Ieri ho passato alcune ore strane in cui continuavo a leggere opinioni sull'AI decentralizzata e sentivo che qualcosa non andava in tutte quelle discussioni, ma non riuscivo a capire esattamente cosa. Tutti descrivevano la stessa visione generale — AI che non vive sui server di una singola azienda, calcoli distribuiti su reti, nessun punto di fallimento singolo. Ho annuito a quella narrazione così tante volte che avevo smesso di esaminarla realmente. Poi ho passato del tempo con OpenLedger e finalmente qualcosa si è incastrato, ma non in modo confortevole.
La cosa che continuavo a notare mentre esaminavo come $OPEN struttura realmente il suo approccio — specificamente il livello in cui i dati vengono attribuiti, sorgenti e convalidati prima di alimentare qualsiasi modello — è che OpenLedger non sta costruendo principalmente attorno al calcolo distribuito. Sta costruendo attorno al giudizio distribuito. E mi sono reso conto che avevo confuso queste due cose per molto tempo senza accorgermene.
Ecco cosa intendo, e perché è più importante di quanto sembri.
Il calcolo distribuito significa che l'IA gira in molti posti invece di uno. È reale e ha benefici reali — resilienza, struttura dei costi, resistenza alla censura a livello infrastrutturale. Ma l'intelligenza — significa cosa sa il modello, cosa considera valido, cosa è stato addestrato a ottimizzare — può ancora essere completamente centralizzata anche se i server sono distribuiti su mille nodi. Puoi decentralizzare l'hardware perfettamente e avere ancora un'entità che decide cosa conta come buona informazione, cosa viene inclusa nei dati di addestramento, quale conoscenza è valida e quale viene filtrata. Il calcolo è distribuito. Il giudizio non lo è.
Ciò su cui #OpenLedger sembra lavorare è la versione più difficile di questo problema. Non dove gira l'IA, ma chi decide cosa impara l'IA. Il livello di attribuzione e sorgente che continuavo a guardare non è solo un pipeline di dati — è un tentativo di distribuire l'atto di decidere cosa è credibile, cosa è prezioso, cosa merita di far parte delle fondamenta di un sistema di IA. È una cosa completamente diversa dalla deduzione distribuita.
E pensavo che fosse ovviamente positivo. Poi ho continuato a riflettere.
Ma ecco la parte che mi infastidisce davvero di questa situazione.
Distribuire il giudizio sembra meglio che concentrarlo, fino a quando non chiedi cosa produce realmente il giudizio distribuito su scala. I mercati distribuiscono il giudizio di prezzo tra milioni di partecipanti, e i mercati continuano a sbagliare gravemente per periodi prolungati. Le democrazie distribuiscono il giudizio politico, e le maggioranze democratiche hanno preso decisioni terribili costantemente nella storia. Distribuire una funzione cognitiva non migliora automaticamente la qualità di quella funzione. Cambia chi ha il potere su di essa, il che è importante, ma non garantisce che il risultato sia più accurato o più equo.
@OpenLedger sta costruendo infrastrutture per qualcosa di genuinamente nuovo, ma l'assunzione che il giudizio decentralizzato produca una IA migliore è ancora un'assunzione. Non è stata testata su scala significativa da nessuna parte. La speranza è che molti contributori indipendenti con prospettive varie producano una base di IA più ricca e bilanciata di un piccolo team in una sola azienda. È un'ipotesi ragionevole. Non sono solo convinto che sia stata dimostrata, e noto che la maggior parte dell'entusiasmo attorno all'intelligenza decentralizzata la tratta come ovvia piuttosto che come qualcosa che deve ancora essere provata.
