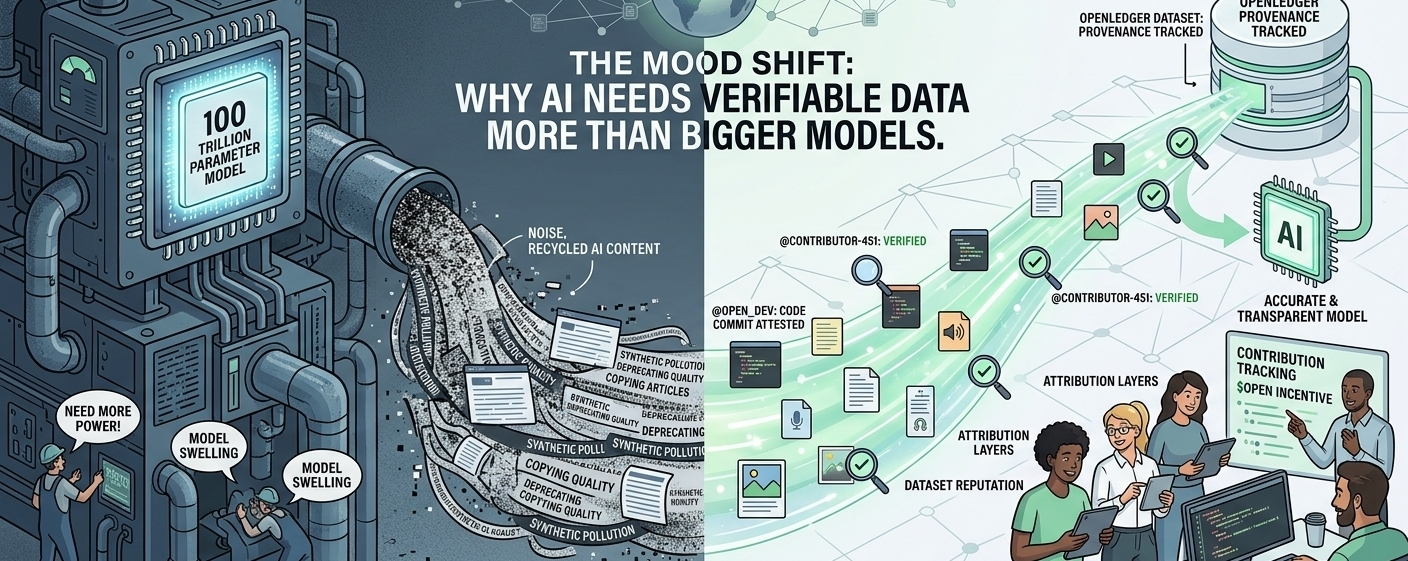
Most people inside crypto AI conversations still talk about speed, model size, or funding rounds. But the mood shifted quietly over the last year. Builders are starting to realize that unreliable data creates bigger long-term problems than slower inference ever will.That’s where @OpenLedger starts becoming interesting in a more practical way.Not because it promises magic. Honestly, the industry already has enough exaggerated promises floating around every timeline.
What stands out is the focus on traceable AI data contribution. That sounds technical at first, but the idea is simple: if AI systems are trained on massive datasets, someone should be able to verify where that information came from, who contributed it, and whether the inputs are actually useful instead of recycled noise.
That matters more in 2025 than people expected.
A few months ago I noticed more developers openly discussing “synthetic pollution” in AI outputs. Basically, AI models increasingly train on AI-generated content, which slowly weakens quality over time. You can already feel it online sometimes. Threads repeating threads. Articles copying articles. Same words. Same structure. Dead information pretending to be fresh.
Clean data suddenly becomes infrastructure.
OpenLedger seems positioned around that exact pressure point. The ecosystem is trying to create incentive alignment around verified contributions instead of treating data like an invisible commodity nobody tracks properly. There’s a subtle difference there, but an important one.
And communities notice these shifts earlier than markets usually do.
You can see more conversations now around attribution layers, decentralized data ownership, transparent AI sourcing, and contribution tracking. Not flashy topics. Still important. Especially as enterprises become stricter about compliance and governance around AI systems entering production environments.
The strange thing is that the next AI race may not belong to whoever generates the most content. It may belong to whoever can prove the quality and origin of the information feeding the models in the first place.
That changes incentives completely.
A small but telling detail: more builders have started caring about dataset reputation the same way open-source developers once cared about code commits. That wasn’t common even a year ago.
$OPEN sits directly inside that broader conversation now, whether people fully realize it yet or not.

