I was reading the OpenLedger white paper near midnight with my laptop open and the room almost silent except for the fan beside my desk. One idea kept pulling me back. AI data usually works in the background. It shapes answers but rarely gets seen. I wondered whether OpenLedger is trying to change that hidden layer.
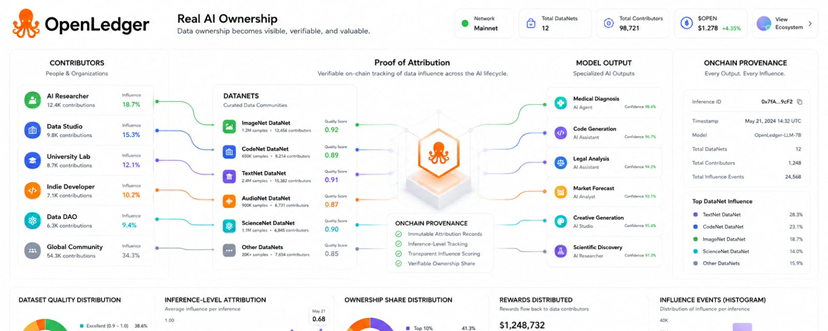
Can OpenLedger turn data influence into real AI ownership? That is the question I find more engaging than simply asking whether AI data can be rewarded. Ownership sounds simple but in AI it becomes complicated very quickly. A dataset may help train a model. A model may generate an answer. Many contributors may be involved before the final output appears. The white paper presents Proof of Attribution as the foundational mechanism that makes this chain visible and verifiable.
I see the project’s core idea as a shift from invisible contribution to measurable influence. OpenLedger describes an AI blockchain where data models and intelligent agents evolve onchain. The purpose is not only to store records. It is to show which data shaped model behavior and how that influence should be recognized. That matters because the value of AI does not come only from the final answer. It also comes from the data and model work that made the answer possible.
DataNets are important because they give this idea a structure. The white paper describes DataNets as structured onchain datasets created through community contribution. They are built around specific domains or tasks. That focus matters to me because specialized AI cannot depend only on general data. A focused DataNet can hold legal contracts code snippets medical transcripts sensor streams or fine grained question answer pairs. The value is not just that data exists. The value is that it can be traced organized and connected to future model use.
What makes OpenLedger different in this framing is the way it treats influence. A contributor should not be rewarded only because they uploaded something. A dataset should matter because it helped shape model behavior. The white paper explains that attribution can connect model outputs to the training data that influenced them. This makes ownership less like a static claim and more like a measured relationship between contribution and actual use.
The inference level reward flow is where this becomes practical. When a user submits an inference request the model generates an output influenced by data registered through DataNets. Attribution methods identify which datapoints contributed to that output. The output model metadata timestamp and attribution details can be committed onchain. Rewards can then be distributed according to relative influence. I think this is the clearest explanation of how data can move from passive asset to active earning layer.
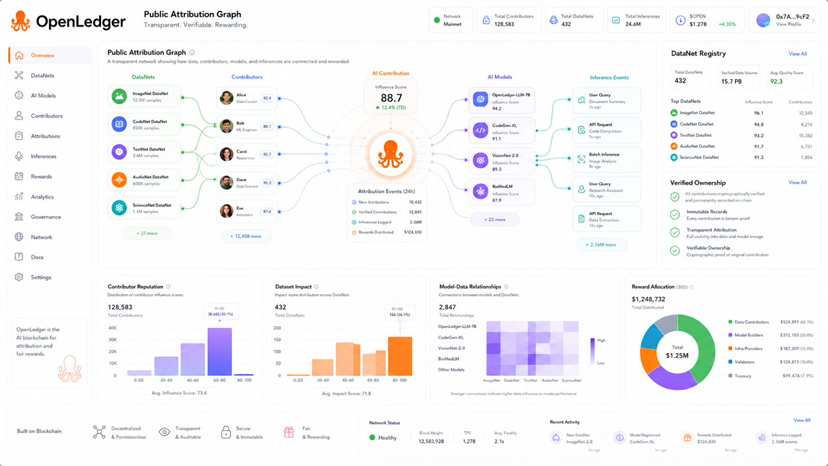
I also think the public attribution graph is one of the strongest ideas in the white paper. OpenLedger says influence weights model data relationships and inference events can be stored in a public graph. That can help show contributor reputation dataset saturation and underused areas. For me this turns OpenLedger into more than a payment system. It becomes a visibility layer for AI work. Builders can see which DataNets are useful. Contributors can see whether their data is being used. Communities can judge value through visible impact.
Still I do not see this as easy. Attribution has to be accurate enough to trust and scalable enough to use across real models. The white paper discusses different attribution methods for smaller models and larger language models which shows that there is no single simple solution. That makes me more cautious but also more interested. OpenLedger is not only making a reward claim. It is trying to solve the harder question of how influence should be measured.
There is also a governance layer inside this idea. The white paper says DataNets with high influence across production models may receive higher voting power. That means influence can affect not only rewards but also future decisions around dataset curation adapter prioritization and fee distribution. I like the logic because useful contribution should matter more than empty activity. At the same time it raises the stakes. If influence scores are wrong then governance weight can also become unfair.
My practical view is that OpenLedger should be judged by the quality of its attribution loop. Are DataNets actually useful for specialized models? Are rewards tied to real inference impact? Can contributors verify their role without relying on vague promises? Can builders inspect the data history behind model behavior? These are the questions that matter more than surface activity.
The strongest part of the white paper is its attempt to make AI ownership dynamic. Data ownership is not treated as a one time label. It becomes something proven through contribution use and influence. That is a more serious model because AI value changes over time. A dataset may become more valuable as more models use it. A contributor may build reputation through repeated measurable impact. A model may become more trusted because its data trail is visible.
My takeaway is grounded. OpenLedger’s real idea is not simply that data should be paid. Its deeper idea is that data influence should be visible enough to support ownership rewards and trust. If Proof of Attribution can keep that link accurate then DataNets can become more than repositories. They can become living economic assets inside AI development.
This is the part I will keep watching closely.


