Oggi il mercato sembrava insolitamente piatto. Non il tipo di piatto negativo — solo... in attesa. Avevo una scheda aperta con delle velas che non stavo davvero guardando e in qualche modo mi sono ritrovato a fondo nei documenti di OpenLedger. Non era nei miei piani. Stavo cercando qualcos'altro.
Quindi ho iniziato a leggere su come $OPEN gestisce l'attribuzione dei dati e a un certo punto, intorno alla terza pagina, qualcosa è cambiato nel modo in cui lo pensavo.
Ecco la cosa a cui continuo a tornare: abbiamo inquadrato il problema dei dati AI in modo sbagliato. La conversazione è sempre riguardo l'accesso — chi ha dati, chi può usarli, chi viene bloccato. Ma OpenLedger, @OpenLedger , #OpenLedger , sta silenziosamente indicando un problema diverso. Non accesso. Provenienza.
La maggior parte delle persone che contribuiscono con dati ai sistemi di IA in questo momento non ha idea che il loro contributo sia anche avvenuto. Un dataset viene estratto, impacchettato, venduto, addestrato — e la persona che ha originariamente creato quel contenuto non ottiene esattamente nulla. Non solo nessun denaro. Nessun record. Nessuna traccia. Non è che il sistema sia ingiusto. È che il sistema non ha memoria.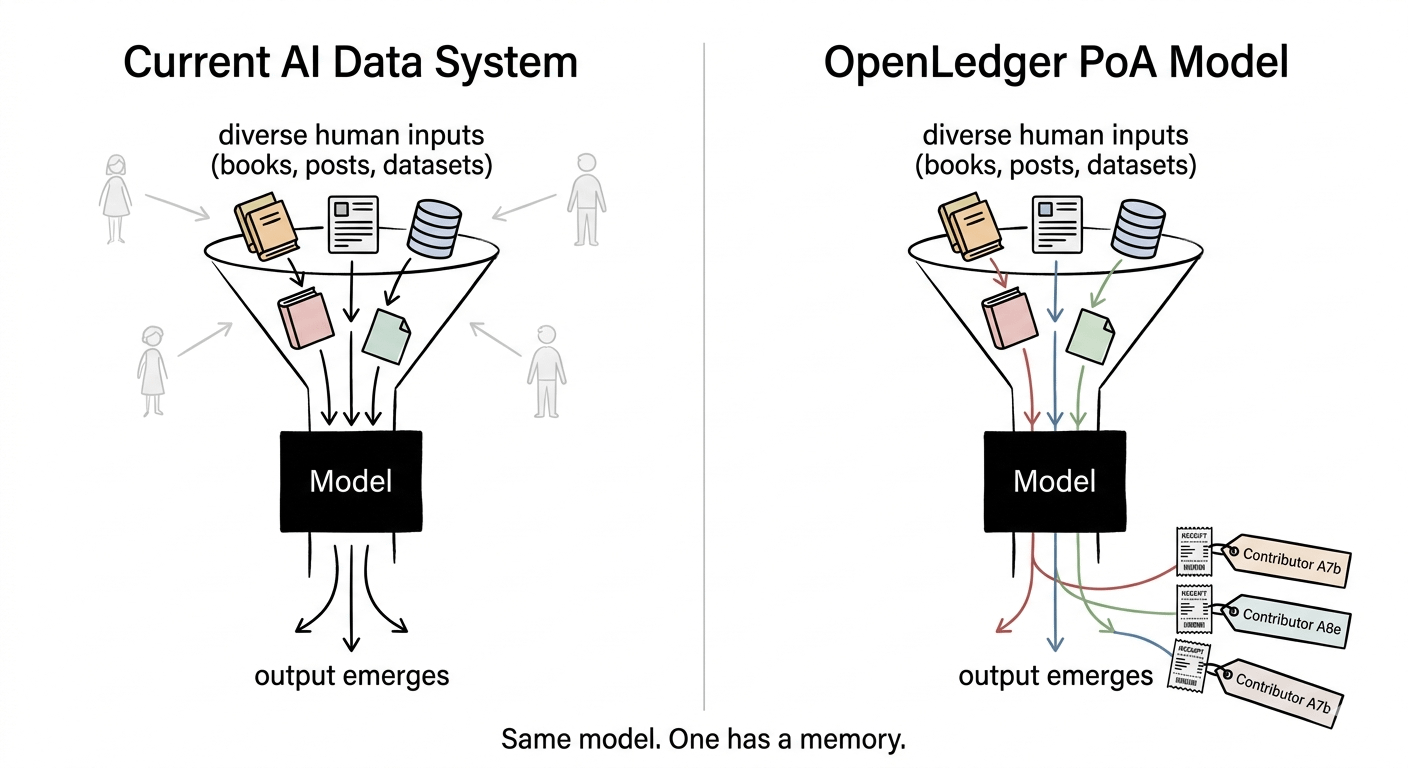
Quello che OpenLedger sta effettivamente costruendo — e questa è la parte che mi ha colpito — è meno come un marketplace e più come un registro del lavoro cognitivo. Ogni dataset, ogni passo di addestramento del modello, tracciato on-chain attraverso ciò che chiamano Proof of Attribution. L'idea è: se le uscite dell'IA possono essere ricondotte agli input che le hanno plasmate, allora la compensazione può seguire quel percorso automaticamente.
