 Continuo a tornare su una semplice contraddizione nel mondo delle crypto e dell'AI: tutti dicono che i dati sono preziosi, ma la maggior parte dei sistemi continua a trattare le persone che creano, puliscono, etichettano o raffinano quei dati come se fossero invisibili. La stessa cosa succede con i modelli e gli agenti. Celebriamo l'interfaccia, la demo o l'output, ma raramente otteniamo un chiaro resoconto di chi ha contribuito a cosa, chi può provarlo e chi dovrebbe essere pagato quando l'output diventa utile. OpenLedger si posiziona direttamente in quel gap, descrivendosi come una blockchain AI costruita per sbloccare la liquidità per dati, modelli e agenti. Quella cornice è importante perché riguarda meno l'aggiunta di “AI” a una chain e più il chiedersi se l'AI possa essere organizzata attorno all'attribuzione invece che all'opacità.
Continuo a tornare su una semplice contraddizione nel mondo delle crypto e dell'AI: tutti dicono che i dati sono preziosi, ma la maggior parte dei sistemi continua a trattare le persone che creano, puliscono, etichettano o raffinano quei dati come se fossero invisibili. La stessa cosa succede con i modelli e gli agenti. Celebriamo l'interfaccia, la demo o l'output, ma raramente otteniamo un chiaro resoconto di chi ha contribuito a cosa, chi può provarlo e chi dovrebbe essere pagato quando l'output diventa utile. OpenLedger si posiziona direttamente in quel gap, descrivendosi come una blockchain AI costruita per sbloccare la liquidità per dati, modelli e agenti. Quella cornice è importante perché riguarda meno l'aggiunta di “AI” a una chain e più il chiedersi se l'AI possa essere organizzata attorno all'attribuzione invece che all'opacità.
