Sáng hôm qua tôi điền một form khảo sát của bệnh viện sau khi khám. Bốn trang câu hỏi về triệu chứng, mô tả cảm giác đau, các loại thuốc đã dùng. Mất khoảng mười lăm phút. Tôi submit xong và quên luôn. Nhưng trong đầu tôi xuất hiện một câu hỏi lạ: data đó đi đâu?
Câu trả lời mà tôi dần nhận ra, và có lẽ nhiều người chưa nghĩ đến, là data đó nhiều khả năng đã hoặc sẽ được dùng để train AI medical model nào đó. Không phải một mô hình nhỏ. Mà là loại model mà các công ty dược phẩm hay bệnh viện lớn sẽ trả hàng chục triệu đô để license. Tôi đã đóng góp vào giá trị đó. Không một đồng thù lao.
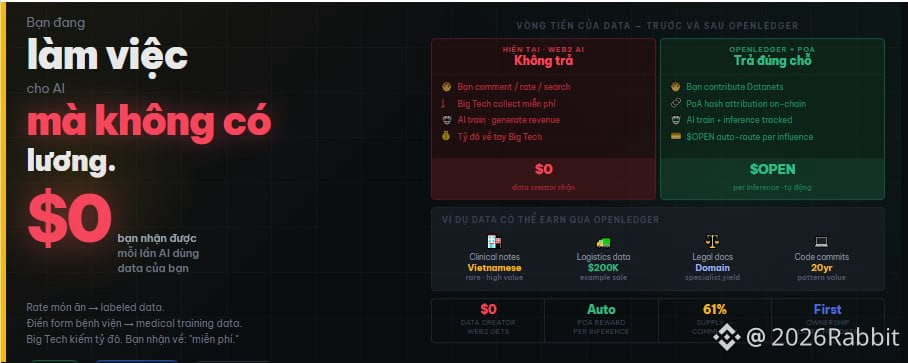
Đây không phải là câu chuyện cá nhân của tôi. Mỗi lần bạn rate một món ăn trên Grab, mỗi lần bạn comment trên Facebook, mỗi lần bạn correct một lỗi auto-complete trên bàn phím điện thoại, bạn đang tạo ra labeled data mà AI companies gọi là "gold standard training data." Không ai hỏi bạn. Không ai trả bạn. Đó là cách ngành AI đã vận hành từ đầu.
Khi tôi bắt đầu đọc tài liệu của @OpenLedger, cái làm tôi dừng lại không phải là phần technical về OP Stack hay EigenDA. Mà là một câu rất đơn giản trong gitbook của họ: "This turns every AI interaction into a monetizable event for contributors." Câu đó không nói về developer hay data scientist. Nó nói về người thường như tôi điền form bệnh viện lúc sáng sớm.
Tôi hiểu rằng nhiều người sẽ phản bác: "Ủa, nhưng bệnh viện ký một đống NDA với bệnh nhân rồi, data không đi đâu hết." Có thể đúng cho một số trường hợp được quy định chặt chẽ. Nhưng hãy nhìn rộng hơn. Mỗi ngày bạn tạo ra hàng trăm data points: bạn search gì, bạn dừng lại đọc cái gì, bạn skip qua video nào sau ba giây. Google và Meta đang thu thập tất cả những thứ đó và đưa vào model AI của họ. Khi AI đó generate ads, viết content, hay suggest sản phẩm, họ kiếm tiền từ data của bạn. Bạn kiếm được gì? Một trải nghiệm "miễn phí" trên ứng dụng.
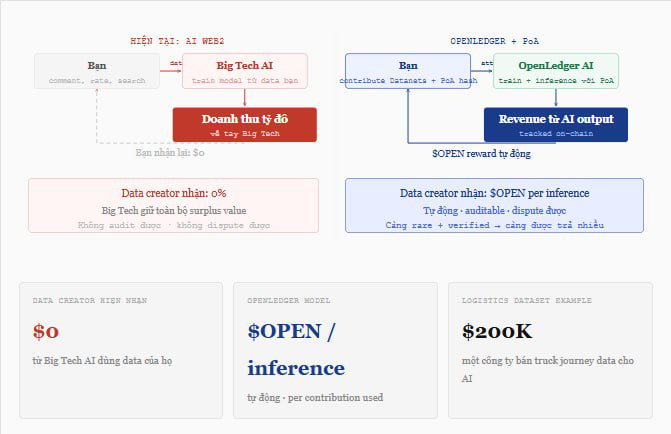
OpenLedger gọi cơ chế của họ là "Proof of Attribution," và cách nó hoạt động về mặt kỹ thuật là thứ tôi thấy thực sự khác biệt so với phần lớn các project AI blockchain khác. Thay vì chỉ ghi nhận ai upload data, hệ thống cố gắng trace influence của mỗi dataset lên model output cụ thể thông qua hai phương pháp: influence-function approximation cho model nhỏ, và suffix-array token attribution cho LLM lớn, tức là kiểm tra xem output token có match với đoạn nào trong training corpus không. Nghe phức tạp, nhưng đơn giản hóa lại thì nó như thế này: mỗi lần AI trả lời một câu hỏi, hệ thống tìm xem data của ai đã giúp tạo ra câu trả lời đó, rồi trả $Open về ví của người đó.
Tôi nghe một bạn bác sĩ nói rằng case notes của ông ấy không có giá trị gì vì "ai cần đọc một loạt ghi chú lộn xộn bằng tiếng Việt." Nhưng khi một AI model cần learn cách diagnose dựa trên Vietnamese patient presentation patterns, cái loạt ghi chú lộn xộn đó lại cực kỳ hiếm và cực kỳ valuable. Đây chính xác là loại data mà Datanets của OpenLedger muốn attract: specialized, domain-specific, không tìm được trên internet, và verified bởi identity của contributor.
Vấn đề tôi đang theo dõi cẩn thận là liệu attribution mechanism có đủ robust để phân biệt giữa "data giá trị thực sự đã ảnh hưởng đến output" và "data được upload để farm token mà không really contribute gì." Đây là điểm yếu lớn nhất. Nếu hệ thống không solve được bài toán này ở quy mô lớn sau khi nhiều developer bắt đầu build trên mainnet, thì 61% community allocation sẽ chảy về sai chỗ và toàn bộ thesis của $OPEN sụp đổ.
Nhưng nếu họ solve được, thì điều đó có nghĩa là lần đầu tiên trong lịch sử internet, người thường điền form bệnh viện lúc sáng sớm có thể nhận được một phần nhỏ từ revenue mà AI company kiếm được từ data đó. Không nhiều. Nhưng là thứ gì đó, thay vì không có gì như hiện tại.
Tôi không hold $OPEN vì tôi tin giá sẽ tăng ngay tuần tới. Tôi theo dõi dự án này vì nếu thesis của họ đúng, đây là lần đầu tiên internet có một ownership layer thực sự cho data. Và từ góc độ đó, mức giá hiện tại sau khi đã giảm hơn 90% từ ATH đang price in rủi ro execution, không price in khả năng thesis đúng.
Nếu OpenLedger hoàn thiện được attribution mechanism, bạn sẽ contribute loại data nào vào Datanets và bạn nghĩ data đó đáng bao nhiêu tiền?