
Look, after spending enough time in crypto, you stop getting excited by clean pitch decks.
You start looking for the mess.
The broken parts.
The stuff nobody wants to talk about because it sits under the hood and makes everything uncomfortable.
And with AI, the mess is pretty obvious.
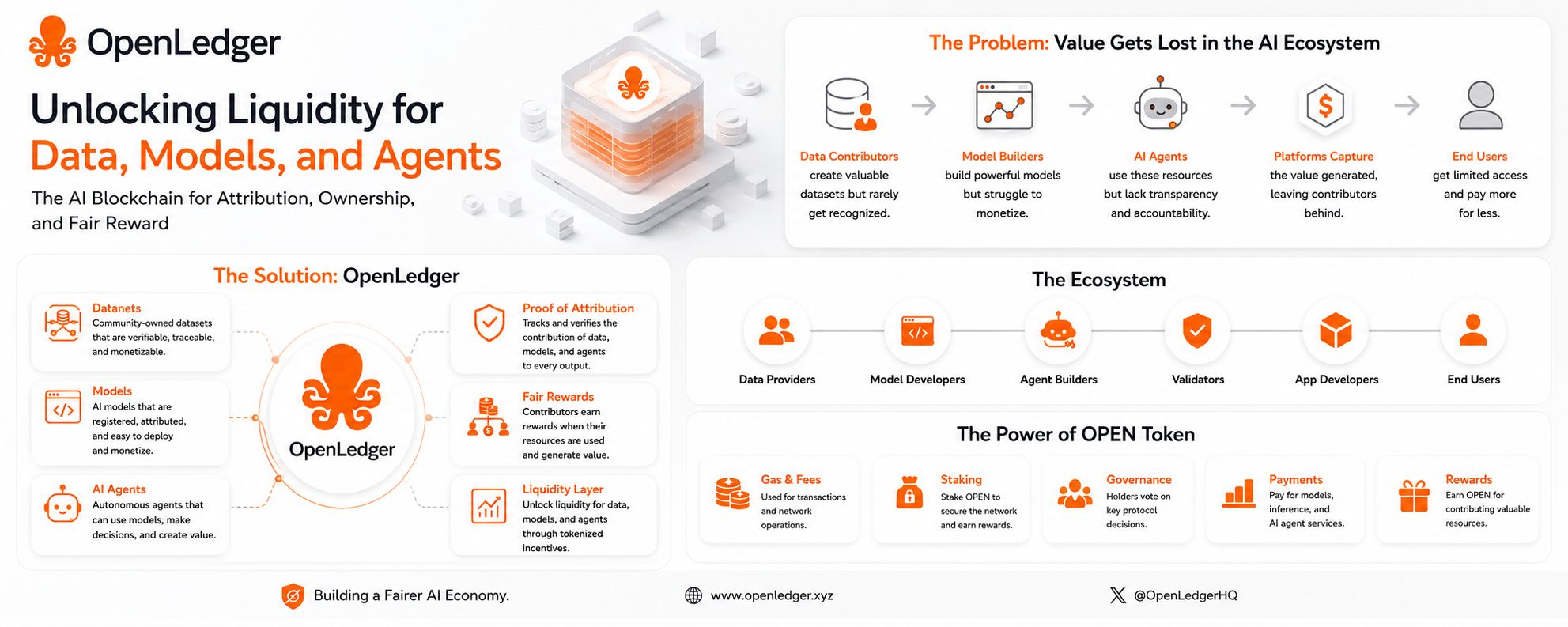
Everybody is building on data. Everybody is training models. Everybody is talking about agents. But when you ask where the value actually came from, the answer gets blurry fast.
Some person wrote the data. Some community cleaned it. Some developer fine-tuned the model. Some small team made the agent useful. Then a bigger platform comes along, wraps it in a nice interface, and suddenly all the credit moves upward.
We have seen this before.
Crypto did the same thing with users.
Projects begged people to test networks, bridge assets, mint NFTs, join quests, provide liquidity, sign transactions, report bugs, and act like unpaid infrastructure. Then came the airdrop.
And somehow the real users got dust while the farmers walked away with bags.
Honestly, that experience made a lot of people cynical. Not because they hate crypto. Because they actually used the products. They paid the gas. They got stuck on broken bridges. They waited for transactions that failed anyway. They watched fake wallets get rewarded for pretending to be active.
That is the trauma.
Bad attribution.
Wrong people rewarded.
Real contribution ignored.
So when OpenLedger talks about Proof of Attribution, I do not hear it as some shiny new phrase. I hear it as an attempt to fix one of the oldest problems in this space: we are terrible at knowing who actually added value.