Prima che un progetto del genere appaia, il problema ricorrente è facile da vedere. I sistemi AI sono addestrati su set di dati assemblati da molte mani, eppure la catena di contributo di solito scompare nel momento in cui inizia l'addestramento. Il modello risultante può essere potente, ma la provenienza dei suoi ingredienti è spesso poco chiara, e le persone che hanno fornito i dati sono raramente visibili nell'immagine economica finale. Il materiale stesso di OpenLedger è esplicito su questo reclamo: sostiene che l'AI di oggi manca di trasparenza, che i contributori non vengono accreditati e che gli attori centralizzati finiscono per controllare i modelli più preziosi. Penso che quella diagnosi sia ampiamente corretta, anche se la cura è ancora incerta. La stessa lamentela è emersa ripetutamente nei tentativi più vecchi di mercati di dati, sistemi di licenze e progetti di AI decentralizzati, e di solito hanno inciampato per lo stesso motivo: possono descrivere il valore, ma faticano a misurarlo in modo sufficientemente pulito da distribuirlo equamente.
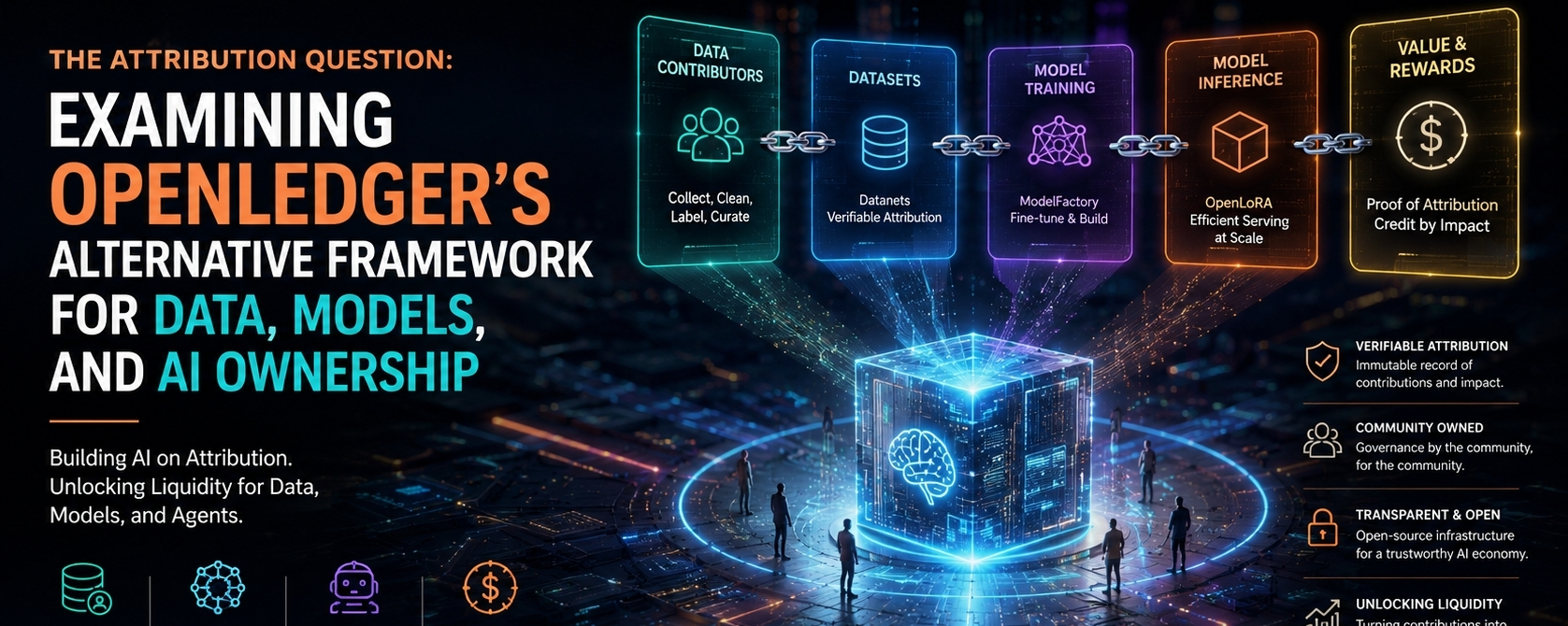
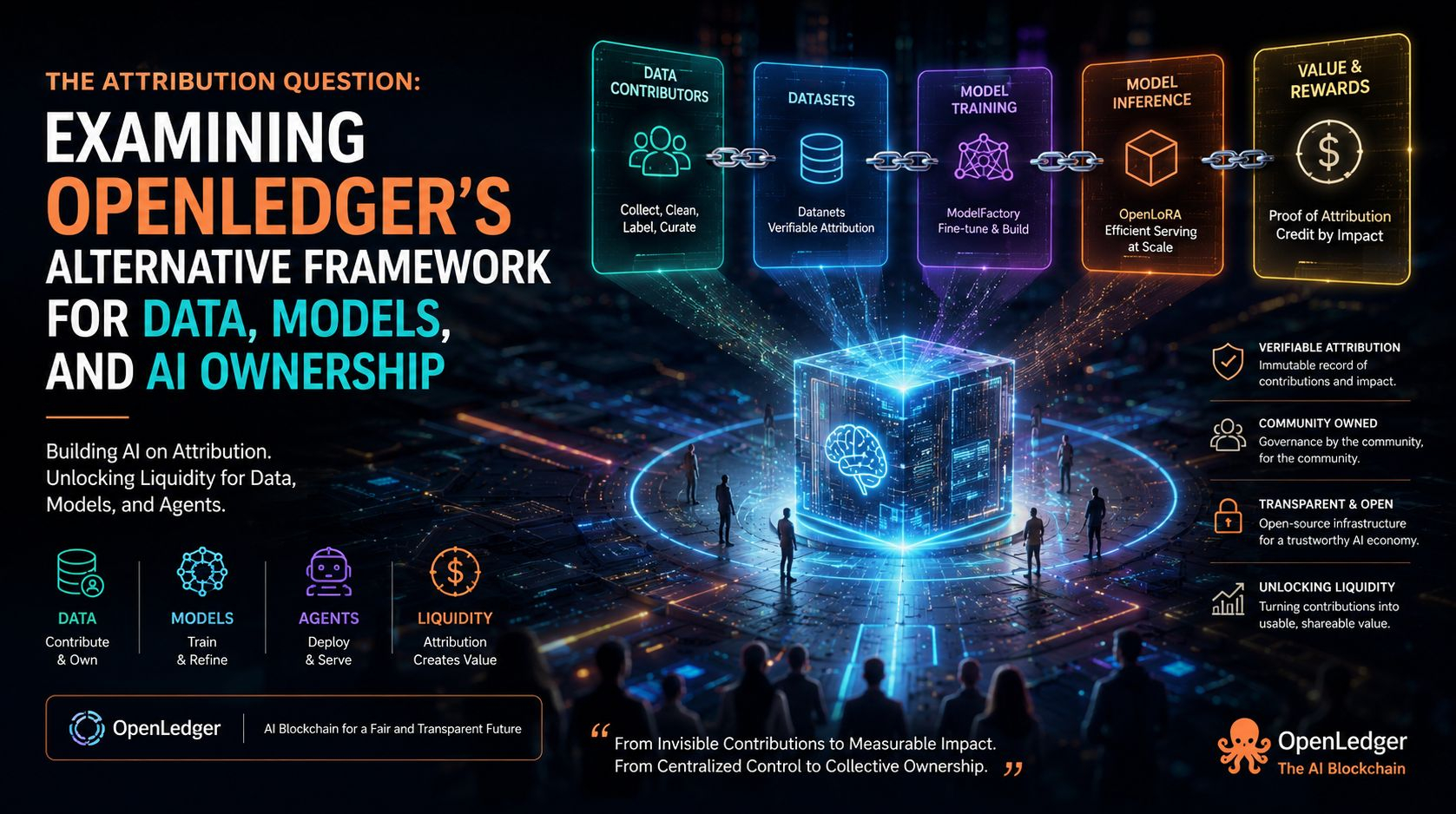
Ciò che mi interessa di OpenLedger è che non si presenta come una blockchain generica con un tema AI. Nella sua documentazione, definisce OpenLedger come un'infrastruttura AI-blockchain per addestrare e distribuire modelli specializzati utilizzando set di dati di proprietà della comunità, che chiama Datanets. Affermano anche che i caricamenti di set di dati, l'addestramento dei modelli, i crediti di ricompensa e la partecipazione alla governance avvengono tutti on-chain. Questa è una scelta di design seria, perché trasforma il protocollo in uno strato contabile per l'attività AI piuttosto che una ferrovia di regolamento passiva attorno ad essa. In linea di principio, questo consente al sistema di trattare i contributi come eventi di prima classe invece di affermazioni sociali post hoc. In pratica, naturalmente, la parte difficile non è registrare l'attività; è decidere cosa conta, come viene pesato e se i fatti registrati sono abbastanza significativi da supportare una reale coordinazione.
