
i keep thinking people look at systems like OpenLedger (@OpenLedger ) and their eyes go straight to the sexy parts first. model behavior. inference quality. agent execution. OpenLoRA. maybe OctoClaw if they want to sound extra plugged in. all the places where something visible happens. the answer appears, the inference route activates, OpenLedger settles, some agent does something and everyone suddenly acts like the intelligence part was the whole drama.
but i don’t think that’s the first real bottleneck here.
i think the bottleneck might happen much earlier, in a place people treat like boring prep work.
what actually gets admitted into a Datanet.
that part keeps bothering me more than it should.
because once data gets far enough inside OpenLedger, it stops being random material. it starts becoming future influence. maybe not immediately, maybe not cleanly, maybe not evenly, but still. it enters a system where model paths can touch it later, where Proof of Attribution might remember it later, where a payable inference route might someday drag value across a trail it helped shape. so the admission moment is not just upload logic. it is not clerical. it is not some neutral intake form for information.
it is the point where the system decides what is allowed to become future PoA-visible influence.
and that sounds dramatic, maybe, but is it wrong? or is that actually the cleanest way to say it?
because if bad data gets admitted too easily, then the rest of the architecture inherits that weakness in a much harder-to-remove form. not just as noise in one dataset. as upstream permission. as allowed influence. as something that now has a path toward future attribution and future OpenLedger settlement if it survives far enough. and once that happens, the problem is no longer just “is the model smart enough to ignore weak data?” now the problem becomes why did the system let weak data enter a Datanet memory layer that later becomes settlement-visible at all?
that feels heavier to me.
old AI barely cared about this in a disciplined way, at least not publicly. data got scraped, absorbed, blurred together, and if the model came out strong enough the market mostly forgave the mess underneath. quantity performed like quality for a long time because the black box could hide the intake problem. maybe the data was stale, sloppy, biased, repetitive, structurally uneven, contaminated by junk, who knows. the model answered anyway. everyone moved on.
OpenLedger cannot fully hide there. or at least it shouldn’t be able to.
because a Datanet is not supposed to be the whole internet wearing a nicer shirt. it is supposed to be selective. curated. narrow enough to matter. specific enough to produce better downstream behavior than generic data soup. but the second you say curated, now somebody has to decide what gets in. and the second somebody decides that, we are no longer talking only about data quality. we are talking about threshold design. admission design. exclusion design. who gets filtered out and why. what the system considers “clean enough” or “useful enough” or “structured enough” to deserve a shot at future PoA visibility and future payable inference relevance.

that’s not passive.
that’s the first politics of the whole architecture.
and honestly i think people underestimate how much gets decided right there. because later on everybody wants to argue about inference quality and payout fairness and weighting and routing and all the loud moving parts. fine. but if the intake surface is weak, then all those later arguments are already contaminated. the model may still look smart for a while. the payout layer may still look fair for a while. Proof of Attribution may still look elegant for a while. but elegance downstream does not undo weakness upstream.
“garbage with receipts is still garbage.”
that line keeps sitting there in my head.
and maybe that is the ruder version of the whole thing.
because if OpenLedger is serious about turning data into an asset, then admission is the moment where it decides whether that asset has any right to exist inside the economy it’s building. not whether it has vibes. not whether it sounds relevant. whether it deserves entry into a system where later influence can become traceable and later traceability can become payment. that is much stricter than just asking whether a dataset looks interesting.
and what even qualifies as admission here? that’s where my head starts looping. is it cleanliness? rarity? verification? freshness? specificity? consistency across samples? usefulness for a particular domain? maybe all of it. maybe none of it cleanly. maybe one Datanet values edge-case depth and another values standardized structure and another values high-frequency updates and another values narrow expert curation. alright. but then the bottleneck gets even stranger because now “good data” is not one thing. it is contextual. a moving target. one Datanet’s treasure is another Datanet’s clutter.
so who decides? and based on what? and how much of that decision survives later, quietly, inside the model route?
that’s the real part.
because the admission threshold does not just shape what gets stored. it shapes what becomes trainable, what becomes callable, what becomes payable, what becomes legible enough to receive attribution later. it decides what kind of future is possible for the model layer before the model layer even starts pretending it is the star. it decides what Datanets can later make PoA-legible, what model routes can later train or infer through, what OpenLoRA can later specialize from, what OctoClaw-guided agents can later act on, what OpenLedger can later settle around.
