
i keep thinking people talk about Datanets inside OpenLedger (@OpenLedger ) like they are just cleaner shelves for data.
better sorting, better quality, less garbage, more useful training input, fine.
and yeah obviously that matters. nobody serious wants decentralized AI built on a giant swamp of random junk and duplicated noise and mislabeled scraps pretending to be signal. if the whole point is to move away from the black-box appetite machine where everything gets scraped and swallowed and later turned into “intelligence,” then some layer has to decide what is even worth letting in.
but that’s the part that keeps bothering me.
because the second a OpenLedger system starts deciding what gets in, it is not just organizing reality anymore.
it is editing it.
and Datanets inside OpenLedger feel much closer to that than people admit.
not neutral repositories. not passive infrastructure. more like quiet gates sitting upstream of everything else, where certain kinds of data get admitted into the future and other kinds just don’t.
that changes the mood a lot.
because once data gets far enough inside OpenLedger, it stops being raw material in the casual sense. it starts gaining future economic possibility. maybe not immediately, maybe not cleanly, maybe not every time, but still. it enters a place where ModelFactory might later build on top of it, where OpenLoRA might later bend behavior through it, where Proof of Attribution might later trace some part of an output back through it, where OpenLedger might eventually move because some slice of it mattered enough to survive all the way into live use.
so if that is true, then dataset admission is not just housekeeping.
it is closer to upstream governance.
and maybe that sounds too dramatic at first, but i don’t think it is.
because what else do you call it when a system decides which version of reality becomes eligible to shape future models, future outputs, future payouts.
“curation is quiet power.”
that line keeps hanging there for me.
because people say curated dataset and it sounds so harmless. clean the data, verify the data, remove bad entries, make a stronger Datanet, everybody clap a little, move on. but the longer i sit with it the less harmless it feels. curation always has standards hiding inside it. standards mean judgment. judgment means exclusion. and exclusion, inside something like OpenLedger, is not just social or aesthetic or academic. it is economic. what gets excluded is not only ignored now. it may be shut out from later influence too.

that is a bigger decision than “is this high quality?”
high quality according to who.
useful according to what future task.
clean enough for which model path.
representative enough for whose reality.
and the strange part is that most of those questions don’t stay visible once the OpenLedger system moves on. by the time a model is answering something later, by the time Proof of Attribution is calculating what mattered, by the time contributors are getting paid or not paid, the earlier admission decision can already be buried under layers of technical legitimacy.
but it still happened.
someone or something already decided what got the chance to become future influence.
and i think that makes Datanets one of the most sensitive parts of OpenLedger even if people keep talking about them like they are just better baskets for cleaner inputs.
because the model does not start the story.
the answer does not start the story.
the payout definitely does not start the story.
the story starts earlier, when the system is still deciding what reality counts enough to enter the machine at all.
that’s the part i can’t stop circling.
especially because OpenLedger is not just training models in some abstract vacuum. it is building an economy around data provenance, usage, traceability, contribution, reward. once you do that, you cannot pretend admission is neutral anymore. the moment accepted data can later acquire measurable influence, accepted data is no longer just data.
it is pre-positioned potential.
and rejected data is not just messy input that failed quality control. sometimes maybe it is. sometimes it absolutely should be. but sometimes rejected data is also a version of the world that never gets to compete downstream, never reaches a Datanet state PoA can even see later, never becomes eligible for the reward logic everyone talks about afterward.
so what was really rejected there.
bad data.
or future leverage.
or one possible version of reality that the system decided was not worth carrying forward.
that is where Datanets stop feeling like infrastructure and start feeling like the first attribution-eligibility gate in the stack.
not usually through giant dramatic declarations. more through quiet thresholds. accepted, rejected. included, excluded. verified, not verified. structured enough, too noisy. high-quality, not useful. and each of those decisions sounds reasonable in isolation until you follow them far enough and realize they are deciding what gets to become economically legible later.
