
On paper, AI and crypto infrastructure always looks very clean to me. Almost too clean, like everything fits perfectly into a diagram. Benchmarks look stable, numbers go up, graphs move in the right direction, and it feels like progress is simple and measurable.
But the more I look at real systems, the more I feel that this “clean version” is just one layer. Production is never clean in that way. It’s messy, unpredictable, and honestly a bit uncomfortable if you really sit with it.
Because real-world data is not curated. It’s not neatly labeled. It doesn’t behave. It changes. It breaks assumptions. And sometimes it even fights back in small ways—through noise, weird edge cases, or inputs that no benchmark ever prepared the system for.
That’s why I’ve started to question what we really mean when we say a model is “better.”
Benchmarks give a kind of comfort. Faster training, higher scores, better efficiency. It all sounds like progress, and in many ways it is. But benchmarks are still a controlled space. They assume structure. They assume predictability. They assume the world behaves itself.
Real life doesn’t.
And this gap between controlled performance and real performance is where things start to feel more complex than most people admit.
Sometimes I think we underestimate how fragile that gap can be.
A model can look extremely strong on paper, but the moment it is exposed to shifting distributions or real user behavior, it doesn’t always act the same way. Not because it is “bad,” but because reality is not stable the way benchmarks are.
This is also where newer infrastructure ideas start to feel more interesting to me.
Things like LoRA, QLoRA, and 4-bit quantization are often explained in a very technical way—cost reduction, faster training, less GPU usage. But I don’t think that’s the whole story.
To me, it feels like something deeper is happening underneath.
These methods are slowly changing who gets to participate in AI development. It’s not just big labs with massive compute anymore. More people can experiment, adapt, fine-tune, and actually build things on smaller setups.
That shift feels important.
Because access changes everything.
When something becomes more accessible, it stops being just infrastructure and starts becoming a kind of shared space.
But at the same time, I can’t ignore the hidden trade-off that always sits behind efficiency. Sometimes I wonder if we are quietly accepting small losses in accuracy or stability that only show up later—when systems are already deployed, already trusted, already scaling.
And that thought doesn’t have a simple answer.
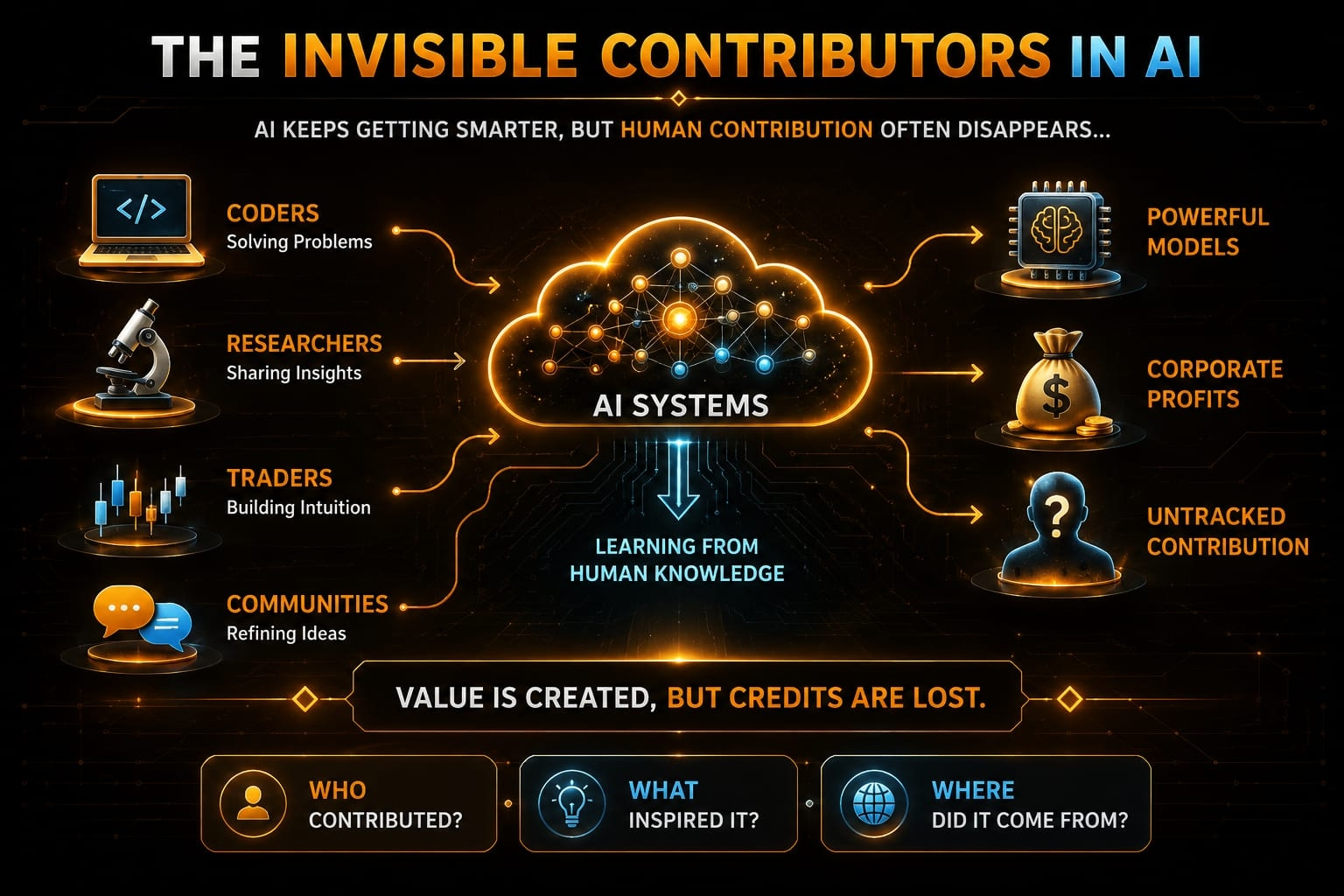
Then there is another layer that keeps coming up again and again: data itself.