OpenLedger is trying to build infrastructure for AI where data, models, and agents do not just disappear into someone else’s system. They get tracked. They get used. And if they help create value, there is at least a path for rewards to go back to the source.
That sounds simple.
It is not.
Attribution is hard. Especially in AI. A model does not work like a receipt. It does not say, “This answer came 12% from this dataset, 8% from this contributor, and 3% from that fine-tune.” Influence is messy. Data gets mixed. Models learn patterns, not clean little ownership labels.
So yes, OpenLedger is trying to solve a hard problem.
Maybe it takes time.
Maybe the first versions are imperfect.
Maybe some parts feel clunky before they feel useful.
That is normal. Real infrastructure usually looks boring and unfinished before people realize they depend on it.
The thing is, AI needs this kind of plumbing.
Not another flashy app.
Not another token with a perfect landing page.
Plumbing.
A way to know what data was used. A way to connect models to the people and datasets that shaped them. A way for agents to operate without everything turning into a black box. A way for contributors to not get erased the moment their work becomes profitable.
Because right now, AI has the same problem crypto had during the worst airdrop seasons.
A lot of activity.
A lot of noise.
A lot of people pretending to contribute.
And very little clarity about who actually matters.
OpenLedger’s idea of Datanets makes sense in that context. A Datanet is basically a dataset built around a community or a specific purpose. Instead of data being scraped, swallowed, and forgotten, it becomes something that can be registered and used. If that data helps train or improve a model, it should not vanish from the story.
That part feels important.
Because data is not just “data.”
It is people’s work.
It is someone’s research. Someone’s labeling. Someone’s local knowledge. Someone’s hours spent organizing ugly information into something useful.
Anyone who has ever worked with raw data knows this. The valuable part is not always the data itself. It is the cleaning. The checking. The judgment. The boring human effort that makes the data usable.
That is usually the part nobody wants to pay for.
OpenLedger is saying: maybe we should.
Not as charity.
As infrastructure.
If a dataset helps a model produce useful outputs, then the dataset has value. If a contributor made that dataset better, that contributor matters. If an AI agent uses a model built on that work, the chain should not disappear.
This is where OPEN, the token, comes in. It is supposed to move through the network as people use the system: fees, model activity, inference, staking, governance, rewards.
But honestly, the token is not the most interesting part by itself.
Tokens are easy to launch.
Useful networks are not.
The real question is whether OpenLedger can create enough actual usage around data, models, and agents that OPEN has a reason to exist inside the system. If people are contributing useful data, developers are building real models, agents are doing real work, and users are paying for outputs, then the token has context.
Without that, it is just another chart.
And crypto has enough charts.
What makes OpenLedger worth watching is that the problem it points at is real. AI is growing fast, but the ownership layer is still messy. People are worried their work is being used without credit. Builders want better ways to monetize specialized models. Communities want control over the knowledge they create. Businesses want AI they can actually audit.
None of that gets solved by vibes.
It needs records.
It needs payment rails.
It needs attribution that is good enough to be trusted.
It needs boring infrastructure that actually works.
And yes, blockchain can make sense here. Not because every AI output needs to be on-chain. That would be ridiculous. But because ownership, contribution, rewards, and verification are exactly the kinds of problems crypto has been trying to solve for years.
The mistake is thinking the chain is the product.
It is not.
The product is trust.
The product is knowing that if your data helped create value, you are not just hoping someone remembers you later.
The product is not getting rugged by invisibility.
That is the part I keep coming back to.
In crypto, people got tired of doing real work and being treated like background noise. In AI, the same thing could happen at a much bigger scale. Writers, researchers, developers, translators, communities, open-source contributors, data cleaners, model trainers — all of them could become invisible fuel for systems that make other people rich.
OpenLedger is trying to stop that from feeling inevitable.
Not perfectly.
Not overnight.
But it is aiming at the right wound.
And that matters.
Because the future of AI will not only be about who has the biggest model. It will also be about who controls the layer beneath the model. Who owns the data. Who can prove contribution. Who gets paid when agents start using these systems at scale.
That layer is not glamorous.
It is pipes.
Logs.
Receipts.
Permissions.
Reward flows.
Stuff most users will never think about until it breaks.
But when that layer is missing, everything above it becomes unfair.
So no, I do not look at OpenLedger as some magical fix for AI. It has a lot to prove. Attribution has to work. Data quality has to be protected. Fake contribution has to be filtered out. The experience has to be simple enough for normal people, not just crypto-native users. And most importantly, people have to actually use what gets built there.
That is the hard part.
Still, the idea feels necessary.
Because if AI is going to keep eating the internet, then we need better ways to remember who cooked the meal.
OpenLedger is trying to build that memory.
Not the shiny part.
The necessary part.