“admission is where future influence begins.”
that one feels load-bearing too.
because if OpenLedger is serious about attribution, then the first meaningful step is not just tracing what influenced the answer. it is deciding what gets the right to possibly influence an answer someday. those are not the same thing. and weirdly i think the first one might be more powerful than the second one, just quieter.
anybody can get excited later when Proof of Attribution wakes up and starts drawing lines through model path, adapter path, output path, payout path. nice. but all of that depends on a much earlier gate. if your data never entered the Datanet, or entered the wrong way, or failed some standard, or never made it into what eventually hardened into the golden dataset shape the network could actually use, then all the elegant downstream logic never had a chance to include you. PoA cannot trace what the gate never allowed to become usable in the first place. and if PoA never sees it, OpenLedger never has a real path to settle around it later either.
so the real bottleneck might happen before the intelligence part even starts looking intelligent.
that feels important and weirdly underdiscussed.
because most AI conversations still obsess over performance at the visible edge. how smart is the answer, how fast is the model, how precise is the specialization, how good is the agent, whatever. but OpenLedger keeps making me think the more serious question might happen much earlier and much more quietly.
what got admitted?
what got cleaned out?
what got standardized?
what got flattened?
what got preserved?
what got ruled too weak, too messy, too unverified, too marginal to enter the future?
and once you ask that, Datanets stop sounding boring very fast/
they start sounding like the place where future model behavior gets compressed before anyone notices how much was already decided/
because no dataset is just a pile once it enters a system like this. once it is validated, structured, attributed, made legible, and positioned for later use, it has already survived one judgment layer. and survival changes things. survival means maybe ModelFactory sees it later. maybe OpenLoRA loads behavior shaped by it later. maybe some agent route ends up acting on a world partly defined by what was let in earlier. maybe OpenLedger ($OPEN )later settles around traces that only exist because certain inputs crossed the threshold first.
so what are Datanets then.
not just data networks.
more like admission machines for future consequence.
that sounds colder, but closer.
and i think that coldness matters because OpenLedger is always being framed as fairness infrastructure. fair attribution, fair rewards, fair compensation, fairer AI economy. all fine. but fairness downstream can still depend on exclusion upstream. that doesn’t automatically make it fake or bad, but it does make it harder than the surface story sounds. you can’t say “everyone gets paid for what they contributed” without also asking who got the chance to contribute in a way the system would recognize.
that recognition layer is not soft. it is architectural.
which is why i keep feeling like Datanets are closer to governance than storage.