“the first filter may already be the first model.”
that thought keeps following me.
that is why i keep coming back to this. people talk about model performance like performance is where seriousness begins. but performance is already downstream of taste, discipline, and exclusion. especially in OpenLedger. if the Datanet layer does its job badly, the rest of the stack is forced to spend energy recovering from a mistake that should have been stopped at the door.
and sometimes recovery itself creates new distortions. a base model may overcompensate. an OpenLoRA specialization may narrow too hard because the upstream signal is weak. an agent may still execute confidently because the output looks coherent enough. then later everyone stares at the model route or the action route and asks where things broke. maybe they broke earlier than that. maybe they broke at admission and simply stayed hidden long enough to wear nicer clothes downstream.
that possibility feels very OpenLedger-native to me. too native, honestly. because where else would the quietest mistake become future attributable influence this neatly?
because in a system built around Datanets, “what got admitted?” is not some side question. it may be the most load-bearing question in the entire stack. if a Datanet is supposed to act like a high-quality selective memory instead of a generic pile, then admission policy is basically the constitution of that memory. what enters. what gets rejected. what gets deprioritized. what survives long enough to shape models. what is left outside economic memory completely.
that last part matters too.
because exclusion sounds harsh until you remember inclusion has consequences. if everything gets admitted, nothing is really curated. if nothing is filtered, then Datanets risk becoming just better-branded accumulation. and if that happens, OpenLedger starts drifting back toward the same old AI disease, just with prettier receipts and token settlement layered on top.
that would be very stupid.
because the whole point is not to make bad intake more traceable. the point is to make intelligence less dependent on undisciplined ingestion in the first place. not perfect, obviously. no data system gets purity. but discipline matters. maybe more than almost anyone wants to admit because discipline is unglamorous. nobody celebrates the rejected row, the refused contribution, the boring validation threshold, the reason a weak sample never made it far enough to claim future relevance. but that is exactly where architecture proves it has standards instead of slogans.
“the cleanest payout route might begin with a rejection.”
i keep feeling that one.
and then there is the economic side, which makes the whole thing uglier in a useful way. because once contribution can lead to OpenLedger later, admission stops being just a technical gate. it becomes an incentive surface. people will try to get in. they will shape submissions around what the Datanet seems to reward. they will learn the texture of acceptance. they will optimize for it. some of that is healthy. some of that will absolutely become gaming. which means the admission bottleneck is not static. it gets pressured over time by the very economy OpenLedger is trying to create.
so the system has to be strict enough to resist fake usefulness, but open enough not to choke real contributors. narrow enough to protect downstream quality, but flexible enough not to freeze the data economy into one sterile idea of value. good luck. genuinely. that is not a small balancing act. and it is probably more important than one more conversation about whether the answer quality improved by three percent somewhere downstream.
because downstream quality can become a vanity metric if upstream discipline erodes.
and i think that is the trap. people love talking about AI systems at the point where intelligence becomes visible. the answer, the agent, the execution, the payout. but visible intelligence is often just the last phase of a long upstream sorting process. OpenLedger, if it is really what it says it is, should force us to care more about the sorting than we are used to. especially the first sort. dataset admission. the first yes. the first no. the first decision that says this information deserves to enter a Datanet memory layer that can one day shape inference, attribution, and settlement.
what is more important than that, really? and i mean really, inside this stack, not in some nice abstract AI thread.
not in marketing language. in system language.
because once admitted, data becomes harder to treat like a temporary thing. now it can sit inside a Datanet. now it can help train or narrow. now Proof of Attribution can eventually remember its role. now the economic story may form around it later through a payable inference route. that is a lot of future pressure attached to one upstream permission moment. maybe too much, which is exactly why the bottleneck matters.
“entry is already a forecast.”
i don’t think OpenLedger’s real challenge is just proving that data mattered later.
i think the harder challenge is deciding what deserves the chance to matter at all.
that is colder. also more honest.
and maybe that is what keeps pulling me back here. the present version of AI still loves pretending intelligence begins at output. maybe OpenLedger only works if it becomes much harsher earlier than that. at admission. at intake. at the place where weak data asks to become future influence and the system has to decide whether to let it in.
because once it gets in, everything downstream has to live with that decision. everything. the model route, the specialization layer, the agent action, the payout logic. all of it.