Pensavo fosse solo un modo più carino per fare licenze di dati. Ma in realtà è più strano e interessante di così. L'unità di valore non è il dataset stesso. È l'influenza che i dati hanno avuto sull'uscita del modello. Questo è un sistema di contabilità fondamentalmente diverso da qualsiasi cosa abbiamo utilizzato prima.
Ma ecco la parte che mi dà fastidio.
L'influenza è davvero difficile da misurare. Il whitepaper del PoA descrive due approcci — approssimazioni della funzione di influenza per modelli più piccoli, e attribuzione dei token basata su array di suffissi per LLM. Ho letto quel paragrafo tre volte. La metodologia è reale, la matematica esiste, ma su scala? Attraverso miliardi di token di addestramento? Attribuire quale pezzo di dati ha influenzato quale uscita inizia a sembrare meno contabilità e più archeologia.
E non sono completamente convinto che questo regga sotto pressione. Quando un modello produce qualcosa di prezioso, rintracciare pulitamente un contributore di dati assume una sorta di causalità pulita che potrebbe non esistere. L'addestramento è disordinato. L'influenza si mescola. Due contributori potrebbero aver inviato dati quasi identici — chi ottiene il credito di attribuzione? Come lo dividi? Il whitepaper accenna a questo ma non lo risolve completamente.
Il che significa che il sistema che dovrebbe finalmente compensare i lavoratori della conoscenza umana potrebbe finire per premiare chi ha inviato dati più facili da attribuire piuttosto che i più preziosi. Questa è una differenza sottile ma importante.
Al momento, il layer di coinvolgimento più attivo nell'ecosistema OpenLedger è l'Arena Yapper — un pool di premi di 2 milioni di token OPEN per i primi 200 contributori sociali nella leaderboard di Kaito. Non è una critica, avviare una comunità prima che l'infrastruttura sia matura è semplicemente come funziona. Ma significa che le persone che attualmente guadagnano $OPEN sono per lo più persone che parlano di OpenLedger, non che lo alimentano di dati.
I veri datanets, il ModelFactory, il sistema di attribuzione — questi sono il gioco a lungo termine. La domanda è se la comunità che si sta costruendo ora sarà quella che si presenterà per il lavoro più duro e meno affascinante di contribuire con dati di alta qualità quando l'infrastruttura sarà pronta.
Quella lacuna — tra chi viene premiato per primo e per chi il sistema è teoricamente costruito — è la cosa su cui continuo a riflettere.
Perché se il Proof of Attribution funziona, è genuinamente uno dei cambiamenti strutturali più interessanti nel modo in cui viene costruita l'IA. Il modello smette di essere una scatola nera che consuma silenziosamente la conoscenza umana e diventa qualcosa che porta una ricevuta. Ogni uscita con una linea di discendenza tracciabile. Ogni contributore con una rivendicazione verificabile.
Non è un'idea da poco. È una relazione completamente diversa tra la conoscenza umana e l'uscita della macchina.
Probabilmente guarderò semplicemente come si sviluppa l'attività del datanet nei prossimi mesi. Vedere se i sentieri di attribuzione on-chain iniziano a mostrare una reale profondità o se rimangono per lo più a livello sociale. La squadra e gli sbloccamenti degli investitori non arrivano fino a settembre comunque, quindi c'è tempo.
Il mercato sembra ancora decidere qualcosa. Non sono sicuro di cosa ancora.