

A few years ago, if an AI model topped a benchmark, I probably would have accepted that at face value. Most people did. Higher score, better model, simple enough. That mental shortcut made sense when benchmarks felt like rough measurement tools rather than economic weapons.
Now I am not so sure.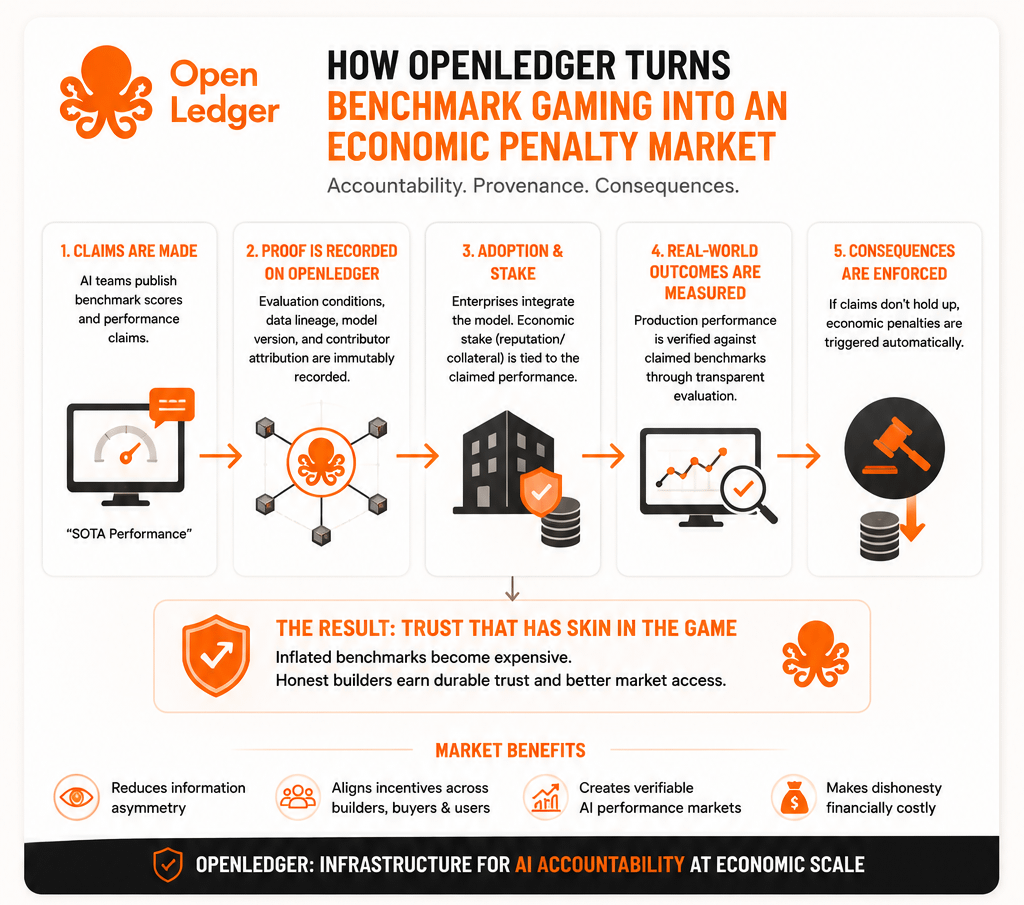
The strange thing about any scoring system is that once enough money starts reacting to it, the score itself stops being neutral. You see this everywhere. Schools teaching toward exams instead of understanding. Companies optimizing quarterly optics instead of actual health. Traders shaping books around visible liquidity because they know others are watching the same levels. AI is drifting into the same behavioral trap, just with shinier language.
Benchmark scores look objective from a distance. Clean tables. Percentage gains. Leaderboards moving up and down. It gives people something easy to point at. Investors love that. Enterprise buyers too, sometimes. Even media coverage becomes easier when intelligence can be compressed into a number.
But numbers are funny. They calm people down even when they should probably do the opposite.
The part that bothers me is not that benchmark gaming exists. Of course it exists. If a model developer knows exactly how evaluation works, knows which reasoning patterns get rewarded, knows what enterprise procurement teams are looking at, why would they not optimize toward that surface? That is not even necessarily fraud. Sometimes it is just rational adaptation. The problem starts when optimization and reliability quietly separate.
That gap matters more than people think.
Imagine a hospital testing AI triage support. Or a financial workflow assistant helping analysts summarize risk exposures. Nobody in those rooms really cares if the benchmark chart looked impressive on launch day. They care when outputs fail in ugly, expensive ways. Yet procurement behavior often starts upstream, where benchmark narratives shape attention before deployment risk becomes visible.
This is where I think the OpenLedger conversation gets more interesting than the usual AI infrastructure talking points.
Most people frame OpenLedger around decentralized AI economics, attribution, data contribution markets, maybe agent infrastructure. Fair enough. But the angle I keep circling back to is accountability under competitive pressure.
Because benchmark manipulation is not really about measurement integrity. That is the surface version. The deeper issue is economic consequence.
Right now, if an AI team aggressively optimizes performance narratives and wins market attention because of it, what actually happens if those claims fail under real usage? Usually not much, at least structurally. Maybe reputation damage. Maybe some contractual dispute. Maybe nothing at all if expectations were vague enough.
