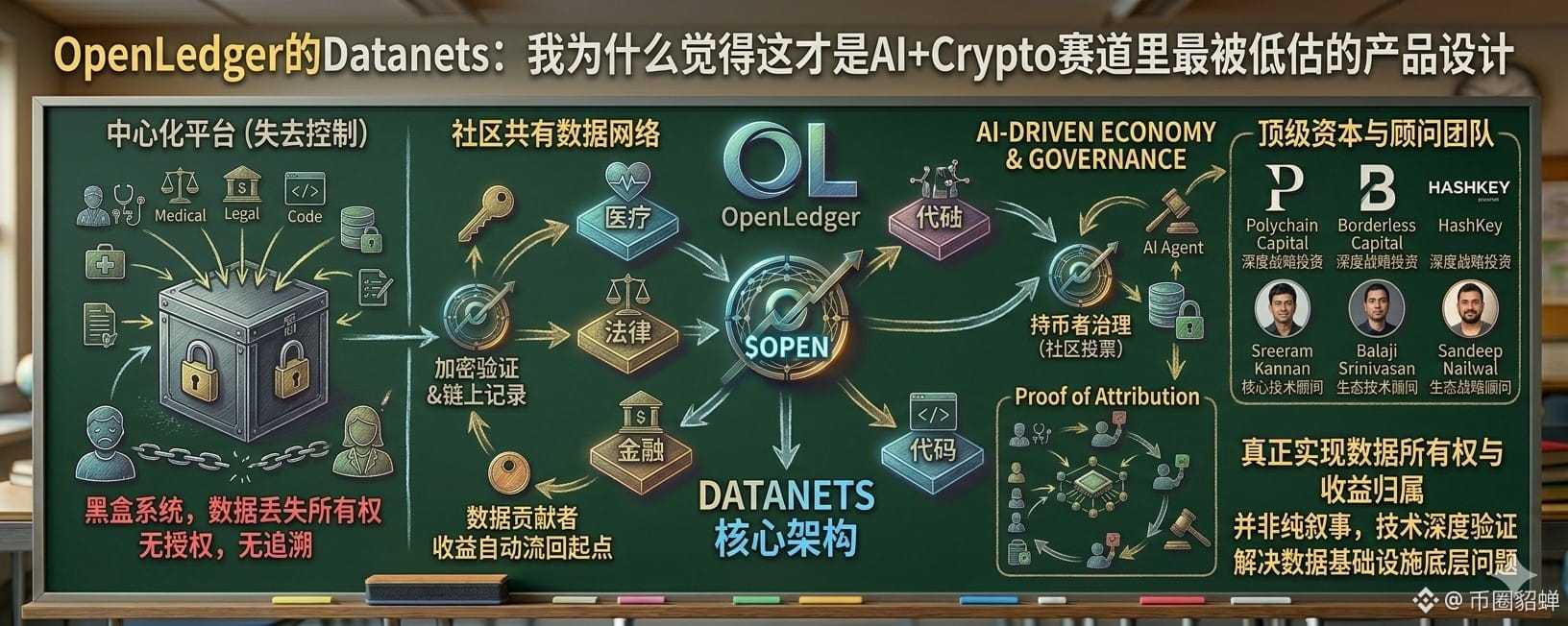
Ho seguito @OpenLedger per un po' di tempo e la maggior parte delle persone che discutono di questo progetto si concentra su Proof of Attribution e sul supporto degli investitori, ma penso che ciò che è davvero sottovalutato sia il design di Datanets.
Ora, il problema dei dati di addestramento dell'AI non è solo 'chi riceve il compenso', ma il problema fondamentale è che 'i dati non appartengono a nessuno sin dall'inizio'. Una volta che carichi contenuti su varie piattaforme, una volta entrati nel sistema, perdi completamente il controllo. La piattaforma utilizza questi dati per addestrare modelli senza che tu lo sappia, senza autorizzazione e senza alcun modo di tracciamento. Questo non è un comportamento malevolo di una singola azienda, ma un problema di design dell'intera infrastruttura dati; le piattaforme centralizzate tendono naturalmente a concentrare la proprietà dei dati.
