Tôi dừng lại khá lâu khi đọc cách OpenLedger nói về việc biến transaction categorization thành một lớp reasoning cho máy.
Ban đầu, ý tưởng này nghe rất hợp lý.
On-chain data quá rối với con người. Một ví chuyển tiền. Một contract gọi contract khác. Một vault xoay tài sản. Một agent execute vài bước liên tiếp. Tất cả trôi qua như một dòng hash lạnh, dày đặc, gần như không thể đọc bằng mắt thường.
Nếu có một lớp ngữ cảnh đứng giữa, gom hành vi đó thành các nhóm dễ hiểu hơn như capital allocation, treasury routing hay risk movement, agent có vẻ sẽ hiểu thế giới tài chính nhanh hơn.
Nhưng càng nghĩ, tôi càng thấy điểm nguy hiểm nằm ở chữ “hiểu”.
Nếu transaction categorization chỉ giúp con người đọc lại dữ liệu, nó rất hữu ích. Nếu nó chỉ giúp agent giảm tải truy xuất, nó có lý do tồn tại. Nhưng nếu nó trở thành lớp reasoning chính, nơi agent nhìn thế giới thông qua các nhãn kế toán được con người đặt sẵn, thì đây không còn là bệ phóng.
Nó có thể trở thành một chiếc lồng nhận thức.
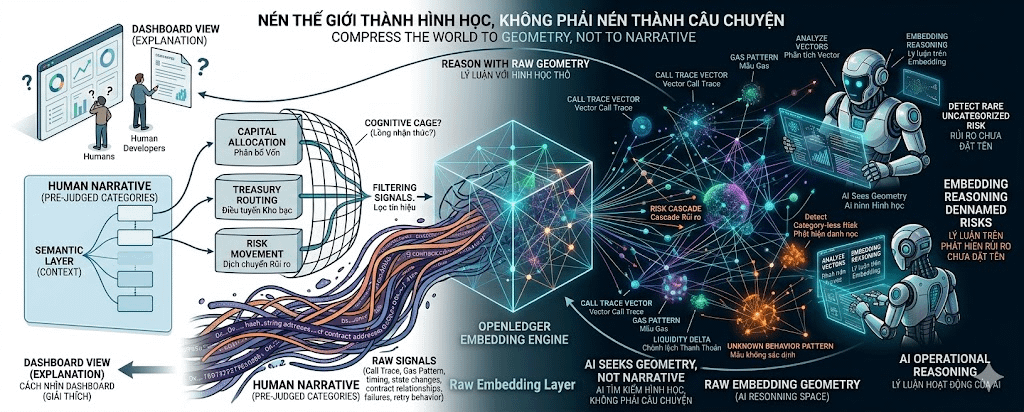
Vấn đề không phải blockchain quá noisy. Vấn đề là noisy với ai.
Với con người, một chuỗi call trace, state change, gas pattern, timing và address relation rất khó đọc. Nhưng với mô hình học máy, những thứ đó không nhất thiết là rác. Chúng có thể là tín hiệu. Thậm chí, chính phần con người thấy hỗn loạn lại có thể chứa trạng thái rủi ro mới nhất.
Một agent tài chính mạnh không chỉ cần biết giao dịch đó thuộc category nào. Nó cần phát hiện những trạng thái chưa có category. Những pattern chưa được đặt tên. Những cách dòng tiền tự ngụy trang trước khi con người kịp viết một nhãn cho nó.
Nếu ta ép mọi thứ vào vài nhãn như treasury routing hay capital allocation quá sớm, ta đang lọc bớt thông tin trước khi AI kịp nhìn thấy cấu trúc thật.
Nhưng nói “cứ để AI đọc raw data trực tiếp” cũng không thực tế.
Raw call trace rất đắt. State change rất nặng. Một agent chạy real-time không thể mỗi lần ra quyết định đều tự parse hàng triệu block, dựng lại đồ thị ví, tạo embedding từ đầu rồi mới hành động. Nếu vậy, hệ thống sẽ nghẽn bởi latency và compute cost trước khi nó kịp thông minh.
Vì vậy, vấn đề không phải là có nên nén dữ liệu hay không.
Vấn đề là nén theo hình dạng nào.
Nếu nén raw on-chain behavior thành nhãn chữ cho con người đọc, ta được dashboard đẹp hơn. Nhưng nếu agent dùng chính nhãn đó làm input quyết định, nó sẽ bị trói vào cách con người hiểu tài chính hôm qua.
Thứ OpenLedger nên ưu tiên không phải là một lớp nhãn kế toán cho máy.
