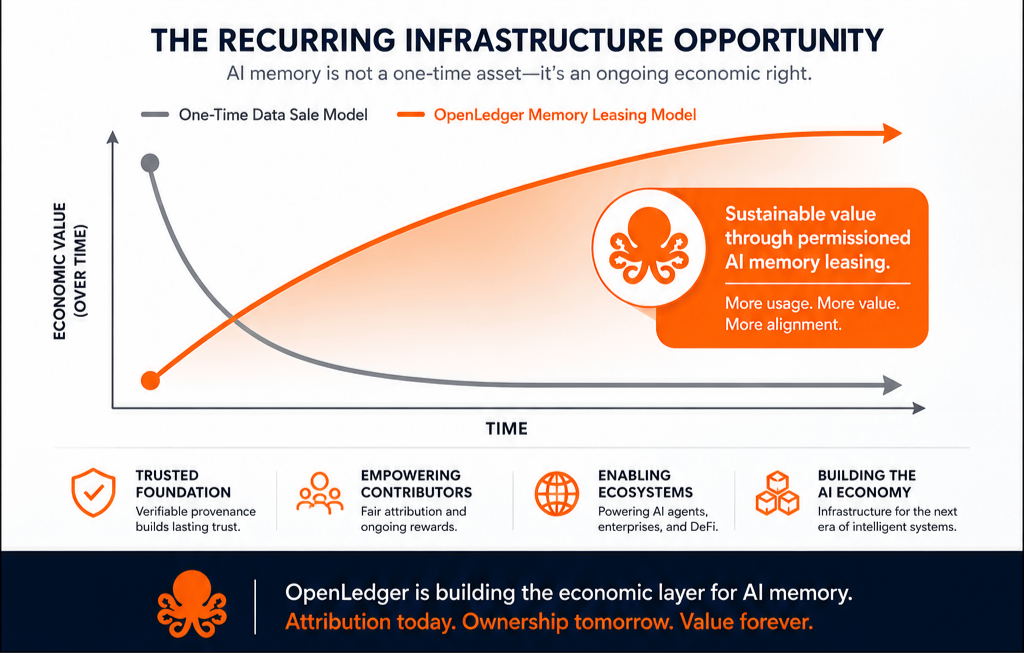
Human language makes this sound easier than it is. Models do not store knowledge in neat folders labeled "licensed protocol" and "unlicensed behavior." Learned patterns blur together. Weight changes compound. Attribution becomes probabilistic.
That makes recurring enforcement difficult.
And still.
Even with all that uncertainty, I cannot shake the feeling that people are looking slightly in the wrong direction.
Maybe AI infrastructure is not ultimately about compute efficiency at all.
Maybe the harder economic problem is retained permission.
Who gets remembered. For how long. Under what economic terms.
That sounds abstract now.
Then again, so did blockspace economics before markets figured out recurring settlement was the actual business model.
OpenLedger may fail completely at solving this.
Very possible.
But the question it points toward feels real.
And sometimes the better investment thesis is not the answer a project gives.
It is the problem the market has not learned to price yet.