
L'anno scorso ho letto uno studio che stimava che il costo per addestrare GPT-4 fosse di circa 100 milioni di USD. Quel numero è stato condiviso ovunque come prova che l'AI è un gioco per i ricchi. Ma poi ho guardato il numero reale, che è molto più spaventoso: il costo per far funzionare GPT-4 ogni giorno dopo che è stato addestrato. Costo di inferenza. E questo è ciò su cui @OpenLedger sta scommettendo che possono risolvere in un modo completamente diverso rispetto a tutto ciò che il mercato sta facendo.
La maggior parte delle persone quando pensa ai costi dell'AI pensa all'addestramento. Ma l'addestramento avviene una sola volta, o poche volte. L'inferenza avviene miliardi di volte al giorno. Ogni volta che digiti un prompt in ChatGPT, quella è una chiamata di inferenza. Ogni volta che un'app utilizza l'AI per raccomandarti un prodotto, quella è una chiamata di inferenza. Il vero costo dell'economia AI non si trova nel giorno in cui si allena il modello per la prima volta. Si trova nel costo di eseguire quel modello ogni secondo, ogni minuto, per sempre.
E qui sta il problema. Se hai un milione di modelli AI specializzati per un milione di domini diversi, dalla salute alla legge, dalla finanza alla musica, ogni modello avrà bisogno di un server dedicato, il costo diventerà un problema senza soluzione dal punto di vista economico. Questo è il motivo per cui la maggior parte delle startup AI utilizza solo uno o due modelli base e poi fa un leggero fine-tuning, anziché creare modelli realmente specializzati. Non perché i modelli specializzati non siano migliori. Ma perché servirli è troppo costoso.
OpenLoRA di OpenLedger è la risposta a questo problema, ed è qualcosa che vedo analizzato da pochi. OpenLoRA utilizza una tecnica chiamata adattatore LoRA, ovvero Low-Rank Adaptation, un modo per ottimizzare il modello addestrando solo un piccolo strato di adattatore sopra il modello base anziché riaddestrare tutto, e caricare questi adattatori just-in-time quando arriva una richiesta di inferenza. Questo consente a una sola GPU di servire migliaia di varianti di modelli specializzati cambiando adattatore in microsecondi anziché avviare un nuovo server. Sembra una tecnologia avanzata. Ma pensalo in questo modo.
Un ristorante normale che vuole servire 100 piatti ha bisogno di 100 cuochi. OpenLoRA è la cucina dove un cuoco super esperto può preparare 100 piatti cambiando salse e spezie senza dover cambiare l'intero forno. I costi diminuiscono in proporzione senza compromettere la qualità dell'output.
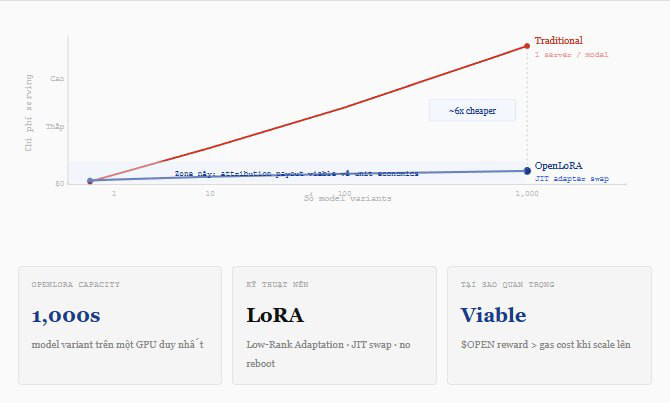
Perché è importante per il token $OPEN? Perché l'intera tesi di OpenLedger dipende da una cosa: ogni chiamata di inferenza deve poter restituire una ricompensa al contribuente di dati che sia superiore al costo per effettuare il pagamento. Se servire 1.000 modelli è troppo costoso, allora la ricompensa per inferenza sarà troppo bassa per coprire le spese. OpenLoRA non è solo una funzione aggiuntiva per farsi belli. È una condizione necessaria affinché l'intera economia AI attribuita possa esistere dal punto di vista finanziario.
