Data should not disappear after it makes AI useful. That thought stayed with me because OpenLedger is trying to answer a problem that sits under almost every serious AI conversation.

I see OpenLedger as an attempt to make AI data visible after it enters the machine. Most people notice the final answer. They notice the model name. They notice the speed and polish of the output. I keep looking at the quieter layer beneath it. Who contributed the data. Which dataset shaped the answer. What proof exists after the model has already used that information.
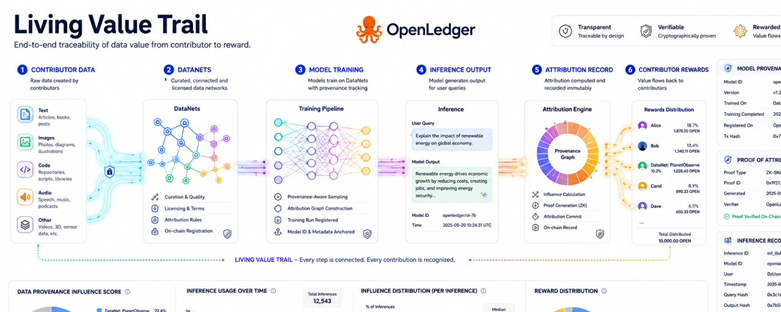
This is where Proof of Attribution becomes the center of the project for me. I understand it as a framework that connects model behavior back to the data that influenced it. That matters because AI contribution is usually hidden from the outside. A contributor may provide useful domain data. A model may train on it. Later an inference event may produce a valuable output. Without attribution that contribution becomes almost impossible to see.
OpenLedger tries to solve this through DataNets. I see a DataNet as more than a dataset. It is a structured onchain data container built around a focused domain or task. That focus is important because specialized AI does not become strong through volume alone. It needs relevant data with context and provenance. A model built for a serious domain needs data that can be checked and traced rather than data that simply exists in the background.
The official paper describes DataNets as community contributed datasets with metadata and records. That detail matters to me. A contribution is not only content. It can include contributor identity upload time license terms preprocessing status and quality signals. This turns raw information into an attribution ready record. I think that is one of the project’s strongest ideas because it gives data a memory before it reaches the model.
The flywheel starts when contributors add focused data into DataNets. Models can then train with recorded provenance. Inference activity produces new evidence of use. Proof of Attribution can identify which data had influence. Rewards can then move toward contributors based on measured impact. I like this structure because it shifts attention from simple participation to actual usefulness.
My strongest view is that OpenLedger is trying to turn data from a silent input into a living value trail. That phrase matters to me because the data does not end at upload. It can remain part of the economic story each time it helps shape a model output. If this works then contributors are not only suppliers. They become part of an ongoing AI value chain.
The practical market logic is clear. Model builders need better data. Contributors need better incentives. Users need more trust. OpenLedger tries to connect these needs through attribution. If builders can inspect which DataNets helped train a model then they can make better decisions. If contributors can see how their data is used then they can focus on quality. If users can see that outputs have traceable roots then trust becomes easier to discuss in concrete terms.
I also think this is where the market may misunderstand OpenLedger. The project is not only about rewards. Rewards are important but they depend on something deeper. The real issue is proof. A reward system without credible attribution becomes weak. A data market without provenance becomes noisy. A model ecosystem without usage records becomes hard to trust. OpenLedger is trying to build the proof layer first.
The technical side also shows why the problem is difficult. The paper discusses influence based methods for smaller specialized models and Infini gram style attribution for larger language models. I do not treat that as a small detail. It shows that one attribution method may not fit every model size. Smaller models and larger models need different ways to trace influence. That makes execution harder but also more serious.
I still see real risk. Attribution must be accurate enough for contributors to trust it. DataNets must stay high quality. Model builders must actually use them. Inference demand must create enough activity for the reward loop to matter. If any part is weak then the flywheel slows down. This is why I would not judge OpenLedger only by its concept. I would judge it by usage and records.
The short term value of OpenLedger is that it gives AI data a clearer structure. It says data should be registered and traced and connected to outcomes. The long term value depends on whether that structure becomes reliable infrastructure. That is the difference between a strong idea and a working market.
I think the title question is fair. Can OpenLedger turn AI data into a living value trail. My answer is cautiously positive. The project has a relevant thesis because specialized AI needs verified domain data and fairer attribution. The challenge is proving that the system can work with real models real inference activity and real contributors.
My final note is simple. I am watching real usage attribution quality and execution.
