
最近圈子里聊OpenLedger的热度特别高,很多人都盯着它AI公链的叙事、大咖背书还有独特的AI资产流动性逻辑,觉得这是下一代AI链的潜力黑马。我这段时间一直在深耕它的链上运行逻辑和底层工程架构,不蹭热度、不吹概念,单纯以实战玩家的视角,跟大家好好唠唠它现阶段最真实、最容易被市面研报忽略的技术短板。市面上大部分分析都在夸它的PoA归因确权、EVM兼容、AI数据资产化的优势,但很少有人沉下心讲它落地的硬瓶颈,今天我就避开同质化内容,从最核心的链上吞吐量、PoA计算成本、模型部署落地三个维度,客观拆解问题、梳理改进空间,顺带给大家一份可落地的中立预判,全程大白话聊天模式,普通人也能看懂,老玩家也能挖到深度逻辑。#OpenLedger $OPEN @OpenLedger
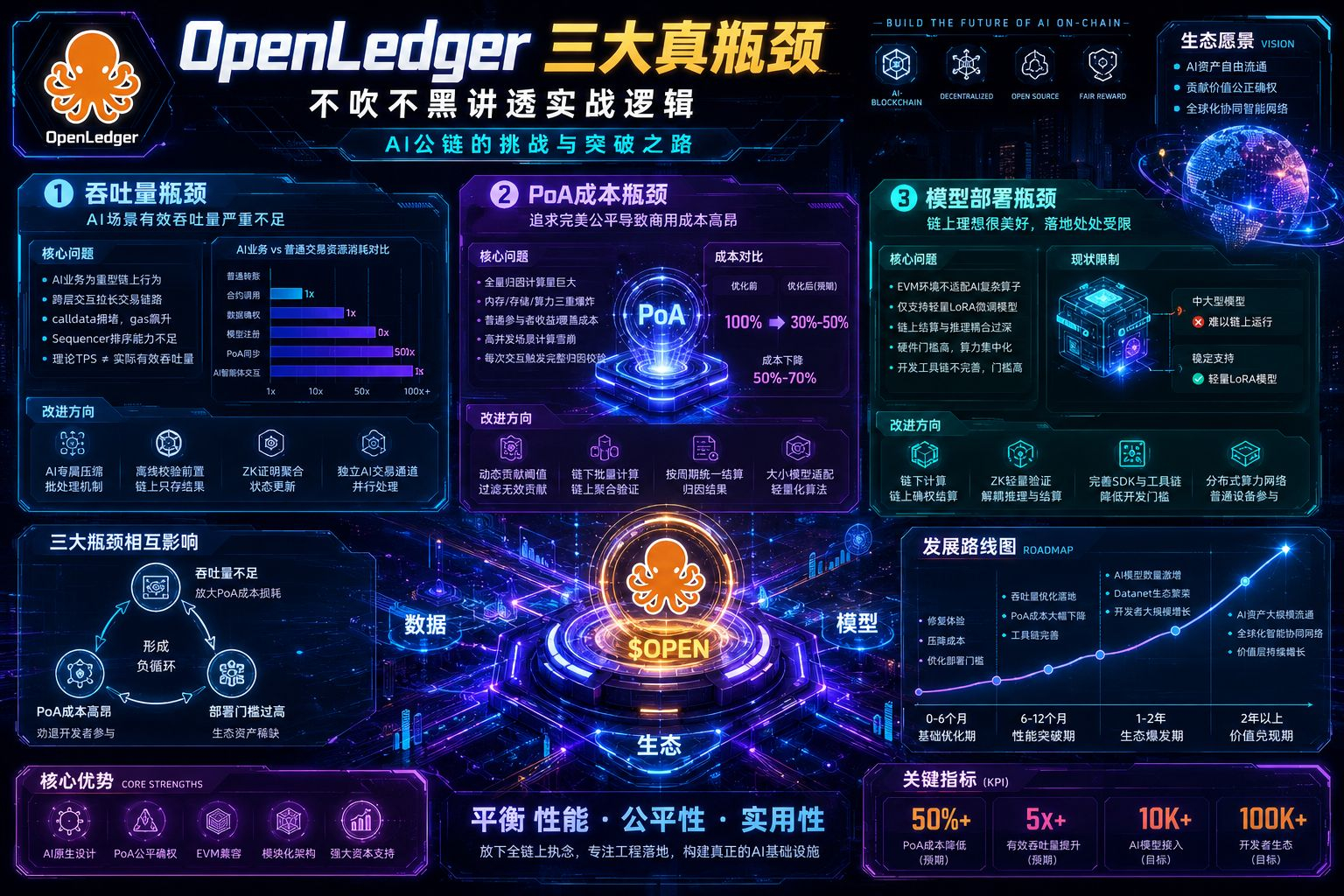
首先聊大家最容易踩坑的吞吐量问题,我先说个核心结论,OpenLedger的吞吐量短板,根本不是官方宣传的纸面TPS数据,而是适配AI场景的有效吞吐量严重不足。很多人看公链只会看官方公布的理论交易速度,但普通公链的转账、合约调用都是轻量化交易,而OpenLedger所有核心生态场景,全是高负载的重型链上行为。不管是Datanet数据协作、模型参数上链确权、AI智能体交互,还是PoA归因证明的链上同步,每一笔操作的资源消耗,都是普通链上转账的几十倍甚至上百倍。它依托OP Stack加EigenDA的架构搭建L2底层,理论并发数据看着很漂亮,但这套架构本身是为通用区块链场景设计的,并没有针对AI专属交易做深度优化。

这就导致了一个很尴尬的现状,测试网小规模运行的时候一切完美,流畅度、稳定性都没问题,可一旦接入规模化的数据集、多模型并行运行,链上拥堵、交易延迟、打包变慢的问题会立刻暴露。而且它的执行层和结算层分离架构,虽然提升了底层安全性,但每一次模型注册、数据确权、收益结算都需要跨层交互,进一步拉长了交易链路、消耗区块资源。再加上EigenDA只能优化存储成本,没法解决高并发下calldata拥堵和gas飙升的问题,Sequencer对AI批量交易的排序、压缩能力也跟不上业务需求,最终就出现了纸面数据好看,真实AI业务跑不动的脱节情况。目前它的实际有效吞吐量,大概率只有理论值的五分之一不到,这个问题不是简单升级节点、扩容服务器就能解决的,是底层交易结构和AI业务场景不匹配的原生问题。想要改善只能靠专项优化,比如针对AI交易做专属压缩和批处理机制,把大量离线校验工作前置,链上只保留最终确权结果,再搭配ZK证明聚合状态更新,拆分出独立的AI交易通道,后续迭代才能慢慢释放性能上限,短期很难彻底根治。