Ma qui voglio essere onesto riguardo ai rischi di cui pochi parlano apertamente. OpenLoRA risolve il costo del servizio, ma non risolve il costo del calcolo dell'attribuzione, ovvero il costo per calcolare quali dati influenzano quali output. Il whitepaper PoA di giugno 2025 descrive due approcci: funzione di influenza per modelli piccoli e attribuzione di token con array di suffissi per LLM grandi. Entrambi sono approssimazioni, ovvero stime e non esattezze assolute, e il costo di calcolo non è ancora stato benchmarkato in modo sufficientemente chiaro su scala di produzione.
Immagina di aprire un ristorante con un cuoco talentuoso e una cucina super efficiente, ma dopo ogni pasto devi sederti a tracciare quanti grammi di ogni ingrediente ha mangiato ogni cliente per calcolare quanto pagare a ciascun fornitore. La cucina è efficiente. Ma il sistema di contabilità degli ingredienti è ancora molto costoso.
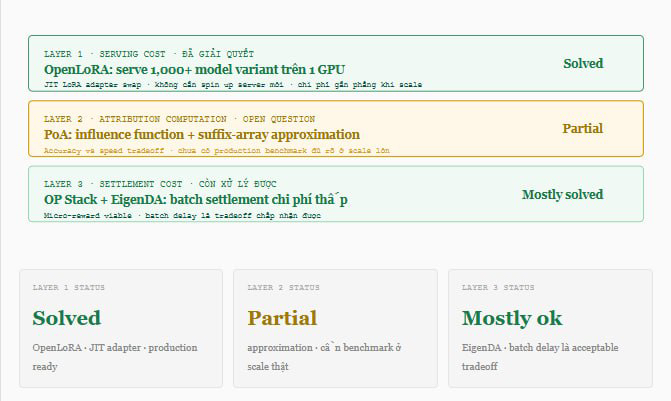 Guardando a quei tre livelli, penso che la storia di$OPEN non sia la storia di una tecnologia nuova e strana. Questa è la storia di riuscire a risolvere contemporaneamente tre problemi di costo mentre un numero sufficiente di sviluppatori esterni ha fiducia per costruire applicazioni su questa infrastruttura o meno. Risolvere uno o due problemi senza il terzo significa che il sistema non funzionerà. E risolvere tutti e tre in un laboratorio senza che nessuno sviluppatore lo utilizzi non ha senso.
Guardando a quei tre livelli, penso che la storia di$OPEN non sia la storia di una tecnologia nuova e strana. Questa è la storia di riuscire a risolvere contemporaneamente tre problemi di costo mentre un numero sufficiente di sviluppatori esterni ha fiducia per costruire applicazioni su questa infrastruttura o meno. Risolvere uno o due problemi senza il terzo significa che il sistema non funzionerà. E risolvere tutti e tre in un laboratorio senza che nessuno sviluppatore lo utilizzi non ha senso.
Ricordo la storia di Ethereum nel 2016 e 2017. I contratti intelligenti erano qualcosa che nessuno capiva perché fossero necessari fino a quando non avvenne il DeFi summer nel 2020 e tutti improvvisamente videro il caso d'uso. OpenLedger potrebbe essere in una fase simile, dove l'infrastruttura è in costruzione ma il caso d'uso killer non è ancora arrivato. La differenza è che Ethereum aveva una generazione di sviluppatori realmente intenzionati a costruire applicazioni decentralizzate per motivi ideologici. OpenLedger ha bisogno di clienti aziendali che costruiscano per motivi finanziari, per conformità, per rischio di causa legale. Questo è un tipo di adozione diversa e spesso molto più lenta.
Ciò che mi interessa di più non è lo stack tecnologico di OpenLedger. È la velocità con cui il volume delle transazioni della mainnet sta aumentando da novembre 2025 ad oggi. Se quel numero sta aumentando rapidamente ogni mese, i tre livelli di costo stanno venendo convalidati dal mercato. Altrimenti, dovrò aspettare ancora per vedere se l'economia AI attribuita riesce davvero ad arrivare nella finestra in cui la tokenomics di $Open è ancora sostenibile.
Quanto pensi che l'attribuzione AI diventerà uno standard obbligatorio, e quale sarà il trigger che porterà all'adozione reale da parte delle imprese?