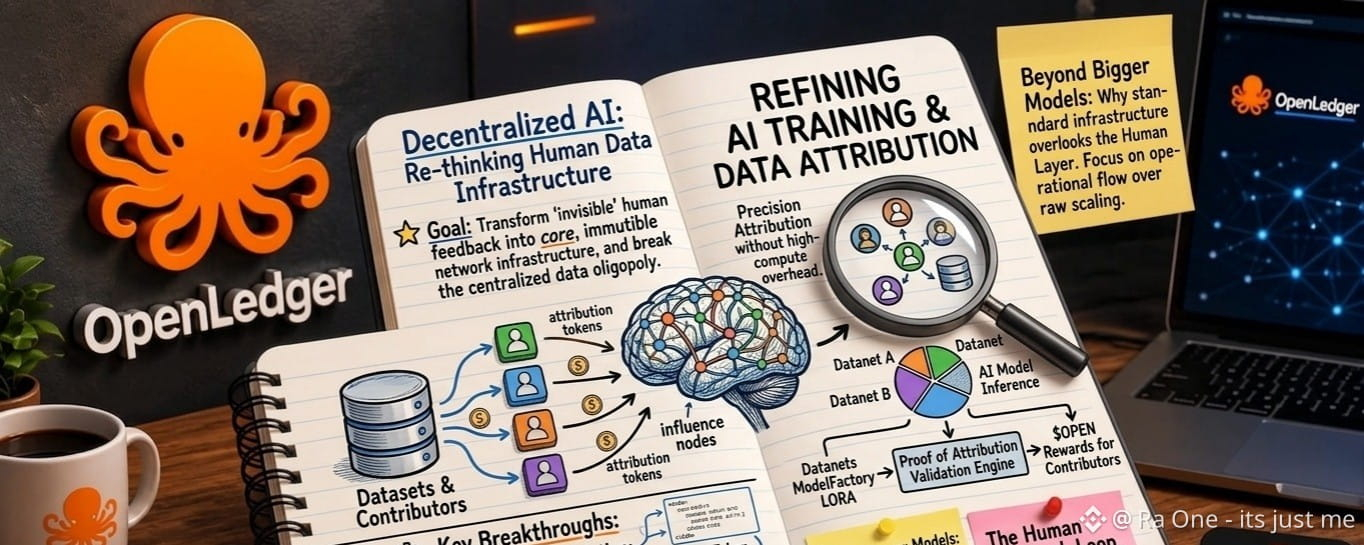
Artificial intelligence development remains structurally gatekept by centralized data oligopolies. While standard infrastructure protocols aggressively focus on raw physical scaling such as optimizing graphic processing units and horizontal compute layers the broader industry frequently miscalculates the long-term value of the underlying data supply chain. OpenLedger shifts the paradigm by treating structured human feedback and data curation not as ephemeral inputs, but as core, immutable network infrastructure.
The persistent issue with mainstream artificial intelligence lies in its execution. Centralized platforms scale by relying on massive, crowdsourced feedback systems to refine large language models, correct inferences, and minimize algorithmic drift. However, the value loop remains fundamentally broken. The individual contributors who actively train these systems are treated as invisible, uncompensated participants, while the platform absorbs the entire commercial capture. OpenLedger addresses this explicit design flaw by bringing the entire artificial intelligence lifecycle on chain.