That feels incomplete.
Crypto, for all its chaos, has actually explored something useful here. Systems where economic behavior and accountability are mechanically linked. Validators get slashed. Collateral gets liquidated. Settlement rules are explicit because ambiguity becomes expensive fast.
I am not saying AI should copy crypto culture. God no. But some of the economic design logic is relevant.
OpenLedger’s attribution architecture starts looking more interesting if you stop thinking about provenance as bookkeeping and start thinking about it as liability scaffolding.
Who contributed data? Which model lineage produced an output? What evaluation environment was referenced? Which performance claims were tied to adoption decisions?
Those questions sound administrative until money starts leaking.
A benchmark today is mostly a marketing asset. Screenshot. Press release. Sales collateral. Social proof.
But if infrastructure exists where claims become economically traceable, then the psychology changes.
That is the real thought here.
Maybe OpenLedger does not create “better AI.” Maybe it helps create more expensive dishonesty.
That is a very different thesis.
Think about insurance for a second. Unsafe drivers eventually pay more. Credit markets punish repeated bad behavior. Even exchanges quietly adjust trust assumptions based on historical operational reliability. Systems do not eliminate bad behavior. They just make certain forms of it less attractive.
Benchmark inflation could face the same logic eventually.
If model providers had persistent economic reputation attached to declared capability claims, if buyers could verify provenance instead of consuming polished benchmark theater, then performance marketing gets less casual. Not impossible. Just heavier.
And honestly, that may be where AI infrastructure matures.
Because the current benchmark obsession feels weirdly adolescent. Everyone still behaves like bigger scores automatically mean stronger systems. Maybe in consumer hype cycles that works. In actual operational environments? Less convinced.
Europe’s regulatory direction already hints at this shift. Once AI touches regulated workflows, trust stops being philosophical. It becomes paperwork, audits, explainability demands, governance reviews, procurement committees. The vibe changes quickly.
That said, I can already see the friction.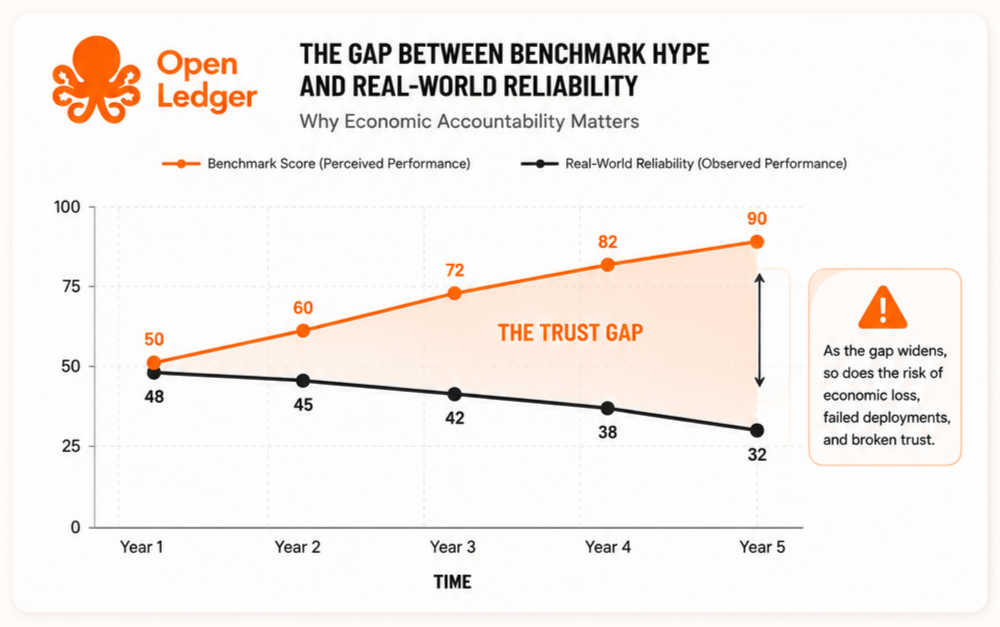
Who defines trustworthy benchmarks? That question alone becomes political. Model builders do not want to expose competitive internals. Enterprises want accountability without operational complexity. Privacy-sensitive systems cannot simply reveal everything for verification. Then there is token design, which crypto people should always interrogate harder than they do.
A useful protocol is not automatically a valuable token.
That distinction matters.
If $OPEN becomes part of recurring economic verification behavior, maybe there is durable demand logic. If it becomes symbolic infrastructure everyone references but nobody economically depends on, then the thesis weakens fast.
And there is another uncomfortable possibility.
Penalty systems sometimes create defensive behavior, not better behavior. Teams optimize to avoid blame instead of improving outcomes. Finance has done that dance plenty of times.
Still, I keep coming back to the same instinct.
The market thinks AI competition is about intelligence. Faster models. Better reasoning. More impressive demos.
Maybe that is yesterday’s framing.
Maybe the harder scarcity is believable accountability.
If benchmark scores increasingly behave like economic persuasion tools instead of honest measurement tools, then infrastructure that makes credibility expensive might matter more than another incremental model upgrade.
That is at least more interesting to me than another leaderboard screenshot.