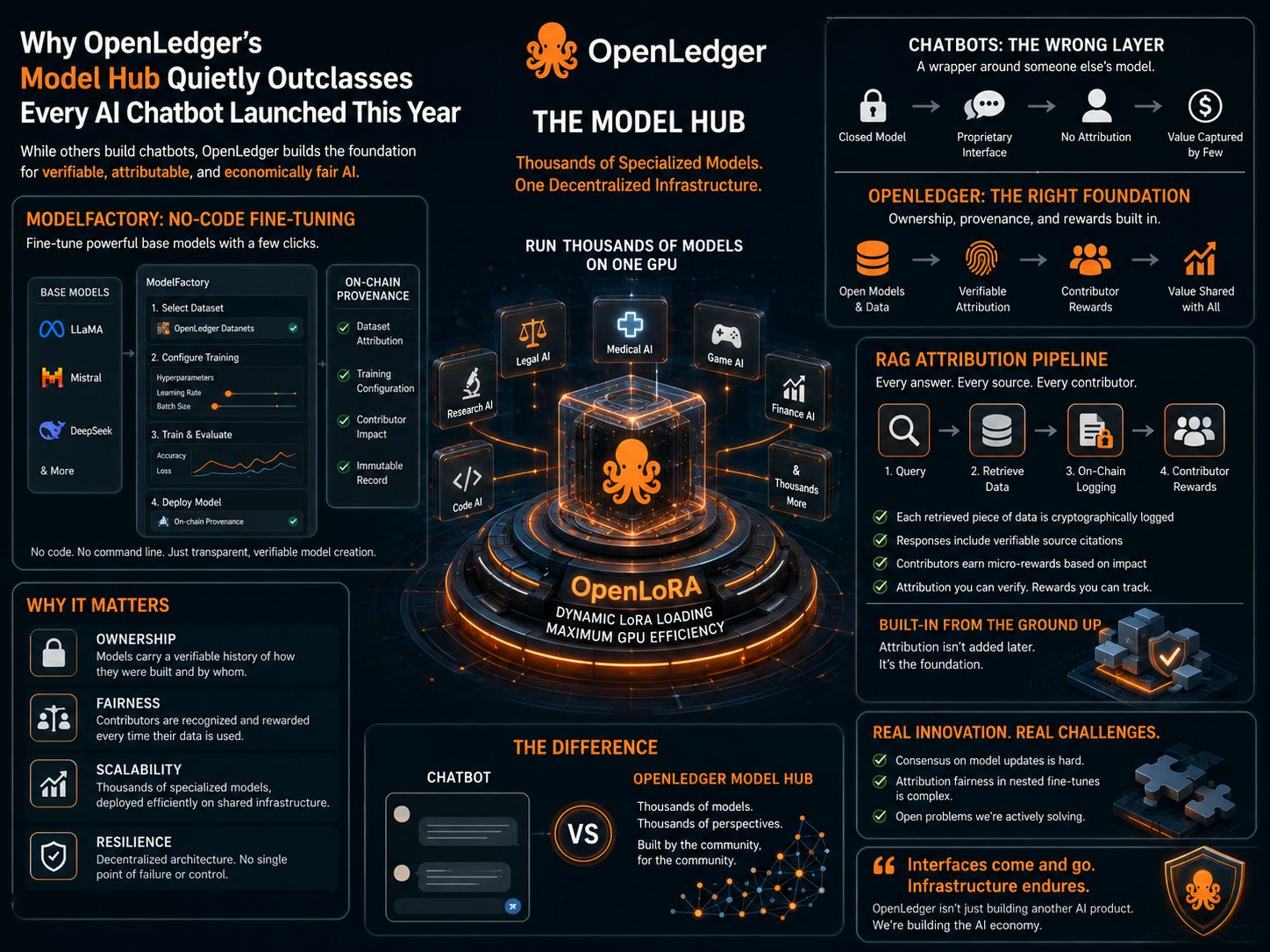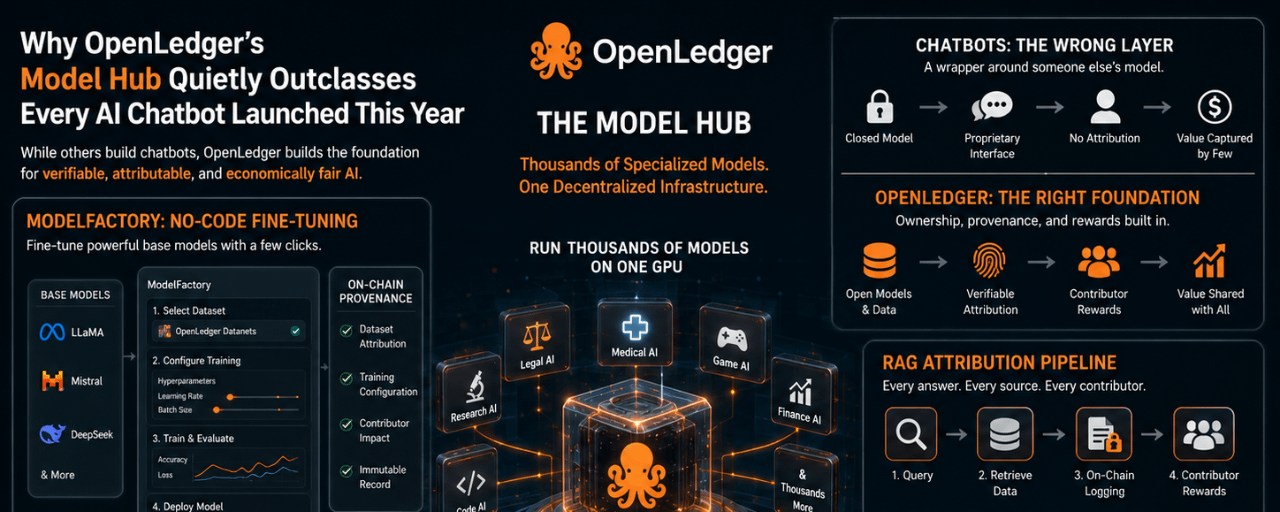
La maggior parte dei modelli hub risolve un problema di distribuzione. Carichi un modello, qualcuno lo scarica, la transazione finisce. L'hub di modelli di OpenLedger risolve qualcosa di diverso: cosa succede alla relazione tra un modello e i dati che lo hanno costruito dopo che l'addestramento è completato?
Quella domanda è architettonica. Inizia all'interno di ModelFactory e non si ferma al deployment.
L'interfaccia di ModelFactory nasconde una complessità significativa dietro un flusso di lavoro grafico che non richiede linea di comando. Un utente seleziona un modello di base da un elenco che include LLaMA, Mistral e DeepSeek. Richiedono quindi accesso a un Datanet specifico, un pool di dataset specifici per dominio dove i contributori hanno caricato e attribuito i loro dati. Questo accesso è autorizzato. I contributori che possiedono dati all'interno di un Datanet stabiliscono condizioni su come vengono utilizzati nell'affinamento. Una volta concesso l'accesso, il dataset si integra direttamente nel flusso di lavoro di addestramento.
Da lì, l'utente configura l'addestramento attraverso un'interfaccia grafica che espone iperparametri come il tasso di apprendimento, la dimensione del batch e il numero di epoche attraverso campi anziché file di configurazione. Il fine-tuning avviene tramite LoRA o QLoRA a seconda delle dimensioni del modello e delle limitazioni hardware, con un cruscotto di analisi in tempo reale che mostra le curve di perdita e le metriche di validazione mentre il lavoro è in corso. L'utente può testare il modello fine-tuned attraverso un'interfaccia chat integrata prima del deployment.
Ciò che è insolito è ciò che viene scritto sulla catena durante ogni passaggio. OpenLedger registra quale Datanet è stato utilizzato, quale versione del dataset, quali scelte di configurazione hanno plasmato l'esecuzione e quali dati dei contribuenti sono stati inclusi. Quel registro non è un file di log su un server. È un'entrata di provenienza on-chain che viaggia con il modello dal momento in cui termina l'addestramento.