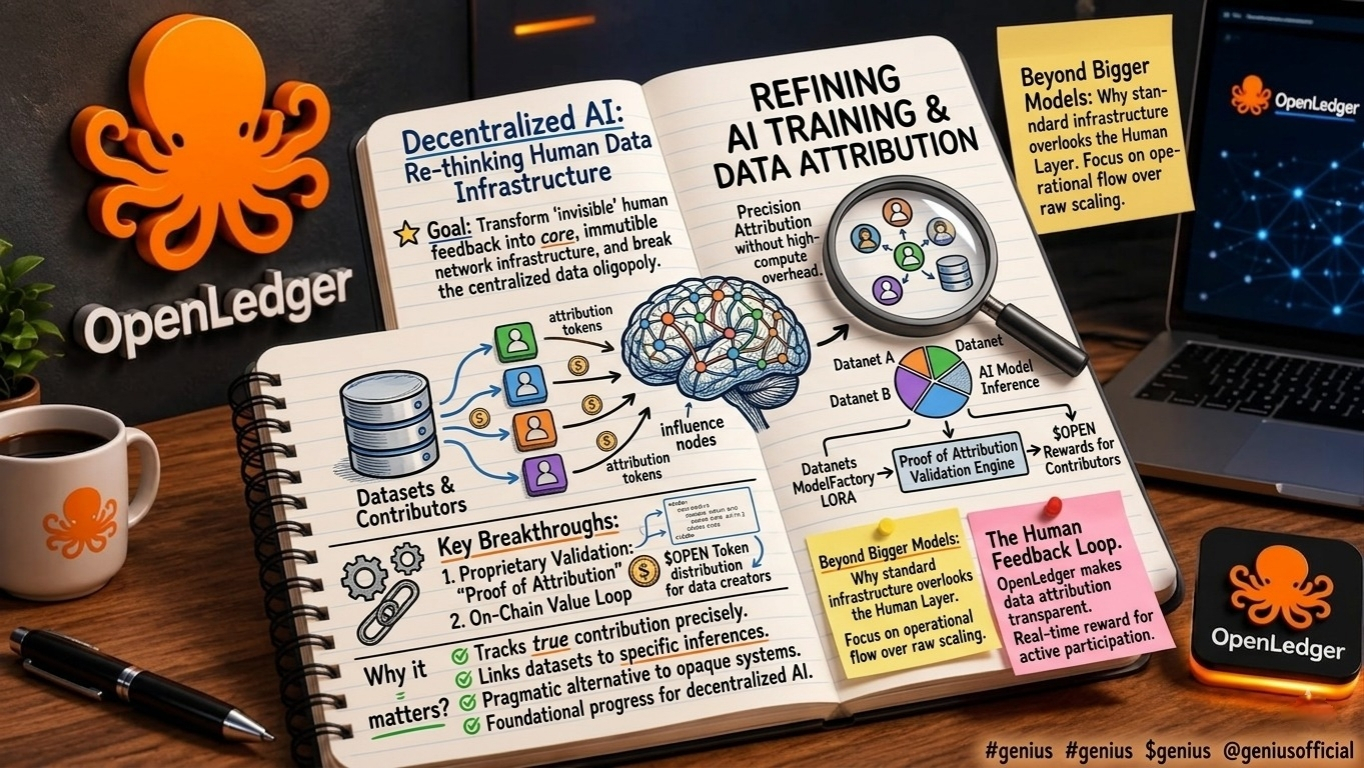
Through an EVM compatible layer 2 architecture, the platform introduces a decentralized model for custom artificial intelligence production. This framework operates via localized data collaboration networks called datanets, alongside a specialized no-code fine-tuning environment known as model factory. The critical breakthrough is a proprietary validation engine: proof of attribution. Rather than allowing data contributions to lose identity post-training, proof of attribution tracks exactly which datasets influence specific model inferences. When a user executes a query, the system mathematically calculates data influence, linking back to the origin. This allows real-time value distribution to the creators of the underlying datasets using the native token, $OPEN.
Furthermore, the integration of an open Lora framework optimizes resource allocation. It enables thousands of fine-tuned low-rank adaptation models to run simultaneously on a single graphics processing unit via dynamic, just in time adapter switching. This reduces deployment overhead by nearly ninety percent, mitigating the infrastructure bottlenecks that traditionally restrict independent developers. By lowering financial barriers to entry, the architecture balances the distribution of computational power with transparent data ownership.
However, the real test for this decentralized model remains operational execution. Systemic challenges persist around subjective data verification and metric exploitation. Quantifying human feedback objectively is inherently complex. When economic incentives are tied directly to data input, protocols face the persistent threat of reward-chasing and synthetic sybil data replication, which can quickly degrade model accuracy. Maintaining strict quality filters and robust verification layers without re-introducing centralization remains an active challenge.
Despite these structural hurdles, the project introduces a highly pragmatic approach compared to the hyper-speculative narratives common across the intersection of Web3 and artificial intelligence. By acknowledging human interaction as a primary, foundational infrastructure resource equivalent to compute networks or electricity the protocol provides a tangible alternative to opaque, corporate-dominated systems. If the network can successfully scale its proof of attribution model without compromising data integrity, it will fundamentally redefine data attribution and capital efficiency across decentralized networks. Foundational progress in artificial intelligence is not merely about constructing larger, isolated models; it requires structural transparency across the human layer that underpins them.