
Non mi piace il modo in cui molti confrontano OpenLedger con GPT, Claude o Gemini.
Chiedere se "il modello su OpenLedger è intelligente come GPT?" sembra sensato, ma in realtà è una domanda sbagliata.
OpenLedger non ha scelto di costruire un super modello generale per competere direttamente con frontier lab. Il progetto ha optato per un'IA specializzata: molti modelli più piccoli, più ristretti, alimentati da dati di nicchia e dedicati a compiti specifici.
Quindi, se consideriamo la potenza pura, OpenLedger è in svantaggio.
E non solo ha perso leggermente.
Da un lato ci sono i laboratori frontier con budget per data center nell'ordine di decine di miliardi di dollari, il team di ricerca più costoso al mondo, cluster di GPU come infrastruttura nazionale, contratti per chip, contratti per energia, dati enterprise e distribuzione già in mano a enormi cloud.
Da un lato c'è un ecosistema AI x Web3 che è ancora in costruzione.
Non è una corsa tra due corridori.
È come una persona in bicicletta accanto a un treno ad alta velocità.
Quindi se OpenLedger racconta la storia 'creeremo un modello più intelligente di GPT', non ci credo. Quella porta è troppo stretta.
Ma non è nemmeno la storia più interessante.
La porta di OpenLedger si trova nell'AI specializzata. Ma non credo che l'AI specializzata vincerà automaticamente solo perché ha dati di nicchia.
I dati di nicchia non sono sempre un vantaggio. Molte volte sono un debito.
Un modello per la sanità, la finanza, la legge o la sicurezza non ha bisogno solo di dati 'di settore'. Ha bisogno di dati puliti, recenti, verificati, aggiornati e con qualcuno che continui a curarli dopo che l'incentivo iniziale è passato.
Altrimenti, i dati di nicchia sono solo un magazzino morto.
Datanet ha valore solo se non rimane ferma come una directory. Deve essere una rete di dati viva: persone che aggiornano, una storia di contributi, accesso, ricompense, e una domanda reale che porti nuovi dati.
Se ci riesci, i dati di nicchia saranno difficili da copiare.
Altrimenti, è solo materiale in attesa di essere letto da un modello frontier attraverso RAG e utilizzato meglio.
La storia 'modelli piccoli e più economici' non è abbastanza.
Essere più economici ma dimenticati dagli utenti significa comunque fallire.
GPT è potente non solo perché è bravo. È potente perché è diventato un riflesso. Se c'è qualcosa di sconosciuto, apri una chat. Scrivi, programma, ricerca, analizza, leggi documentazione, tutto viene attratto verso un unico punto di partenza.
Quella è la vera potenza del modello frontier: l'abitudine.
Un modello on-chain non deve scrivere poesie meglio di Claude. Un modello di sicurezza non deve comprendere la letteratura. Un modello sanitario non deve scrivere thread su Twitter. Ma deve essere chiamato al momento giusto.
Se il compito inizia sempre da GPT, il modello di nicchia ha già perso dalla porta.
Questo è il rischio più grande per OpenLedger.
