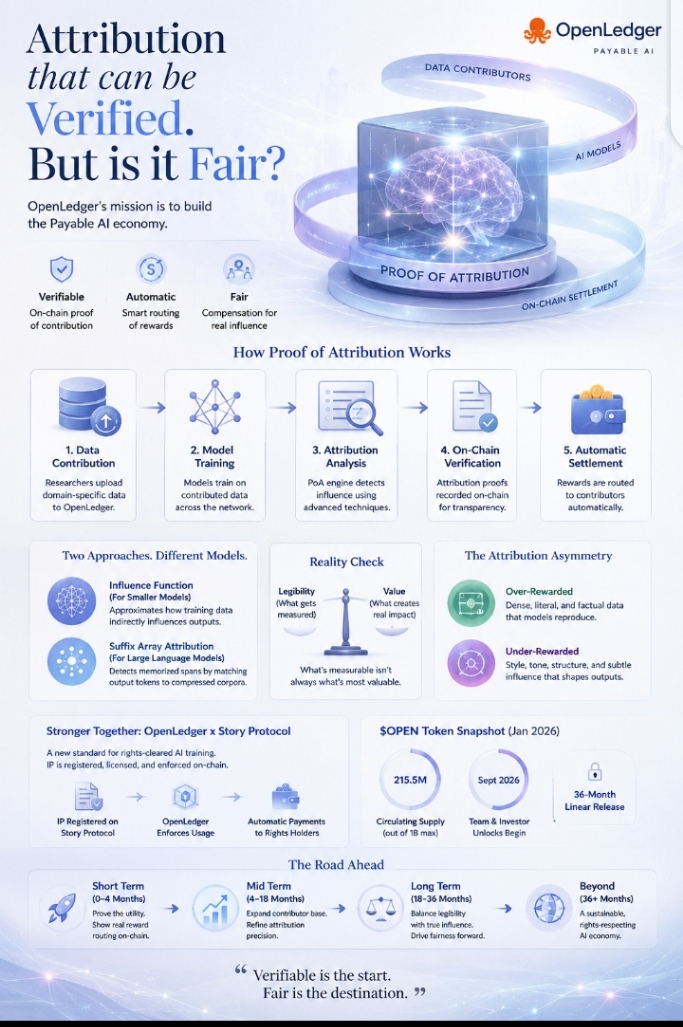
There's a version of AI that I used to assume was inevitable. The one where a researcher uploads domain-specific data, a model trains on it, and a transparent ledger quietly routes a royalty payment back. Automatic. Auditable. Fair. I'd heard the pitch many times. Then I actually tried to trace what happens inside #OpenLedger Proof of Attribution system — not from the whitepaper, but from following a dataset contribution through the chain — and the elegance I'd imagined started showing its seams.
$OPEN has been live on mainnet since November 18, 2025. I went in expecting the "Payable AI" framing to feel aspirational, a vision dressed up as an engine. What I found was different, and in some ways more unsettling. The engine exists. The attribution trails are real. But the question of what gets measured turns out to be a design choice disguised as a technical one.
The Proof of Attribution mechanism does two things, depending on the model size. For smaller models, it uses influence-function approximations. For large language models, it runs suffix-array-based token attribution — checking output tokens against compressed training corpora to detect memorized spans. That's the technical layer. What it actually rewards is measurable contribution to output. And measurability, it turns out, is not the same as value.
the number that kept pulling me back
On January 29, 2026, OpenLedger and Story Protocol jointly announced a new standard for rights-cleared AI training. The press release framed it cleanly: IP registered on Story Protocol could now be licensed for AI use, with OpenLedger enforcing those licenses inside AI systems and routing automatic payments to rights holders. A shared on-chain registry, auditable usage logs, settlements that finalize without intermediaries. The infrastructure looked airtight.
What stopped me was a quieter detail buried in the mechanism design. Under the PoA framework, contributors whose data most directly influences model outputs earn the most. The suffix-array approach specifically rewards memorized spans — content the model demonstrably retained and reproduced. Which means: the work most legible to the attribution engine is the work most directly copied. The subtle, structural influence — the writer whose syntax shaped a model's sentence rhythm without ever being memorized verbatim — doesn't register the same way.
I sat with that for a while. I thought I was looking at a fairness engine. I was actually looking at a legibility engine. The two aren't the same.
There's a reason this bothers me more than a typical technical limitation. A few months ago I watched a musician friend's entire back catalog get scraped into a training corpus. She never saw a fraction of the value the model captured by absorbing her style. The proposal on OpenLedger is the best answer I've seen to that problem. But the PoA system, as I understand it, would compensate her most for the parts of her work that were literally reproduced — not the parts that shaped the model's feel. That's better than nothing. It might still be structurally unfair in a different direction.
hmm — the gap between provenance and influence
This isn't a fatal flaw. It might not even be solvable with current cryptography. Influence-function approximations can get at indirect contributions, but they're computationally expensive and, at scale, impractical for real-time reward routing. The PoA whitepaper is honest about the tradeoff — two approaches for different model classes, each with different precision levels. The system is choosing tractability over theoretical completeness, which is the right engineering call.
But it does mean that the $OPEN reward distribution, at least in its current form, is going to systematically over-reward contributors whose data is dense and literal — structured datasets, factual corpora, legal documents — and under-reward the more diffuse, stylistic contribution that shapes how a model actually communicates. That's the contrast I didn't expect. The project built to address AI's attribution crisis has its own attribution asymmetry baked into the foundation.
The circulating supply sits at 215.5 million $OPEN out of a 1 billion maximum. Team and investor unlocks begin in September 2026, introducing a 36-month linear release. So there's a window — roughly three to four months — where the network's utility case still needs to prove itself before supply dynamics shift the conversation. What the on-chain data needs to show in that window isn't just transaction volume. It's whether the attribution layer is actually routing meaningful rewards to contributors, and whether those contributors keep coming back.
still not sure what to make of this
The Story Protocol integration is the most interesting development in that context. If IP is registered at the canonical registry level — ownership, licensing terms, derivative permissions all embedded machine-readably — then OpenLedger's enforcement layer has more to work with. Attribution doesn't have to be entirely reconstructed from inference behavior; it can also be asserted at the point of registration. That's a different architecture than pure PoA measurement, and it potentially closes some of the legibility gap.
I find myself thinking about @OpenLedger the same way I think about early oracle networks. The concept was right. The first implementations had edge cases that took years to surface. The teams that survived were the ones who treated the edge cases as design problems, not exceptions. OpenLedger is early enough that the asymmetry I've described might get resolved — or might calcify into something structural.
The infrastructure is real. The attribution trails are real. The January 2026 standard with Story Protocol is a serious step. What I'm still turning over is whether "verifiable" and "fair" are going to converge as the network matures, or whether legibility will keep doing most of the work and calling itself fairness.
Which might be the most honest question the project could be asked right now — by a contributor deciding whether to upload their best work, or their most measurable work.