AI 圈目前有一种非常诡异的默认共识。
我们惊叹于大模型生成的代码和精美的原画,却默契地不去追问:这些能力究竟是从谁那里“偷”来的?
现在的主流 AI 就像一个完美的销赃机器。
它吞下数以百万计的独立开发者、画师和研究员的心血,把它们碾碎在几千亿个参数里。然后吐出一个毫无溯源痕迹的完美答案。
创造价值的人什么都得不到。而搭建这个黑盒的巨头收割了所有的溢价。
这不仅是伦理问题,更是一个经济上的死结。
如果最高质量的知识生产者赚不到钱,活水就会枯竭。最终 AI 只能去吃前代 AI 产出的废料。
这正是 @OpenLedger 试图切入的切口。但它用的方法,比发个币搞“Data to Earn”要狠得多。
它的核心交付物,是一张“小票”(Receipt)。
想象一下你在精品超市买有机蔬菜。包装上一定会有一个二维码,扫开就能看到这个西红柿是哪个农场种的、几号采摘的。
人们愿意为这种“透明度”支付极高的溢价。
OpenLedger 实际上在做同样的事,只不过商品变成了 AI 的输出。
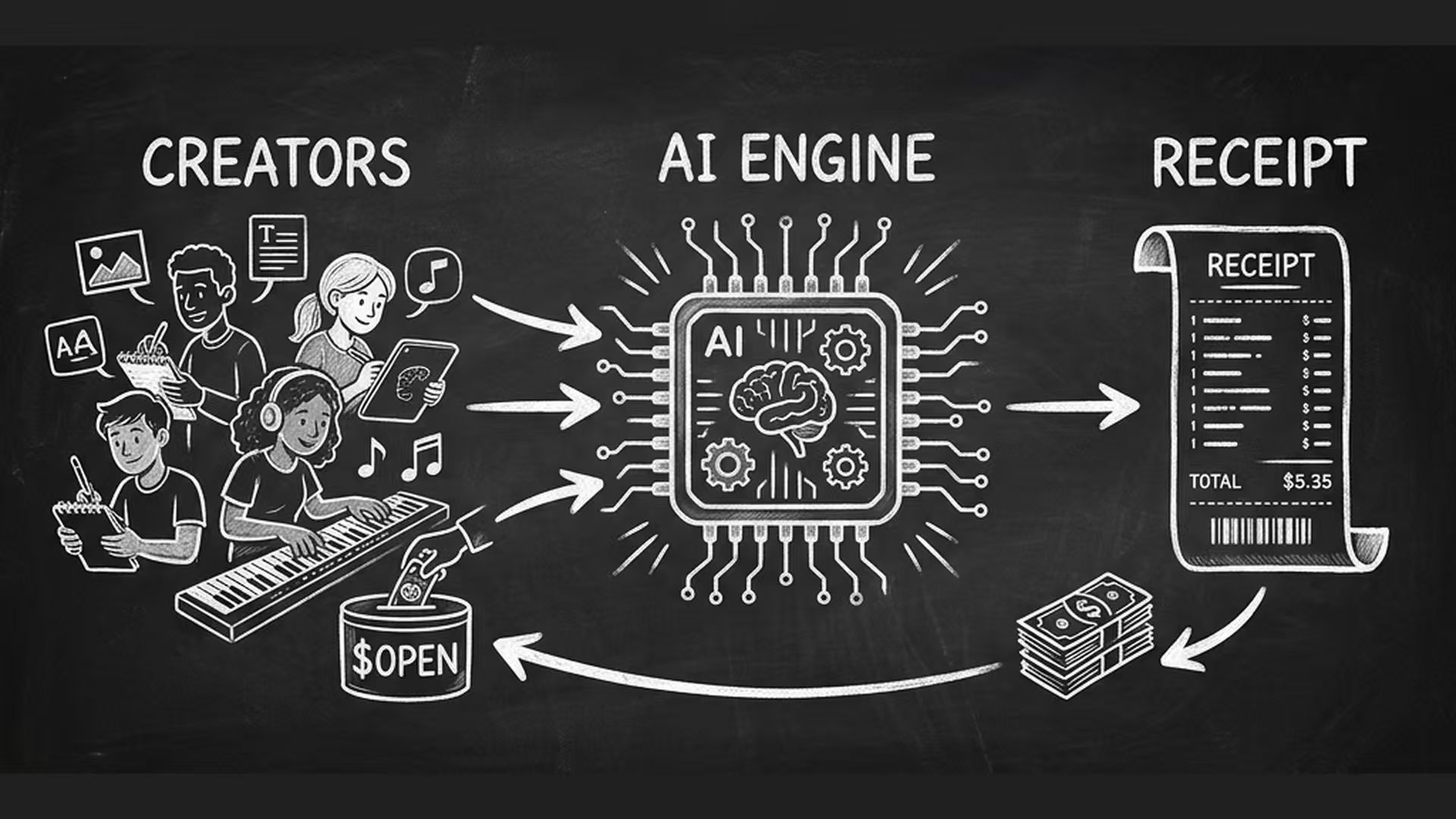
当一个基于 OpenLedger 的 AI 模型给出一个高价值的商业答案时,区块链上会同步生成一张不可篡改的加密凭证。
这张凭证上清清楚楚地写着:这次推理,调用了哪几个社区的 Datanet(数据集),消耗了谁的 GPU,套用了谁的微调权重。
原本“提取-消耗”的单向死胡同,突然变成了一个可以结算的十字路口。
一旦有了这张小票,智能合约的齿轮就开始转动了。
调用者支付的费用,可以沿着小票上的记录,自动切分成极其微小的版税,精准地打入原始数据贡献者的钱包。
在这个业务流里,$OPEN 代币不再是空洞的治理选票,而是跑通整个自动化结算链条的燃油。
每一次调用,每一张小票的生成,每一次版税的分发,都在消耗或质押 $OPEN。它实际上在试图捕获这套新经济系统里的网络 GDP。
听起来是个极其丝滑的闭环。
但如果你真的把这个逻辑往深了推,很快就会撞上一堵极高的墙:权重的“定价权”。
把调用记录哈希上链,技术上并不难。
难的是,如果生成一行代码,同时调用了 A 写的 10 行核心算法,和 B 抄来的 1000 行基础框架。这张“小票”里的版税该怎么分?
区块链只能客观记录“谁参与了”,但它无法主观裁定“谁的贡献更有价值”。
如果只是按数据量来结算版税,这个系统很快就会被机器生成的垃圾语料灌满。
要解决这个问题,就必须有一套极其复杂的动态权重评估机制。而这根本不是单纯的智能合约能算明白的。
所以,#OpenLedger 真正的壁垒,绝不是那张链上小票。
而是它能否通过无数次的真实商业博弈,在它的网络里沉淀出一套被全行业公认的“数据价值分配标准”。
谁掌握了 AI 时代知识的定价权,谁才是真正的赢家。记录数据永远只是第一步。
这对 $OPEN 提出了极其苛刻的验证要求。
我不关心它宣称能在一秒钟内处理多少张版税小票。
我只关心一件事:接下来,会不会有真正手握高价值、稀缺数据源的机构(比如医疗文献库、顶尖量化团队),因为想要这套“防白嫖”的确权分润机制,而选择把核心工作流搬到 OpenLedger 上。$CTR
如果这套系统只能吸引来一堆羊毛党上传维基百科的公开数据,那这张“加密小票”就毫无价值。
叙事可以很性感,但商业的流向永远是最残酷的。