
大多数人提到 AI 的商业模式,脑子里浮现的依然是两种极其原始的路径:要么卖算力,要么像 ChatGPT 那样卖月度订阅。
说实话,我一开始也是这么想的。当我们听到 @OpenLedger 在讲“数据归因(Attribution)”时,我第一反应是:这大概又是一个给数据打上去中心化水印、用来防抄袭或迎合监管的合规工具。
但当我仔细观察那些基于 API 提供高级服务的 AI Agent 生态时,我发现了一个被掩盖的巨大认知裂缝。
目前的 AI 经济,本质上是一种对高质量数据源的单向掠夺机制。大模型厂商以极低的成本获取数据训练出模型,之后这个模型每生成一段关键代码、每做一次商业预测、每赚取一分钱,都与原始数据贡献者毫无关联。
你可以想象,如果这种“一次性买断、无限次套现”的模式继续运转,真正高价值的私有数据(比如顶尖医院的罕见病历、量化机构的核心因子)绝对不可能向 AI 敞开大门。因为交出数据,就意味着交出核心壁垒,却得不到持续的经济回馈。
这让我意识到,OpenLedger 真正试图解决的,根本不是表层的合规难题,而是在重构 AI 产业链的底层价值流向。
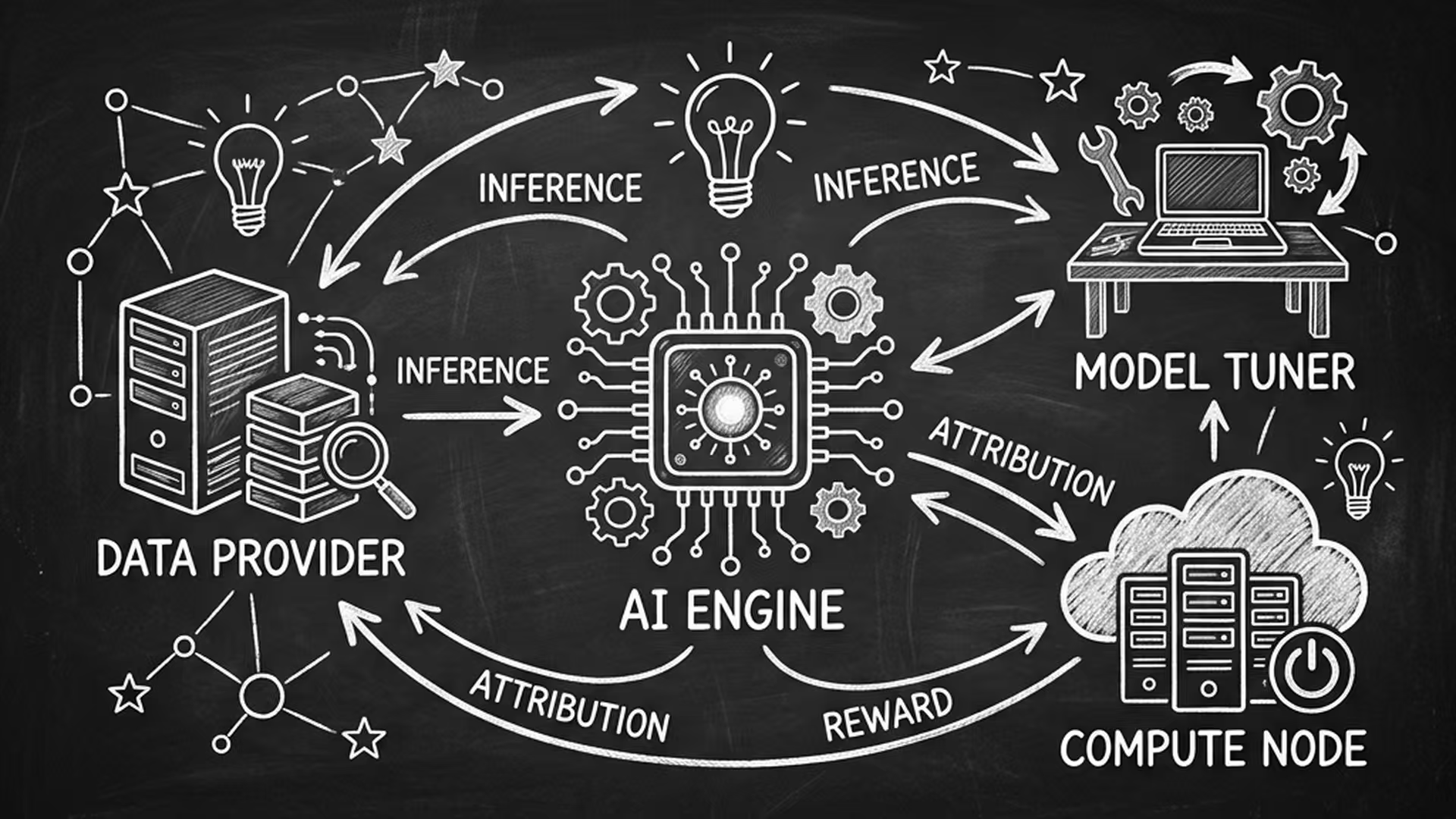
在这个新架构里,核心密码就藏在两个动作的强制绑定上:Inference(推理) 与 Attribution(归因)。
在过去,AI 是一个输入即输出的黑盒。但在 OpenLedger 的机制下,当 AI 模型产生输出的那一瞬间(即 Inference 发生时),底层协议会立刻触发逆向追溯(Attribution)。
这就意味着,每一次 AI 对话、每一次自动执行的交易任务、每一次机器对机器的 API 调用,都被强制转化为了一个透明的、可拆解的经济事件。
让我们代入一个真实的商业场景:
