Cari follower 💓
Così sono finito a scavare più a fondo nella documentazione tecnica @OpenLedger . Non per qualche ragione particolare. Avevo solo la scheda aperta.
E da qualche parte intorno alla terza lettura di come dovrebbe funzionare il loro strato di Proof of Attribution, qualcosa mi ha disturbato e non riuscivo a togliermelo dalla testa — e non era quello che mi aspettavo di trovare.
Tutti parlano di AI verificabile come se fosse un problema hardware. Tipo, prendi abbastanza nodi di calcolo decentralizzati, aggiungi un po' di validazione crittografica, e all'improvviso gli output dell'AI diventano affidabili. Questa è la proposta. Questo è ciò con cui quasi ogni progetto di "AI decentralizzata" inizia.
Il framing di OpenLedger è un po' diverso, però, e quasi me ne sono perso la prima volta.
La loro direzione tecnica reale non riguarda davvero la verifica che il calcolo sia avvenuto. Riguarda la verifica di quali input hanno plasmato un output — tracciando il contributo attraverso il pipeline di addestramento e inferenza fino alle specifiche fonti di dati, modelli e annotatori umani che hanno toccato un risultato. Il modello di Prova di Attribuzione non è un meccanismo di consenso. È più vicino a un registro di provenienza.
E lì mi si è chiarito: questi sono problemi completamente diversi.
Uno è un problema di verifica del calcolo. L'altro è un problema di genealogia dei dati. La maggior parte dell'industria sta costruendo per il primo. OpenLedger è, almeno architettonicamente, orientato verso il secondo.
Ecco cosa significa in realtà se funziona nel modo in cui lo descrivono.
In questo momento, quando un modello di IA produce qualcosa — un pezzo di analisi, una decisione, una classificazione — non hai modo di tracciare quali dati di addestramento hanno pesato quell'output. Puoi controllare i pesi se hai accesso. Non puoi controllare la catena di contributo. Non è una zona grigia regolamentare, è un'opacità fondamentale incorporata nel modo in cui i modelli sono assemblati oggi.
Se potessi etichettare i contributi all'ingresso, registrare quali set di dati e annotatori hanno influenzato i comportamenti dei modelli, e poi rendere visibile quella catena su richiesta — avresti qualcosa di realmente utile per le imprese, i revisori e chiunque cerchi di assegnare responsabilità per le uscite dell'IA. Questo è un vero problema di mercato, non solo una questione narrativa.
Ma ecco la parte che mi siede scomoda.
Il divario tra 'orientato architettonicamente verso' e 'realmente funzionante su larga scala' è enorme in questo spazio. Il tracciamento della provenienza a livello di dataset è davvero difficile — non teoricamente, ma praticamente. Nel momento in cui introduci qualsiasi fine-tuning, distillazione o fusione di modelli, le catene di attribuzione diventano rapidamente torbide. Chiunque abbia lavorato vicino ai pipeline di ML sa quanto rapidamente la genealogia dei dati diventi folklore piuttosto che un record.
Non sto dicendo che OpenLedger non possa risolvere questo. Sto dicendo che non ho visto prove che qualcuno abbia risolto questo in modo pulito su scala di produzione, on-chain o off. La ricerca esiste. Le implementazioni sono per lo più demo.
E il layer di ricompensa per i contributori che si trova sopra questo — dove i fornitori di dati e gli annotatori sono teoricamente compensati in base all'attribuzione verificata — tutto quel meccanismo è portante. Se il tracciamento dell'attribuzione ha lacune, la struttura degli incentivi eredita quelle lacune. Non ottieni solo una provenienza inaccurata. Ottieni un sistema di ricompensa sistematicamente biasato verso chiunque possa manipolare i registri di attribuzione.
Questo è un tipo di problema diverso da 'non ci siamo ancora scalati'.
Inizialmente pensavo — che fosse fondamentalmente la stessa cosa di ciò che alcuni altri progetti di IA decentralizzati stanno facendo con le prove a conoscenza zero per l'inferenza del modello. Ma in realtà, no. Le prove di inferenza ZK verificano che un calcolo specifico sia stato eseguito correttamente dato un modello fisso. Il tracciamento dell'attribuzione pone una domanda diversa: dato questo output, cosa ha contribuito al modello che lo ha prodotto? Provenienza inversa rispetto a verifica in avanti. Facile da confondere, genuinamente diverso.