Il design di Datanets si basa sull'idea che sia una rete di dati della comunità, con ogni Datanet dedicato a un campo specifico, come medicina, diritto, finanza, codice; chiunque può caricare dati e ogni contributo, una volta verificato e crittografato, viene registrato sulla blockchain. La provenienza e la proprietà dei dati sono trasparenti e tracciabili sin dal momento del caricamento.$OPENCome mezzo di regolamento dell'intera catena, garantisce che ogni volta che i dati vengono utilizzati, i ricavi corrispondenti ritornino automaticamente al contribuente originale. Questa logica non è una compensazione postuma, ma blocca la proprietà sin dall'inizio del ciclo di vita dei dati.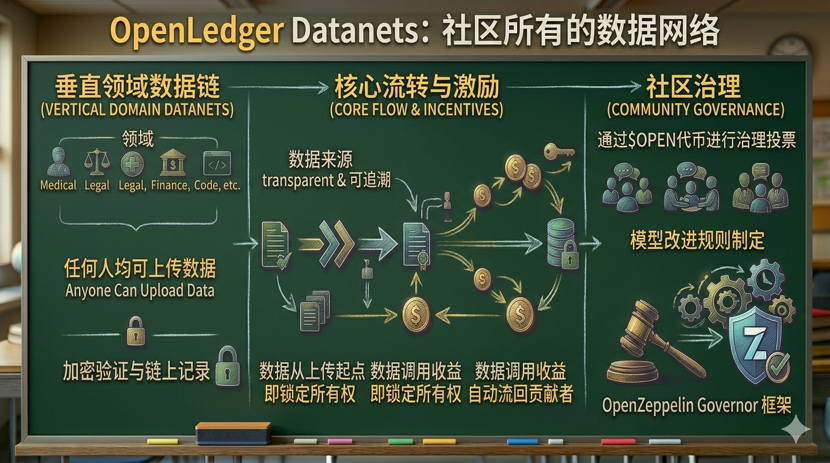
Un aspetto interessante è il design a livello di governance. OpenLedger ha delegato il potere decisionale per l'aggiornamento dei modelli ai governatori che detengono i token, implementando la governance on-chain attraverso il framework modulare Governor di OpenZeppelin; quali modelli sono di qualità adeguata e quali regole di miglioramento sono più ragionevoli, vengono decisi tramite voto della comunità, non da una decisione unilaterale di una singola azienda.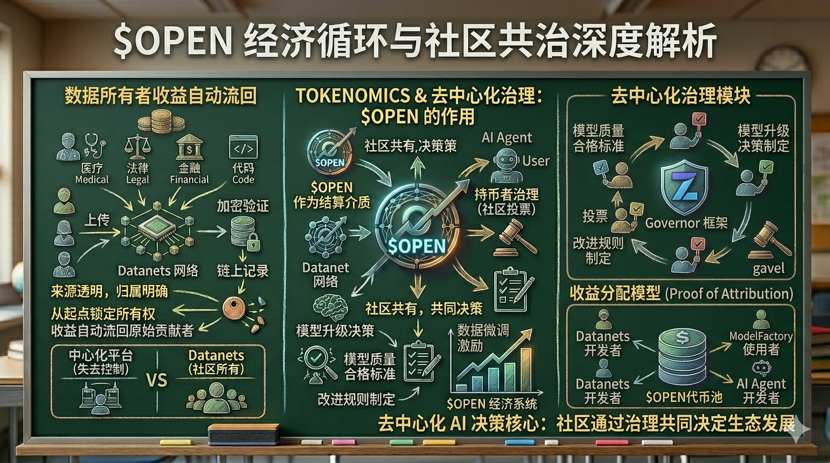 Questo design mi fa pensare che stia seriamente riflettendo su cosa significhi 'decentralizzazione' nel campo dell'AI.
Questo design mi fa pensare che stia seriamente riflettendo su cosa significhi 'decentralizzazione' nel campo dell'AI.
Dal punto di vista tecnico, OpenLedger è costruito su OP Stack come L2, utilizzando EigenDA per la disponibilità dei dati, compatibile con EVM, e AltLayer fornisce supporto RaaS. Questa combinazione ha praticamente nessun costo di migrazione per gli sviluppatori che conoscono la toolchain di Ethereum, ereditando al contempo la sicurezza del sistema di Optimism.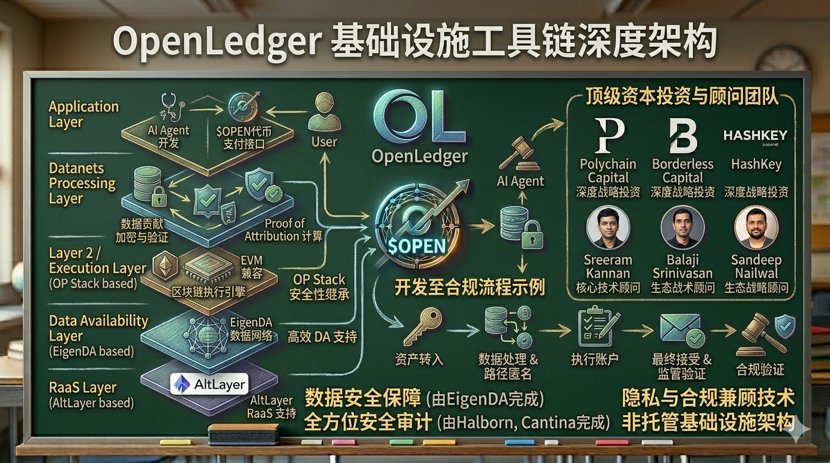
Polychain e Borderless hanno guidato un round di finanziamento di 8 milioni di dollari, con Sreeram Kannan, Balaji Srinivasan e Sandeep Nailwal come investitori angelici; queste persone hanno accumulato un'adeguata esperienza e giudizio in entrambi i campi, AI e blockchain, non sono scommesse a caso.
Credo che il prodotto Datanets risolva problemi più fondamentali di quanto la maggior parte delle persone si renda conto. Non sta ottimizzando il mercato dei dati esistente, ma sta ridefinendo la logica della proprietà dei dati durante l'intero processo dalla loro creazione al loro utilizzo.