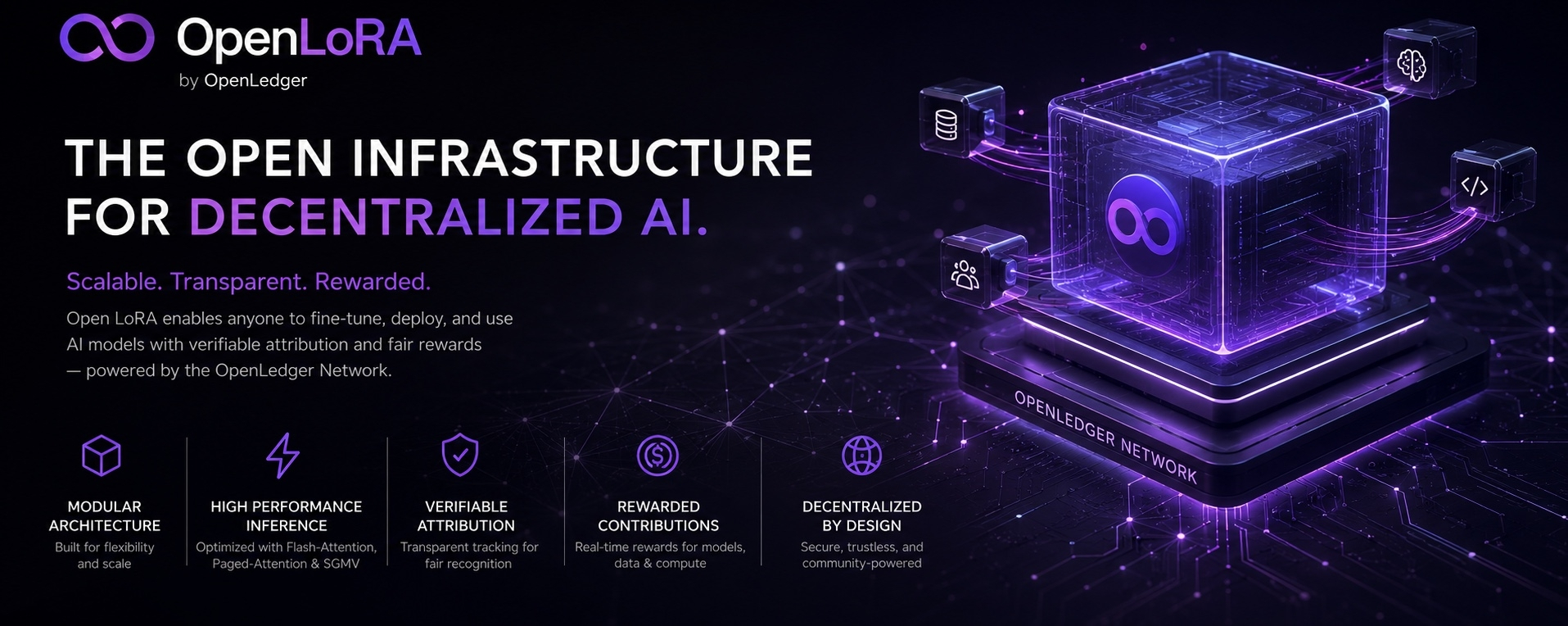
Componenti Fondamentali
Il framework Open LoRA è progettato attorno a un'architettura modulare e scalabile che consente un'efficiente distribuzione dei modelli, inferenza dinamica e attribuzione trasparente all'interno dell'ecosistema OpenLedger.
Storage Adattatori LoRA
Gli adattatori LoRA finemente ottimizzati sono memorizzati in modo sicuro all'interno dell'infrastruttura decentralizzata di OpenLedger. Invece di caricare ogni adattatore in memoria simultaneamente, gli adattatori vengono recuperati e attivati dinamicamente in base ai requisiti di inferenza, migliorando significativamente la scalabilità e l'efficienza delle risorse.
Hosting di Modelli & Fusione Dinamica di Adattatori
Il sistema opera su un'architettura di modello fondamentale condiviso, dove gli adattatori LoRA vengono fusi in tempo reale durante l'inferenza. Questo approccio minimizza l'hosting ridondante del modello mentre consente una rapida personalizzazione per compiti e domini diversi.
Open LoRA supporta anche la fusione in stile ensemble di più adattatori, consentendo a strati di conoscenza combinati di migliorare la qualità dell'inferenza e le prestazioni complessive del modello.
Motore di Inferenza ad Alte Prestazioni
Lo strato di inferenza è ottimizzato utilizzando tecniche di accelerazione avanzate basate su CUDA, inclusi:
Flash Attention — riduce il sovraccarico di memoria e migliora l'efficienza dei trasformatori.
Paged Attention — consente l'elaborazione efficiente di sequenze a lungo contesto.
Ottimizzazione SGMV (Sparse General Matrix Vector Multiplication) — accelera il throughput dell'inferenza riducendo i costi computazionali.
Insieme, queste ottimizzazioni offrono prestazioni di inferenza di grado produzione a bassa latenza.
Instradamento delle Richieste & Streaming di Token
Uno strato di instradamento delle richieste dedicato dirige dinamicamente le chiamate API alle configurazioni di adattatore appropriate durante il runtime. Gli output generati vengono trasmessi in modo efficiente utilizzando kernel di consegna token ottimizzati, garantendo interazioni reattive e senza soluzione di continuità in tempo reale.
Motore di Attribuzione
Lo strato di attribuzione tiene automaticamente traccia e registra ogni componente coinvolto in un processo di inferenza — inclusi modelli, adattatori, set di dati, risorse computazionali e contributori.
Questo crea un framework di attribuzione trasparente e verificabile che:
Garantisce un riconoscimento equo dei contributori
Consente una distribuzione accurata delle ricompense
Mantiene registri d'uso immutabili in tempo reale
Rete OpenLedger
La rete OpenLedger funge da strato di coordinamento decentralizzato che collega sistemi di archiviazione, inferenza, attribuzione ed esecuzione in un'infrastruttura IA unificata.
I contratti smart gestiscono:
Permessi di accesso
Registrazione attribuzionale
Verifica dell'uso
Distribuzione di incentivi tokenizzati
Questa architettura consente coordinamento sicuro, scalabile e senza fiducia durante l'intero ciclo di vita dell'IA.
#OpenLedger #TradersShiftBTCToStablecoins #Jefferies$1TCryptoIPOMarket
#CashAppUSDCFor60MUsers
@OpenLedger $OPEN $BTC $ETH