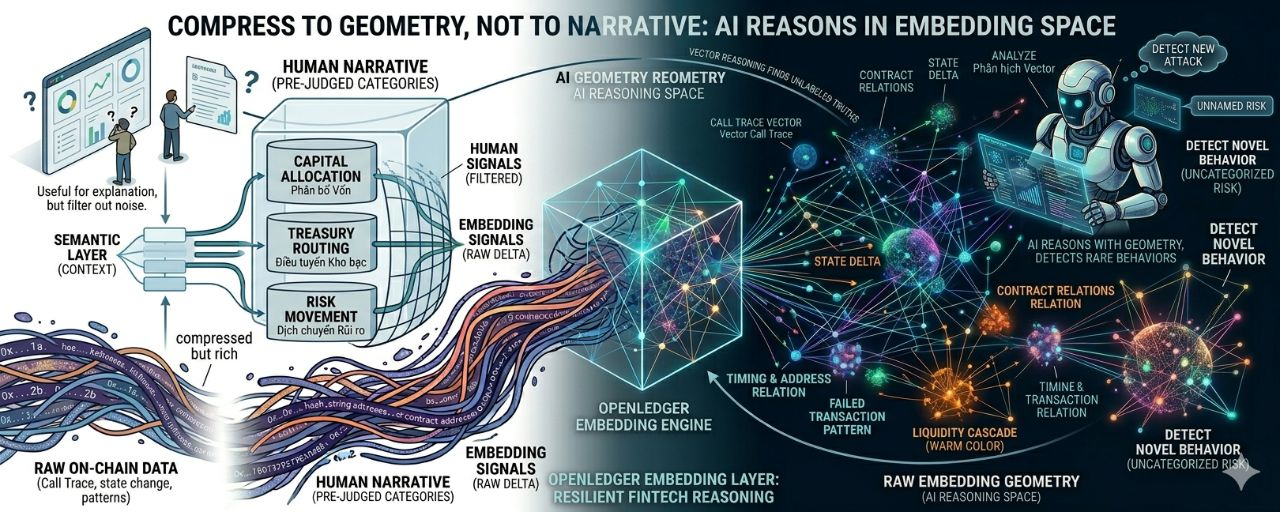
Mà là một raw embedding layer.
Tức là raw data vẫn được nén, nhưng không bị dịch quá sớm thành những danh mục nghèo thông tin. Call trace, gas pattern, liquidity movement, state delta, contract path, failed transaction, retry behavior và address relation có thể được biến thành không gian embedding giàu cấu trúc. Con người nhìn vào có thể không hiểu ngay, nhưng agent có thể thấy khoảng cách, cụm, bất thường, tương quan và rủi ro mà nhãn chữ không chứa nổi.
Nói cách khác: đừng nén thế giới thành câu chuyện cho con người, rồi bắt AI tin câu chuyện đó.
Hãy nén thế giới thành hình học cho máy.
Đây là ranh giới quan trọng với OpenLedger.
Tôi không nghĩ OpenLedger sai khi muốn làm on-chain data dễ dùng hơn cho AI. Ngược lại, nếu OpenLedger với MCP và lớp context có thể giảm chi phí truy xuất, chuẩn hóa luồng dữ liệu và đưa agent đến đúng vùng thông tin nhanh hơn, đó là một mảnh ghép rất đáng giá. Không ai muốn một agent tài chính phải tự đào từ genesis block mỗi lần ra quyết định.
Nhưng lớp context không nên trở thành đôi mắt của agent.
Nó nên là bộ định tuyến và bộ phiên dịch.
Nó giúp agent tìm đúng vùng dữ liệu nhanh hơn. Nó giúp con người đọc lại quyết định bằng ngôn ngữ dễ hiểu hơn. Nhưng phần reasoning cốt lõi của agent không nên bị khóa trong các category kế toán tĩnh.
Vì trong DeFi, nhãn luôn già đi nhanh hơn hành vi.
Một transaction nạp tài sản vào vault có thể là yield optimization. Cũng có thể là leverage risk. Cũng có thể là governance exposure. Cũng có thể là mầm của một cascade chưa xảy ra. Nếu hệ thống ép nó vào một danh mục quá sớm, reasoning phía trên sẽ lệch. Không phải vì nhãn sai hoàn toàn. Mà vì nhãn đúng quá ít.
Đây cũng là nơi semantic layer có thể trở thành bề mặt tấn công.
Khi nhãn trở thành tín hiệu định tuyến cho agent, attacker sẽ không chỉ tấn công contract. Họ có thể tấn công ý nghĩa. Họ có thể làm cho hành vi độc hại trông giống treasury routing, risk reduction hay liquidity optimization. Nếu agent tin vào nhãn nhiều hơn cấu trúc thô bên dưới, nó đã mất đi thứ quan trọng nhất trong tài chính on-chain: sự đa nghi toán học.
Vì vậy, quy trình đúng nên đi ngược lại.
Agent nhìn bằng raw embedding và tín hiệu thô đã được nén đúng cách. Sau đó, khi cần audit, báo cáo hoặc xin confirmation, semantic layer mới dịch quyết định đó thành ngôn ngữ con người hiểu được.
AI nhìn bằng vector.
Con người đọc bằng nhãn.
Đừng đảo ngược thứ tự đó.
Câu hỏi cuối cùng không phải là OpenLedger có thể làm transaction dễ hiểu hơn hay không. Câu hỏi thật là: lớp context của OpenLedger sẽ giúp AI nhìn on-chain finance rõ hơn, hay sẽ bắt AI đeo kính kế toán của con người rồi gọi đó là reasoning?