接着聊它最核心的机制,也是最大的成本痛点——PoA归因证明机制。说实话,PoA是OpenLedger的核心护城河,也是它区别于所有普通AI链的关键,主打全链路贡献可追溯、公平确权、按劳分配,这个叙事和逻辑完全没问题,甚至可以说是目前AI资产确权最合理的思路。但从实战落地的角度来说,现在的PoA机制过于追求理论完美,直接导致商用成本高到难以规模化。很多研报只吹它的公平性、透明性,却绝口不提普通参与者根本扛不住的计算和gas成本。

大家要明白,PoA需要精准追踪每一条训练数据、每一次模型微调、每一次推理交互对最终AI模型的贡献占比,依托专属算法完成精细化归因统计。小模型、小体量数据集的场景下,这套机制运行顺畅,计算量可控、成本可接受。可一旦升级到商用级大模型,面对万亿级的训练语料和海量推理请求,全量归因计算会直接出现内存、存储、算力三重爆炸。最现实的问题就是,普通数据贡献者、小型开发者参与生态的收益,甚至覆盖不了PoA校验产生的gas费用和算力成本,这就直接卡死了生态增量。更尴尬的是,现阶段每一次AI推理交互都会触发一次完整的归因校验,高并发场景下会出现计算雪崩,链上延迟飙升,整个生态的运行效率都会断崖式下跌。
其实这个问题不是无解,而是需要项目方做工程层面的取舍,完美的公平和低成本的规模化本身就是悖论。后续最可行的改进方向,就是放弃极致的全量归因,设置动态贡献阈值,自动过滤无价值的微小贡献,砍掉九成以上的无效计算资源消耗。同时改成链下批量计算、链上聚合验证的模式,不用每笔操作都上链校验,按周期统一结算归因结果,针对大小模型适配不同的轻量化算法。我预判未来半年内,这套优化落地后,PoA的综合运行成本能下降五成到七成,基本达到商用入门标准,但想要实现零损耗、全精准归因基本不可能,这也意味着它的公平性机制永远需要为规模化发展让步,这会长期影响它的代币经济和生态激励模型。

最后聊聊最贴近落地的模型部署限制,这也是很多开发者进场后吐槽最多的点。OpenLedger一直主打AI模型全生命周期链上运行,但真实的落地现状是链上确权看着完美,实际AI工程落地处处受限。现阶段它的底层架构和EVM兼容环境,对主流AI框架、复杂算子的适配性并不完善,根本支撑不了完整大模型的链上训练和部署,目前生态内能够稳定运行的,只有轻量化的LoRA微调模型,中大型模型只能走链下训练、链上确权的折中路线。