Who owns it. Who gets credit. Who gets value from it.
Because AI systems are not built from nothing. They are built on contributions from millions of small inputs, datasets, interactions, and human traces that are rarely acknowledged in a clear way.
This is where ideas like OpenLedger become interesting to think about, at least in principle. Not because everything is solved there, but because they try to connect contribution, tracking, and reward into a more transparent structure.
Almost like turning the AI pipeline into an economy where participation is visible.
But even that idea has tension in it.
The more measurable and transparent a system becomes, the more it also opens space for gaming it. People start optimizing for metrics instead of meaning. Contribution becomes something that can be shaped, not just given. And fairness becomes harder, not easier.
So I keep coming back to this strange balance.
Transparency helps, but also distorts.
Efficiency helps, but sometimes hides long-term cost.
Accessibility expands participation, but also increases unpredictability.
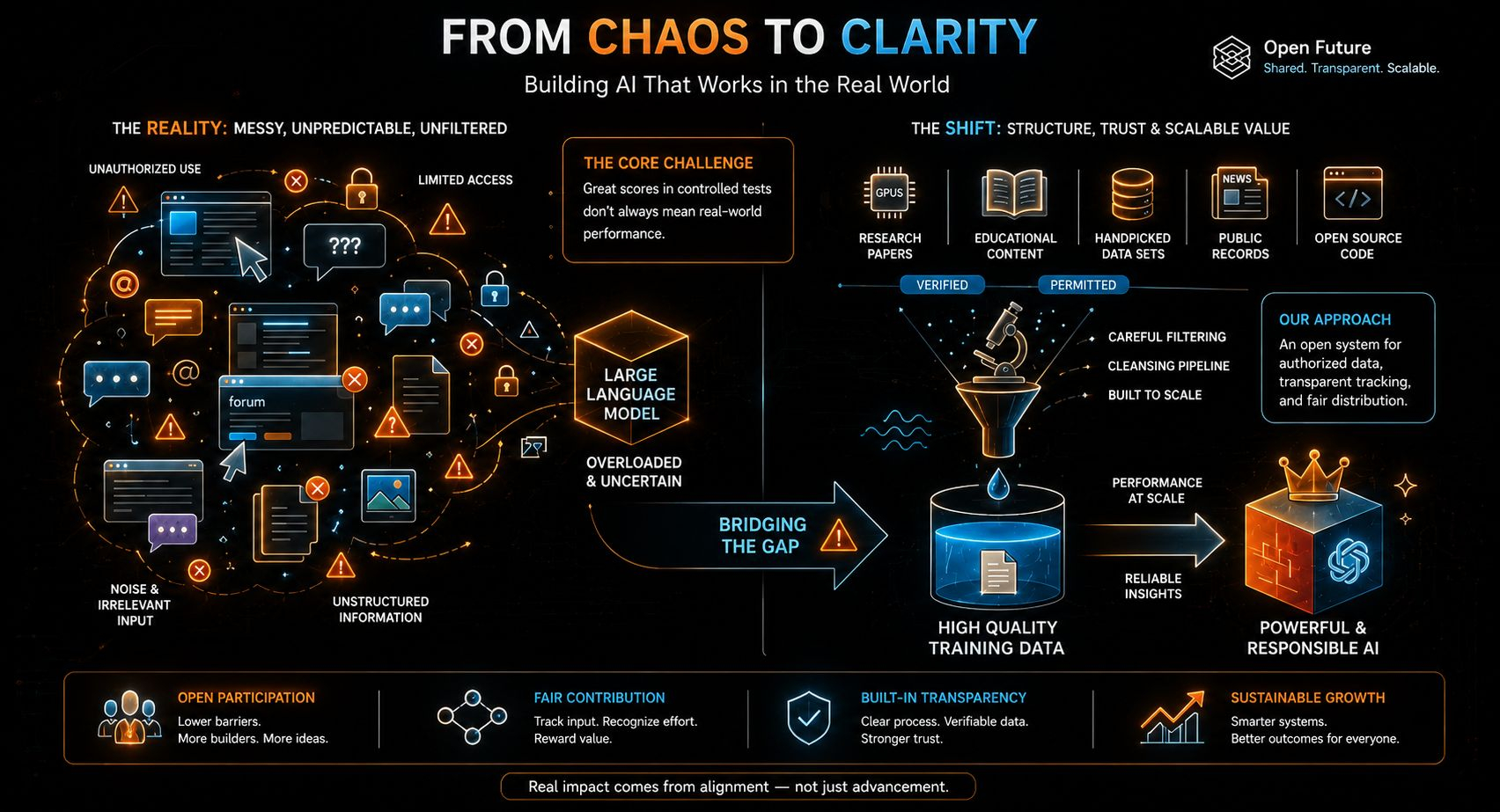
When I look at ModelFactory-style systems and OpenLedger-style ideas together, I don’t really see a finished structure. I see something still forming. Something layered, still unstable, still learning how to exist outside controlled environments.
And maybe that’s the most honest way to look at it.
Not as a completed system.
But as something still unfolding between theory and reality, where every improvement also brings a new kind of uncertainty with it.