Everyone was watching the AI narrative run this week — same names, same coins, same thread templates. I'd already closed my charts by mid-afternoon and started going down a different rabbit hole.
I started looking at OpenLedger properly. Not the price, not the airdrop mechanics. I kept pulling on one specific thread: the Proof of Attribution system, and what it actually means when OpenLedger talks about "scalable AI execution across Web3."
Here's the thing I couldn't shake.
Most people who cover $OPEN frame it as a transparency play. A record-keeping layer. You trained a model, some of your data got used, you get a micro-payment. Clean story. Makes sense for the current moment, especially with regulators breathing down AI companies' necks about data provenance. And that framing is technically accurate — but I think it misses what OpenLedger is actually betting on.
The real thesis isn't about recording human data contributions at all. It's about AI agents paying other AI agents.
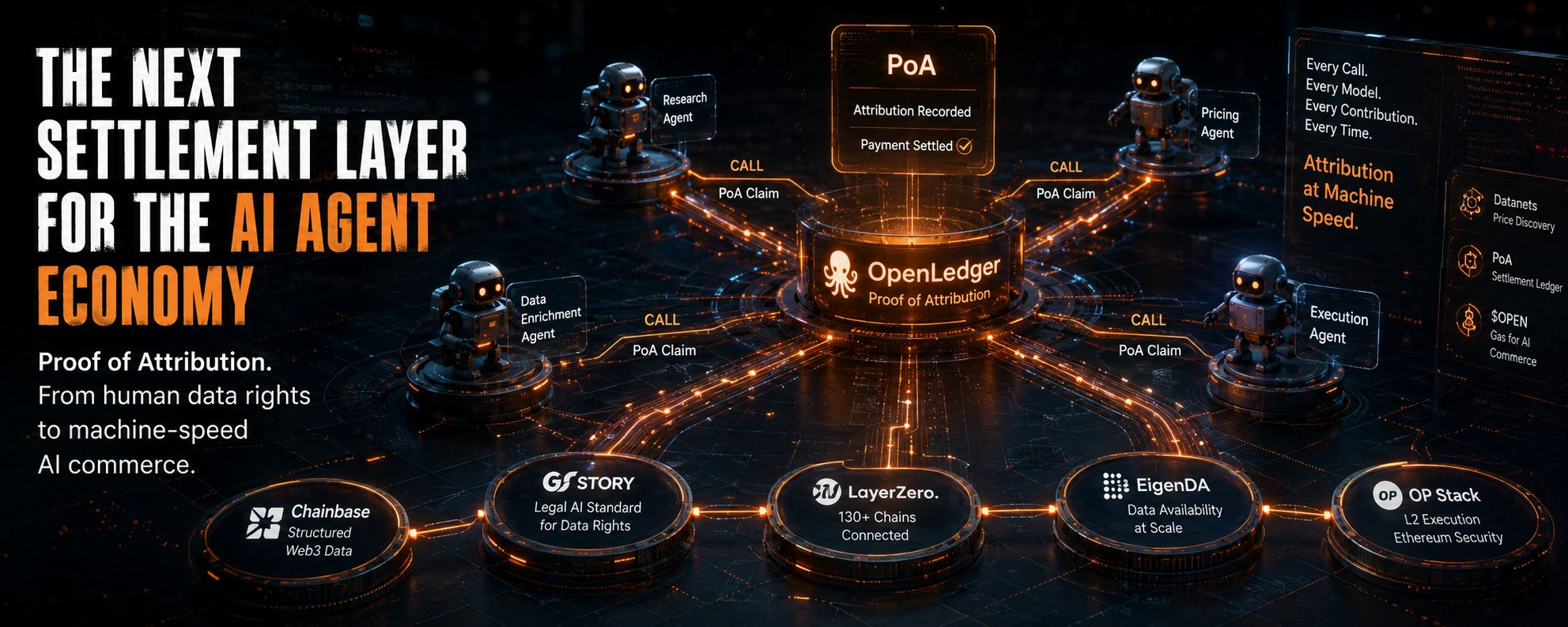
Think about where autonomous agent networks are heading. One agent calls a research sub-agent, which calls a pricing model, which calls a data enrichment layer, which writes back to chain. That whole call stack — potentially dozens of model inferences per second, per agent, across multiple chains — every one of those interactions is theoretically an attribution event. Who trained that pricing model? Which DataNet fed the research layer? Every hop is a Proof of Attribution claim waiting to happen.
That's not a transparency product anymore. That's settlement infrastructure for machine-speed AI commerce.
I thought the Chainbase partnership from December 2025 was just a typical "AI meets data" integration. But reading it again — "agents can read, verify, and act with confidence in Web3" — it clicked differently. OpenLedger isn't building for the developer who manually fine-tunes a LLaMA model and wants credit. It's building for the day when agent orchestration layers need a trust and payment rail that can clear at machine speed. The Datanets become the price discovery mechanism. PoA becomes the settlement ledger. $OPEN becomes the gas for an economy that runs without any human reviewing individual transactions.
That's a genuinely different thing than what the current market cap reflects.
But here's the part that bothers me.
Proof of Attribution, as it exists today, runs influence computations using gradient-based methods and token-span matching — traced back to individual DataNets. That works when you're auditing a fine-tuning run or verifying which dataset influenced a specific output. It does not obviously work at the inference frequency that an autonomous agent economy generates. We're talking potentially millions of attribution proofs per hour once multi-agent frameworks start nesting. Whether that's computationally feasible on an OP Stack L2 settling to Ethereum — with EigenDA handling data availability — I genuinely don't know. OpenLedger hasn't shown us a stress test at that scale. Nobody has.
And this is the part I keep coming back to. The September 2026 cliff is when team and investor tokens — roughly 33% of total supply combined — start their linear unlock. That's also the quarter when OpenLedger's own roadmap has the AI Marketplace and agent economy layers supposedly live and active. So the window where PoA needs to prove scalability at agent-call frequency is basically the same window where supply pressure starts entering the market. Tight timing.
The thing is, there aren't many protocols that have even tried to build this. Chainbase is feeding it structured Web3 data. Story Protocol gave it a legal AI standard for training data rights. The LayerZero integration connects 130+ chains to the attribution layer. OpenLedger has been quietly assembling the connective tissue for exactly this kind of agent settlement network — not loudly, not in the way that gets CT excited, but methodically.
I thought this was a data rights project. It's actually an attempt to become the base clearing layer for the AI agent economy. Whether it can handle the throughput that vision demands is a completely open question. Nobody's running that load yet. The agents that would generate that volume don't fully exist yet either. But if they arrive, and if they need an on-chain trust layer, OpenLedger is one of the only teams that thought about this problem early enough to build infrastructure rather than just a dashboard.
Anyway. The market was sideways all afternoon and I ended up overthinking a token that's currently sitting 90% below its all-time high. Probably won't be the last time.