假设你是一个量化交易员,正在调用一个基于 OpenLedger 部署的 AI 预测模型,并为这次调用支付了 1 美元。在这个极其短暂的推理过程中,系统的归因网络瞬间完成了溯源:这次预测,30% 依赖了 A 机构提供的宏观数据集,50% 用到了 B 社区微调的金融权重,20% 消耗了 C 节点的算力。
随即,智能合约像自动分账机一样,把你的 1 美元精准切分:0.3 美元打入 A 的钱包,0.5 美元给 B,0.2 美元给 C。原本“提取-消耗”的单向死胡同,彻底变成了一个多方实时结算的十字路口。创造模型的人和提供数据的人,第一次在“实时交付”中拿到了公平且持续的补偿。
这听起来是一个极其完美的商业闭环,似乎它能一举解决困扰大模型的“数据枯竭焦虑”。

但这也是我开始变得极其谨慎的地方。
这套系统的生死存亡,并不取决于它的密码学设计有多精妙,而是受制于一个冷酷的物理与博弈论铁律:验证成本绝对不能倒挂。
实时归因系统能够运转的唯一前提是,“证明你做过贡献”的记账成本,必须永远且显著地低于“被追踪到的价值本身”。$ETH
如果在数百亿参数的模型里进行归因的摩擦过大,或者羊毛党可以用自动化脚本轻易刷出合成的推理调用来套取分润,那么劣币就会迅速淹没整个系统。真正的企业买单方会转身离开,只留下一堆为了薅代币而互相对话的 AI 农场。
技术上的绝对正义,如果违背了基本的经济学重力,就一定会被市场无情抛弃。
所以,我并不关心它在测试网跑出了多高的 TPS。我只关心,当早期的代币排放红利消退后,真实的协议使用量是否还能维持?
外部的开发者是否真的愿意为了“版权透明和溯源分润”,去承担这些额外的摩擦成本?还是说,目前的估值仅仅是在为一个其实没人愿意买单的乌托邦提前定价?$ZEC
在下一次市场波动到来时,观察那些高频、低延迟的商业调用是否还留在网络中,往往才是揭露底牌的真正指标。