Non è che il modello frontier ucciderà l'AI specializzata.
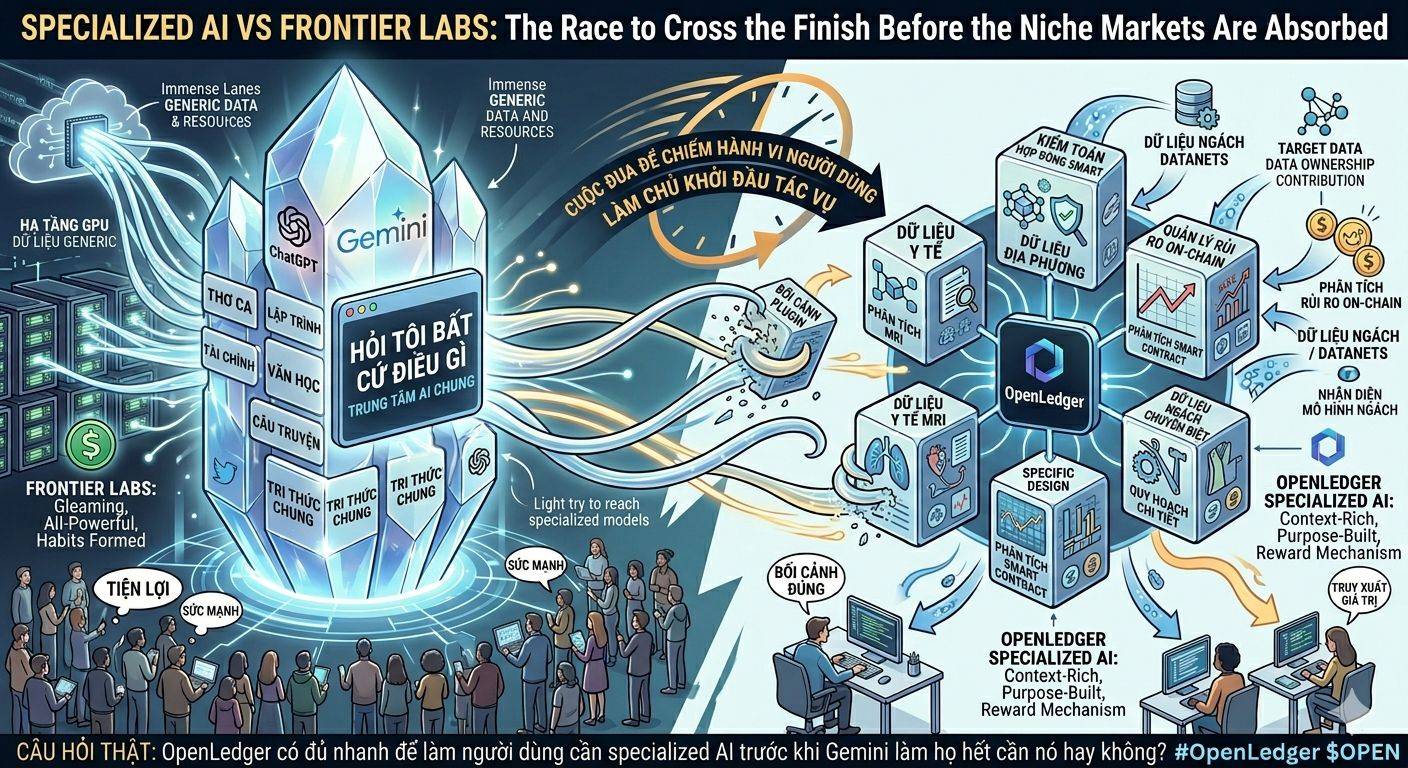
Più pericoloso: il modello frontier trasforma l'AI specializzata in un backend.
I modelli di nicchia continuano a funzionare. I dati di nicchia continuano ad essere utilizzati. Gli adapter esistono ancora. Ma l'utente non lo sa, non lo sceglie, non paga direttamente per esso. Tutto avviene dietro l'interfaccia di GPT, Claude o Gemini.
A quel punto, l'AI specializzata non fallisce per motivi tecnici.
Ha fallito in termini di posizione.
Da prodotto a plugin.
Dal modello scelto al contesto.
Da un 'negozio di AI' indipendente a uno scaffale in un supermercato altrui.
Questa è una cosa che OpenLedger deve evitare.
Se il progetto rimane solo alla fine della catena per registrare, fare log o pagare dopo che l'AI ha finito il lavoro, è troppo tardi. Il valore più sostanzioso si trova spesso dove il compito inizia, dove viene scelto il modello, dove l'utente ripone la prima fiducia.
Perciò OpenLedger deve correre veloce.
Non deve essere veloce come uno spam di funzionalità.
Veloce per catturare il comportamento.
Gli utenti devono abituarsi all'idea che alcune operazioni richiedono un modello più specifico piuttosto che il modello più potente. Gli sviluppatori devono vedere che il modello di nicchia può diventare un prodotto con flusso di cassa se viene chiamato correttamente. Chi contribuisce dati deve vedere che i propri dati non vengono risucchiati in una black box, ma possono creare valore ripetuto.
Ma il modello frontier non rimane fermo.
Stanno diventando sempre più lunghi nei contesti, più bravi nell'uso degli strumenti, migliori nella lettura della documentazione, con ragionamenti più forti e integrati più a fondo nelle aziende. Non devono diventare gli esperti migliori in tutti i settori.
Devono solo essere abbastanza buoni e più pratici.
Gli utenti non scelgono spesso il sistema ottimale. Scegono il percorso con meno attriti. Se GPT è abbastanza buono per la maggior parte delle esigenze e già integrato nel workflow, molti modelli di nicchia non avranno l'opportunità di spiegare perché siano migliori nel resto.
Quindi OpenLedger non perderà se GPT è più intelligente.
Questo è quasi implicito.
OpenLedger perde quando gli utenti non hanno più motivi per lasciare GPT.
O peggio: continuano a usare l'AI specializzata, ma attraverso GPT.
A quel punto OpenLedger potrebbe essere ancora nel backend, ma non controlla più il comportamento, non controlla più la relazione con l'utente e non controlla più la parte di valore più grande.
La domanda più interessante non è se OpenLedger possa tenere il passo con GPT.
La domanda è se OpenLedger possa creare un'abitudine d'uso per l'AI specializzata prima che il modello frontier trasformi ogni nicchia in una funzionalità secondaria.
Se c'è, la differenza di intelligenza grezza non la ucciderà.
Altrimenti, l'AI specializzata continuerà a esistere.
Ma esiste all'ombra del modello frontier.