而且它的链上结算和AI推理服务高度耦合,原本链下可以高速并发的推理任务,会被链上的确权、计费、归因流程拖累,导致用户体验和运行效率大打折扣。硬件门槛也是一个绕不开的问题,普通节点设备根本承载不了中型AI模型的运行需求,算力资源高度集中,和它去中心化AI生态的初衷相悖。再加上目前配套的开发工具链不完善,模型转换、运维监控、弹性扩容的流程都很繁琐,极大拉高了普通开发者的进场门槛,这也是为什么它叙事火爆,但优质链上AI模型、活跃Datanet生态一直起不来的核心原因。
后续的改进方向也很清晰,想要盘活生态,就必须放弃“全链上AI”的理想化执念,长期走链下计算、链上确权结算的混合模式。通过ZK轻量化验证技术放开链上算力限制,彻底解耦推理服务和链上结算流程,让高效算力运行归链下,资产确权、收益分配、合规追溯归链上。同时补齐专属SDK和适配工具链,降低开发者部署门槛,搭建分布式算力网络,让普通设备也能参与生态贡献,慢慢弱化算力集中的问题。

综合来看,这三个核心瓶颈从来不是孤立存在的,而是互相牵制、形成闭环影响整个生态的发展速度。吞吐量不足会放大PoA机制的成本损耗,高昂的计算成本劝退开发者,而部署门槛过高又导致生态优质资产稀缺,反过来让底层性能优化失去落地场景,短期形成负循环。站在中立投研的角度,我对OpenLedger的预判很清晰,它的赛道逻辑、核心机制、资方背景都没有问题,绝对是值得长期关注的AI链标的,但现阶段完全处于技术瓶颈突破期,不存在短期爆发的基础。
短期半年内,项目方的核心动作只会是修复体验、压降成本、优化部署门槛,生态不会出现爆发式增长,适合左侧耐心布局,不适合追高博弈。等到半年到一年,吞吐量、PoA成本、部署门槛的核心优化落地后,生态的模型数量、数据网络、开发者体量才会迎来指数级增长。长期来看,它能不能站稳AI龙头公链的位置,不看叙事炒作,只看能不能平衡好性能、公平性、实用性三者的关系,放下理想化的全链上执念,踏踏实实做好工程落地。
整体而言,OpenLedger不是空气叙事项目,有真实的技术壁垒和落地价值,但市面大部分利好解读都过于片面。我们做投研、做布局,永远要看真实的链上负载、真实的落地成本、真实的开发者体验,抛开技术瓶颈谈估值都是空谈。目前它的所有问题都是早期工程化的问题,不是底层逻辑缺陷,只要迭代节奏稳定,瓶颈会逐步突破,但这个过程需要足够的时间,切忌盲目FOMO,耐心等待技术拐点和生态数据拐点才是最稳妥的策略。#OpenLedger $OPEN @OpenLedger