Questa è la decisione di design che distingue ModelFactory da ogni altra piattaforma di fine-tuning. La catena di provenienza non termina all'addestramento. Quando il modello viene distribuito tramite OpenLoRA, ogni chiamata di inferenza viene allegata a quella stessa catena. Il sistema sa quale modello ha prodotto un dato output, quale Datanet ha plasmato quel modello e quali contribuenti devono ricevere attribuzione per quell'evento di inferenza. Il modello porta con sé la propria storia in produzione e continua ad aggiornarla con ogni utilizzo.
OpenLoRA rende questo economicamente praticabile su larga scala risolvendo il problema dei costi di distribuzione che altrimenti renderebbero impraticabile un marketplace di modelli specializzati. Il sistema utilizza il caricamento dinamico degli adattatori LoRA: i modelli specializzati non occupano permanentemente la memoria GPU. Si caricano su richiesta quando arriva una richiesta di inferenza e si scaricano quando sono inattivi. Una singola GPU serve migliaia di modelli fine-tuned distinti in questo modo, alternando gli adattatori in base al traffico in entrata anziché mantenere una capacità di servizio dedicata per ciascuno.
Quello che abilita è degno di riflessione. Se il costo di distribuzione per modello si avvicina a zero, la barriera per mantenere un modello specializzato attivo non è il costo hardware ma la qualità del contributo e la domanda di utilizzo. Un modello Datanet medico rimane attivo finché i professionisti medici continuano a invocarlo. Un modello legale rimane attivo finché supera le alternative generali per il suo dominio. La pressione di selezione passa da "può questo modello permettersi di esistere" a "è questo modello davvero utile." Questa è una dinamica di mercato fondamentalmente diversa da quella che la maggior parte delle piattaforme AI crea.
Il pipeline di attribuzione RAG aggiunge un terzo livello sopra la provenienza di addestramento di ModelFactory e l'efficienza di distribuzione di OpenLoRA. Quando un modello distribuito recupera dati esterni per rispondere a una query, ogni pezzo di contenuto recuperato viene registrato criptograficamente on-chain al momento del recupero. La risposta del modello include citazioni verificabili che puntano a fonti di dati specifiche. I contribuenti il cui contenuto è stato recuperato ricevono micro-ricompense calcolate proporzionalmente a quanto significativamente i loro dati hanno influenzato l'output, instradate automaticamente per ogni evento di inferenza in base ai pesi di attribuzione assegnati dal sistema.
Combinare tutti e tre i livelli crea una categoria di asset AI che non esiste altrove: un modello che è simultaneamente uno strumento di inferenza funzionale, un registro verificabile della propria costruzione e un canale di entrate continuo per tutti coloro che hanno contribuito a costruirlo. Un modello in un marketplace costruito in questo modo è già più denso di informazioni di un intero prodotto chatbot. L'hub di OpenLedger ottimizza per la provenienza verificabile attraverso migliaia di tali modelli, ciascuno al servizio di un dominio specifico, ciascuno economicamente connesso alla rete di contribuenti dietro di esso.
La tensione irrisolta è se la giustizia di attribuzione regga mentre i modelli vengono fine-tuned su altri modelli fine-tuned. Quando un modello secondario eredita pesi da un modello fine-tuned primario, tracciare quali contributi originali di Datanet hanno influenzato il comportamento del modello secondario diventa davvero difficile. Il whitepaper di OpenLedger su Proof of Attribution affronta questo utilizzando approssimazioni della funzione di influenza per modelli più piccoli e attribuzione basata sul gradiente per quelli più grandi, ma l'accuratezza a diversi strati di rimozione è ancora una questione di ricerca aperta.
Quella tensione segna dove si trova il prossimo duro lavoro, non dove fallisce l'architettura. Un hub di modelli che registra cosa ha costruito, chi l'ha costruito e chi viene pagato quando viene utilizzato è una categoria di infrastruttura diversa da quella che non registra nulla. Il registro è il prodotto.
$OPEN #OpenLedger