not governance in the loud token-vote sense necessarily. more like governance through Datanet standards, admission thresholds, verification rules, formatting pressure, usefulness tests, legitimacy filters. the quiet kind that decides what can later become normal inside the system, what can later become attributable influence, what can later enter payout visibility at all.
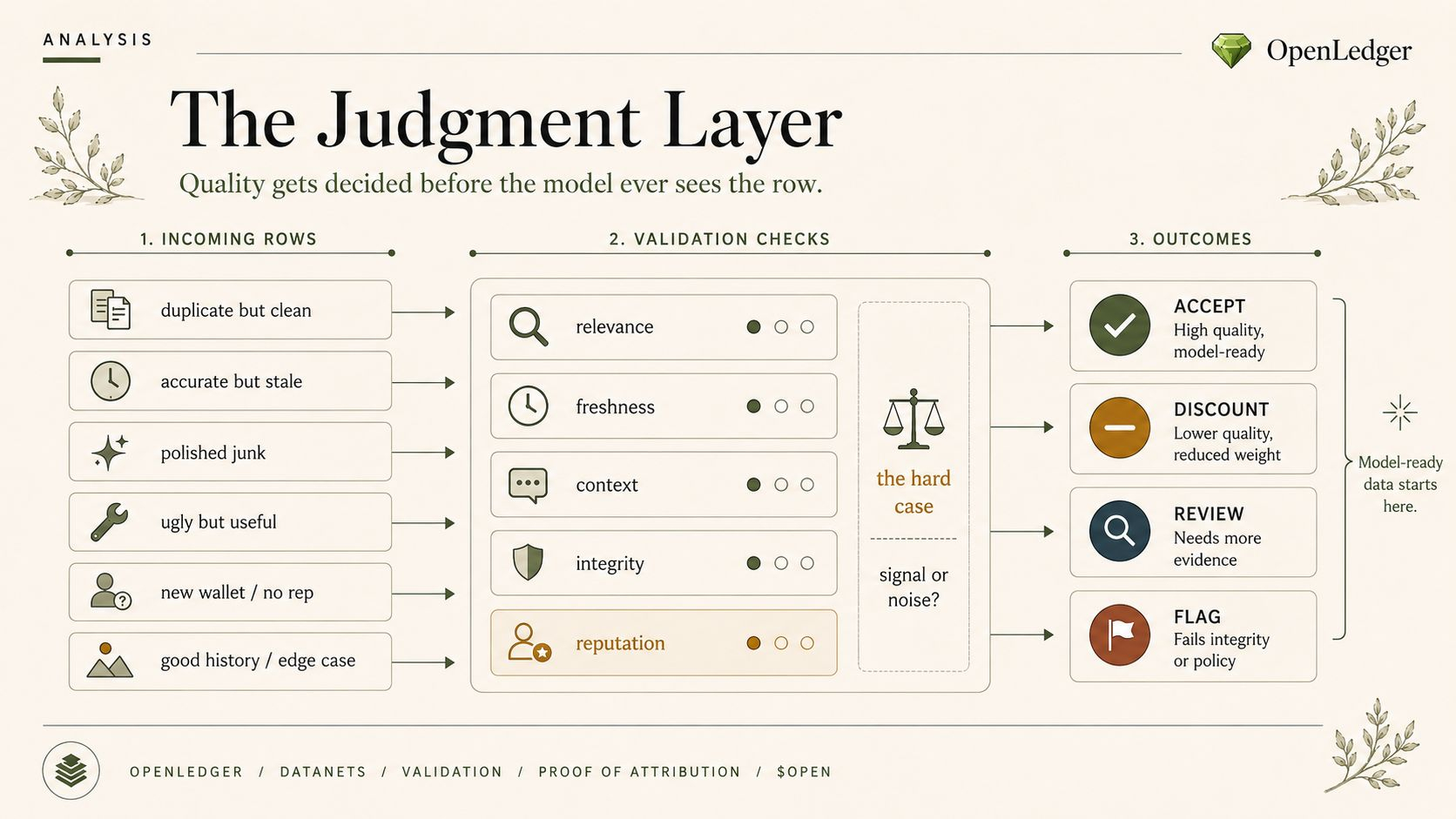
and the more i think about it the more that seems like one of the most serious power centers in OpenLedger.
not because it produces the answer directly.
but because it helps decide which realities are even eligible to become answer-shaped later.
that is big.
and honestly kind of uncomfortable.
because we all say we want better data, cleaner data, less noise, more trustworthy datasets. of course. but those wishes get less innocent once they sit inside a machine where accepted data can later become attributable influence and attributable influence can later become payout. suddenly “better data” is not just about epistemic quality. it is about who becomes economically visible later and who doesn’t.
and once that clicks, a Datanet stops feeling like a dataset upgrade.
it starts feeling like the first payout-eligibility threshold in the system.
quiet, procedural, technical-looking, but still deciding who gets standing in the future.
that may be why this part keeps sticking to me harder than i expected.
because by the time people argue about model behavior, or agent actions, or attribution fairness, or how OpenLedger should flow, a quieter decision may already have done most of the shaping.
the data that made it in is already inside.
the data that didn’t is already outside.
the future is already narrower than it looked from a distance.
and maybe that is unavoidable. maybe any serious system has to do this. maybe decentralized AI without stronger admission pressure just recreates the same old garbage problem with nicer branding. maybe Datanets have to be strict or the whole OpenLedger stack collapses into noisy theater.
but even if that is true, the pressure stays real.
because strict admission doesn’t just protect intelligence.
it defines what later becomes traceable, attributable, and payable at all.
“the model only sees the reality the gate allowed through.”
that feels harsh, but i don’t know how else to say it.
and inside OpenLedger that gate is not trivial. it sits before training, before specialization, before inference, before payout, before all the visible drama people like talking about. which means one of the most powerful parts of the system may also be one of the least glamorous.
just the quiet decision about what gets in.
and once something gets in, it doesn’t just become data.
it becomes future leverage.
and maybe that is the simplest way to say the whole thing.
the gate does not just protect the system.
it pre-decides what the system is allowed to know, what PoA is later allowed to trace, what OpenLedger is later allowed to settle around, and what kind of reality is even allowed to become economically real inside the stack.
that’s a lot of power for something people still describe like a better shelf.