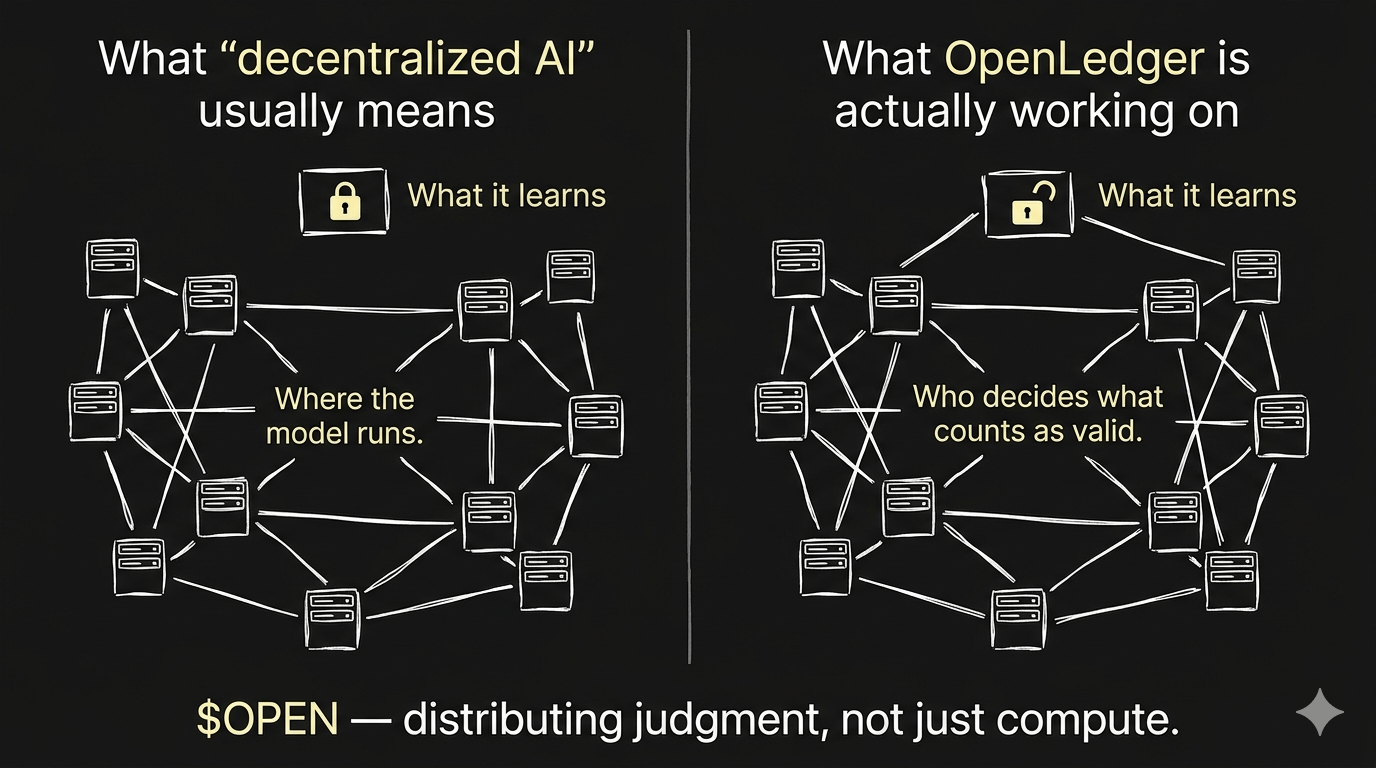
C'è anche la questione di cosa succede quando il giudizio distribuito produce un risultato che è sicuramente sbagliato. I sistemi centralizzati falliscono in modi visibili e tracciabili — puoi indicare l'organizzazione che ha fatto la cattiva scelta. I sistemi distribuiti possono produrre fallimenti di consenso che sono più difficili da attribuire e più difficili da correggere perché non c'è un singolo attore contro cui opporsi. Non ho visto una risposta chiara a questo da parte di nessuno in questo spazio.
Nessuna di queste cose significa che la direzione sia sbagliata. Penso davvero che il problema a cui OpenLedger sta puntando — il giudizio centralizzato incorporato nei sistemi di intelligenza artificiale che appaiono neutri — sia una delle questioni irrisolte più importanti nello sviluppo dell'IA. Il fatto che sia difficile da risolvere non significa che non debba essere tentato. E $OPEN è uno dei pochi progetti che ho incontrato che sembra lavorare sulla distribuzione del giudizio piuttosto che solo sulla distribuzione del calcolo, il che almeno è la diagnosi giusta.
Penso solo che le persone che costruiscono in questo spazio e quelle che lo osservano sarebbero meglio servite trattandolo come un esperimento aperto piuttosto che come un'architettura risolta.
Comunque. I grafici sono laterali, nulla si muove, e ci ho pensato troppo per due giorni. Probabilmente mi allontanerò dallo schermo per un po'.