L'idea del Datanet è la più chiara espressione di quell'ambizione. OpenLedger descrive i Datanets come reti di dati decentralizzate che aggregano, validano e distribuiscono set di dati specifici per dominio per l'addestramento dei modelli, con attribuzione verificabile allegata ai contributi. Leggo questo come un tentativo di rendere lo strato di dati più intenzionale e ristretto nel suo ambito. Invece di un enorme corpus vagamente curato che alimenta un modello di uso generale, il protocollo preferisce repository strutturati attorno a casi d'uso specializzati. Questo ha senso, perché molti dei migliori sistemi AI non sono ampi in un senso filosofico; sono ristretti, disciplinati e costruiti su dati abbastanza buoni per un compito specifico. Ma la specializzazione ha il suo costo. Aumenta il costo di coordinamento nel trovare contributori, il costo di curatela nel mantenere la qualità e il costo di adozione nel convincere chiunque che un nuovo set di dati valga l'overhead di inserirlo in un sistema formale.
La Proof of Attribution è dove OpenLedger cerca di trasformare quella coordinazione in qualcosa di applicabile. La documentazione la descrive come un meccanismo crittografico che collega i contributi dei dati alle uscite dei modelli AI, mantenendo un registro immutabile dei contributi e assegnando credito e ricompense in base all'impatto dei dati. Questa è una risposta ponderata a uno dei più antichi problemi strutturali dell'AI: l'output è visibile, ma la catena causale dietro di esso non lo è. Se il meccanismo funziona come previsto, potrebbe dare ai fornitori di dati un modo per vedere quando il loro input ha avuto importanza e premiarli di conseguenza. Tuttavia, sono scettico nel modo giusto. L'attribuzione non è la stessa cosa della verità e la tracciabilità non è la stessa cosa della qualità. Un sistema può dimostrare che un set di dati è stato utilizzato senza dimostrare che il set di dati fosse buono, legale, imparziale o addirittura appropriato per il risultato che ha aiutato a produrre. Questa distinzione è dove molti sistemi di attribuzione diventano più fragili di quanto i loro diagrammi suggeriscano.
ModelFactory estende la stessa logica verso l'alto nella creazione di modelli. OpenLedger lo descrive come una piattaforma di fine-tuning per grandi modelli linguistici che opera sotto l'ecosistema OpenLedger e offre un'esperienza solo GUI per lavorare con set di dati autorizzati. Vedo questo come una mossa pratica, perché la maggior parte del lavoro utile nell'AI non viene svolto da persone che vogliono combattere con l'infrastruttura. Se il progetto vuole contributori, curatori e team più piccoli per partecipare, allora abbattere la barriera tecnica non è cosmetico; è essenziale. Tuttavia, il compromesso è familiare. Più una piattaforma è facile da usare, più deve nascondere la complessità dietro l'interfaccia, e più la credibilità del sistema dipende dal fatto che quella meccanica nascosta sia effettivamente affidabile. Un'interfaccia lucida può rendere un flusso di lavoro serio accessibile, ma non può sostituire regole affidabili sui diritti dei dati, sulla qualità dei set di dati o sulla governance dei modelli.