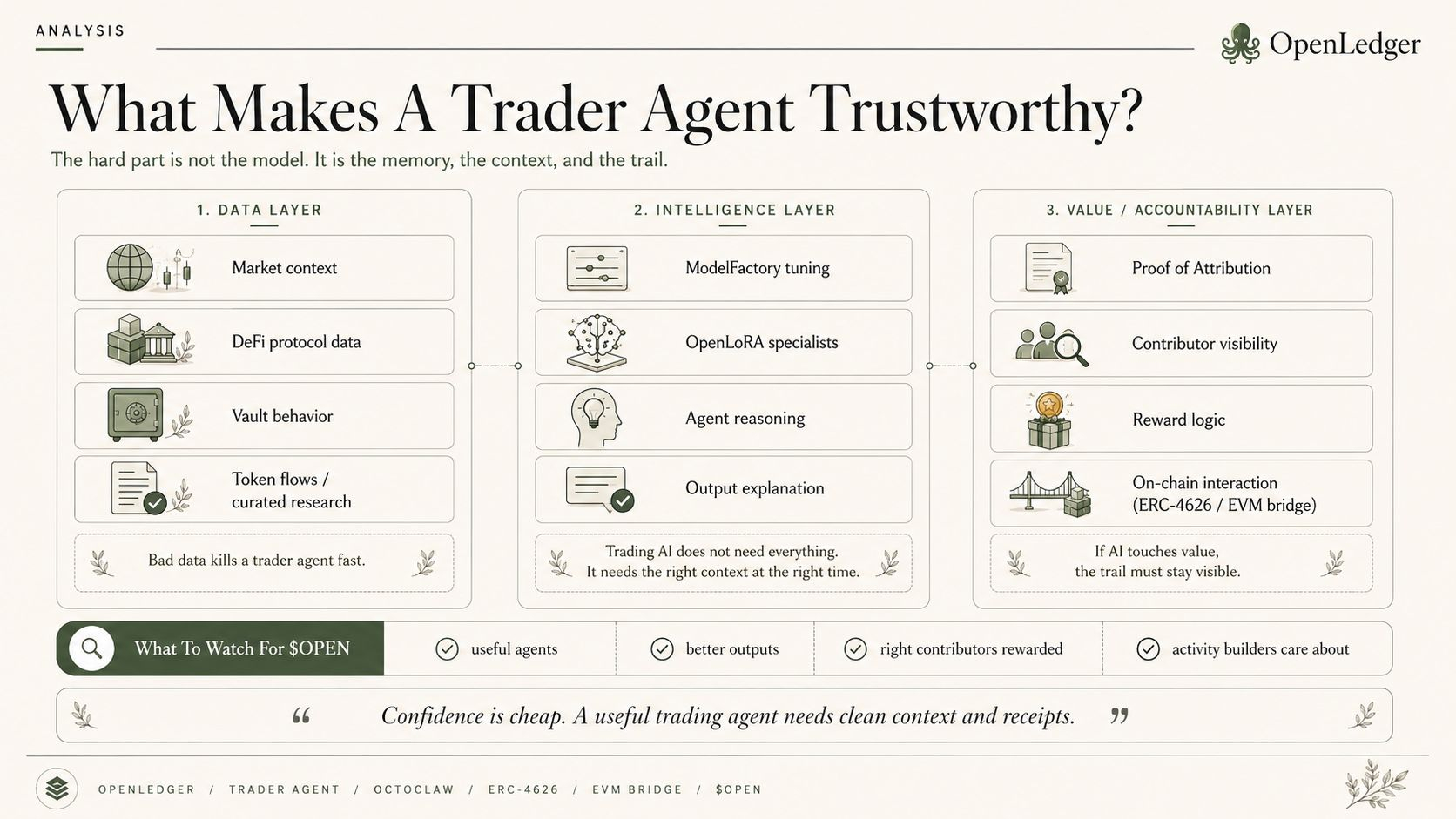
and if OpenLedger gets that upstream bottleneck right, then the rest of the architecture has a chance to mean something. Datanets stay meaningful. model paths stay cleaner. OpenLoRA specialization bends something worth bending. agents execute on top of less polluted memory. Proof of Attribution traces something that deserved to survive the first gate. OpenLedger settlement happens around influence that had some right to become visible in the first place.
if it gets that part wrong, then everybody can still talk about models and routing and attribution and OpenLedger ($OPEN ) movement all day.
but the rot started earlier.
and the whole stack just learned how to settle it.