Quella distinzione conta molto per come useresti effettivamente questo nella pratica.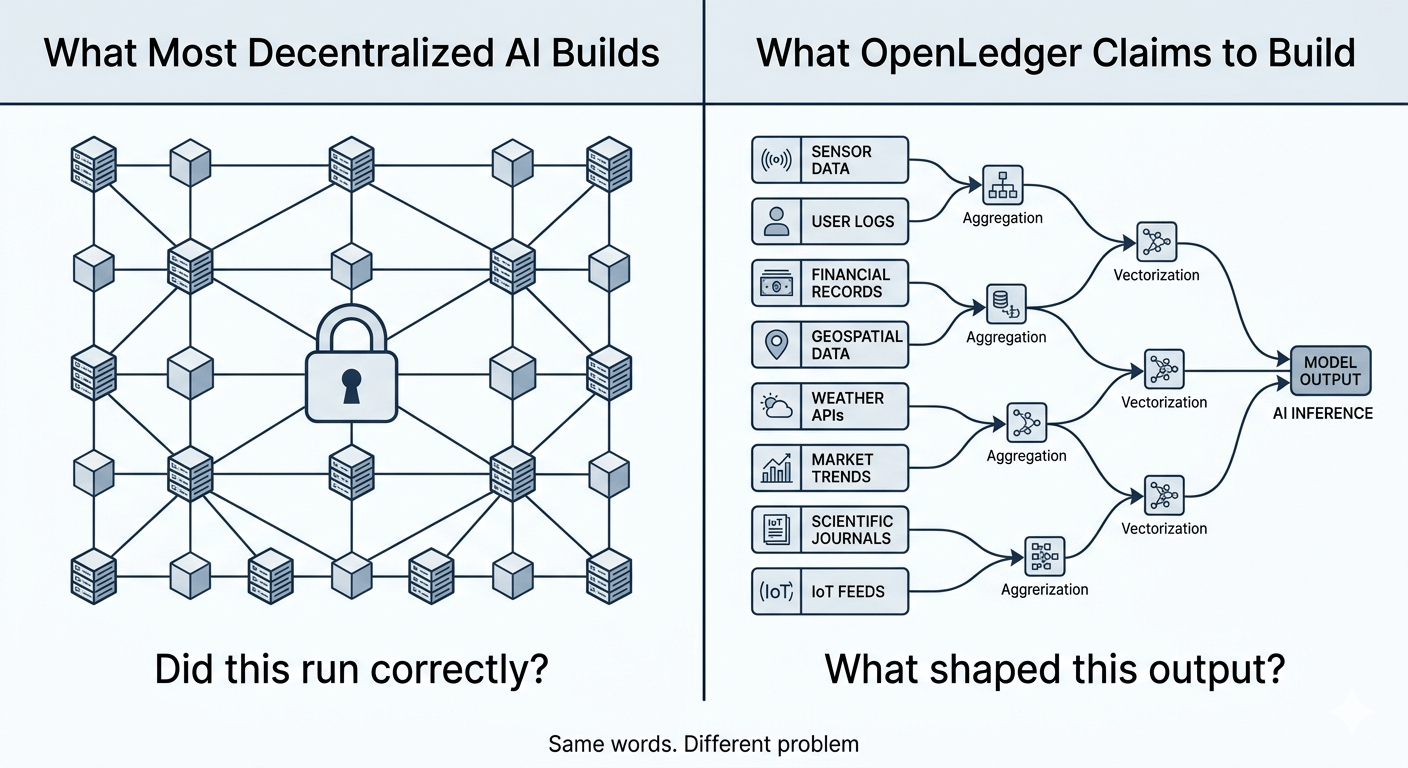
Comunque. Sto ancora osservando come si sviluppa il programma di sblocco nei prossimi mesi — questo probabilmente ti dirà di più sul sentiment di mercato riguardo a questo rispetto a qualsiasi documentazione tecnica.
L'attribuzione è un vero problema da risolvere. Se questa architettura lo risolve, o semplicemente descrive di risolverlo in modo convincente, onestamente non lo so ancora.
Probabilmente continuerò a tenere d'occhio la situazione.