OpenLoRA spinge l'idea ulteriormente nel servire e nell'inferenza. I documenti affermano che è progettato per servire migliaia di modelli LoRA finemente sintonizzati su una singola GPU attraverso il caricamento dinamico degli adattatori, la fusione a memoria efficiente e ottimizzazioni come il parallelismo dei tensori, attenzione flash, attenzione paginata, quantizzazione e streaming di token. Questo non è un dettaglio casuale. Suggerisce che OpenLedger sta cercando di risolvere non solo il problema della costruzione di modelli specializzati, ma anche il problema di servire molti di essi in modo economico. In altre parole, il protocollo non sta solo immaginando proprietà e attribuzione; sta anche cercando di ridurre l'attrito nel distribuire molti piccoli modelli specifici per dominio piuttosto che un gigantesco monolite. Questa è una direzione convincente, perché si allinea a come molti lavori reali avvengono effettivamente. Ma crea anche un altro onere di esecuzione: più strati una piattaforma aggiunge, più posti ci sono per la complessità, la latenza e i costi di manutenzione per accumularsi.
L'ecosistema attorno al progetto mostra quanto sia ampia l'ambizione. Sul sito ufficiale, OpenLedger mette in evidenza prodotti come Explorer, Staking, AI Studio e un'esperienza con agente dal vivo chiamata OctoClaw, mentre la documentazione afferma che la governance è alimentata da un sistema ibrido on-chain che utilizza il framework modulare Governor di OpenZeppelin e i possessori di token partecipano alla direzione e agli aggiornamenti del protocollo. Questa combinazione mi dice che il progetto non è solo uno schizzo di ricerca. Sta cercando di diventare uno stack completo: onboarding dei dati, addestramento dei modelli, inferenza, governance e applicazioni a uso dell'utente. Rispettare la completezza di quell'ambizione è importante, ma la completezza può essere un peso. Più superfici un protocollo espone, più è difficile mantenere ciascuna di esse coerente, sicura e genuinamente utile. Un progetto può sembrare concettualmente elegante mentre fatica a far sentire indispensabili una o due delle sue superfici nell'uso quotidiano.
La mia principale riserva è che i sistemi ricchi di attribuzione tendono ad assumere un grado di input pulito che il mondo reale non fornisce affidabilmente. I dati sono disordinati prima di diventare on-chain. I diritti sono spesso ambigui. I contributori possono essere difficili da verificare. Le etichette possono essere sbagliate. Interi set di dati possono essere assemblati da fonti non uniformi e parzialmente affidabili. Il meccanismo di OpenLedger può registrare ciò che è accaduto, ma non può magicamente salvare input scadenti dal diventare output affidabili. È per questo che il progetto sembra più un esperimento contabile che una soluzione finita. La contabilità può migliorare l'equità, ma può anche creare una falsa sensazione di precisione se le misurazioni sottostanti sono deboli. Il sistema potrebbe risultare più prezioso proprio dove i dati sono già organizzati, professionali e cooperativi, che è anche dove il problema è più facile da risolvere in primo luogo.
C'è anche la questione dell'attrito nell'adozione. Un modello di set di dati di proprietà della comunità sembra più giusto dello status quo, ma la giustizia non produce automaticamente partecipazione. I contributori hanno bisogno di motivi per unirsi, gli acquirenti hanno bisogno di motivi per fidarsi e i costruttori hanno bisogno di un flusso di lavoro che sia più facile delle alternative centralizzate che già utilizzano. Se il protocollo è troppo rigido, sembrerà accademico. Se è troppo flessibile, l'attribuzione diventa cosmetica. Se la governance diventa troppo politica, il sistema potrebbe rallentare proprio quando ha bisogno di un'iterazione decisiva. Questi non sono problemi minori di implementazione; sono le modalità di fallimento ordinarie dei protocolli che cercano di andare oltre le semplici meccaniche di trasferimento e in coordinazione sociale. La stessa lista dei prodotti di OpenLedger suggerisce che comprende questo, ma riconoscere il problema non è la stessa cosa che risolverlo.
Penso che i beneficiari più plausibili non siano consumatori generici di AI, ma le persone più vicine alla conoscenza specializzata: fornitori di dati di dominio, costruttori di modelli di nicchia, piccoli team che assemblano set di dati autorizzati e comunità che si preoccupano di dimostrare il contributo piuttosto che semplicemente consumare output. Questi sono gli utenti che potrebbero guadagnare di più da un sistema che preserva la provenienza e distribuisce il credito. Le persone che rimangono fuori dal quadro sono altrettanto importanti, però: utenti occasionali che non si preoccupano dell'attribuzione, aziende che preferiscono procure più semplici e sviluppatori che vogliono scalare senza l'overhead del protocollo. Questo mi lascia con la domanda che non riesco a risolvere: se l'AI sta diventando uno strato di astrazione sul giudizio umano, può un sistema contabile basato su blockchain davvero preservare la catena umana del contributo senza trasformare tutto in una macchina più elaborata per descrivere il valore che ancora non può concordare su come misurarlo?