
Earlier this year, I came across a story involving Air Canada that stayed in my head much longer than I expected.
A customer had relied on information provided by the airline's chatbot regarding bereavement fares. The information come out to be wrong, and the dispute eventually reached court. What made the story memorable wasn't the compensation itself. It was the argument that followed.
Air Canada suggested that the chatbot was responsible for its own actions.
The court wasn't convinced.
At first, it looked like a routine customer-service mistake. Companies publish incorrect information all the time. But the more I thought about it, the more it felt like a preview of a problem that becomes much harder once AI systems move beyond answering simple questions.
Most people encounter AI at the very end of the process.
A response appears.
A recommendation is generated.
A decision is suggested.
What usually remains hidden is everything that happened before that moment.
The data.
The context.
The tools.
The assumptions.
The chain of events makes the final output.
Just think .. receiving an AI-generated recommendation that turns out to be completely correct. The answer solves the problem. The result is useful. Nobody complains.
Then someone asks a simple question:
"How did the system arrive there?"
Suddenly things become less clear.
Which dataset influenced the response?
Which documents shaped the context?
Which external tools supplied information?
Which parts came from retrieval and which came from the model itself?
In many systems, that trail disappears the moment the answer appears on screen.
That is the part I keep coming back to.
Not whether the answer is right.
Whether the path behind it remains visible.
As AI systems become more capable, they also become more layered. Future agents won't rely on a single model sitting inside a chat interface. They will pull information from knowledge bases, interact with APIs, access real-time data, use external tools, follow prompts written by developers, and combine information originating from many different contributors.
At that point, understanding where an answer came from becomes a challenge of its own.
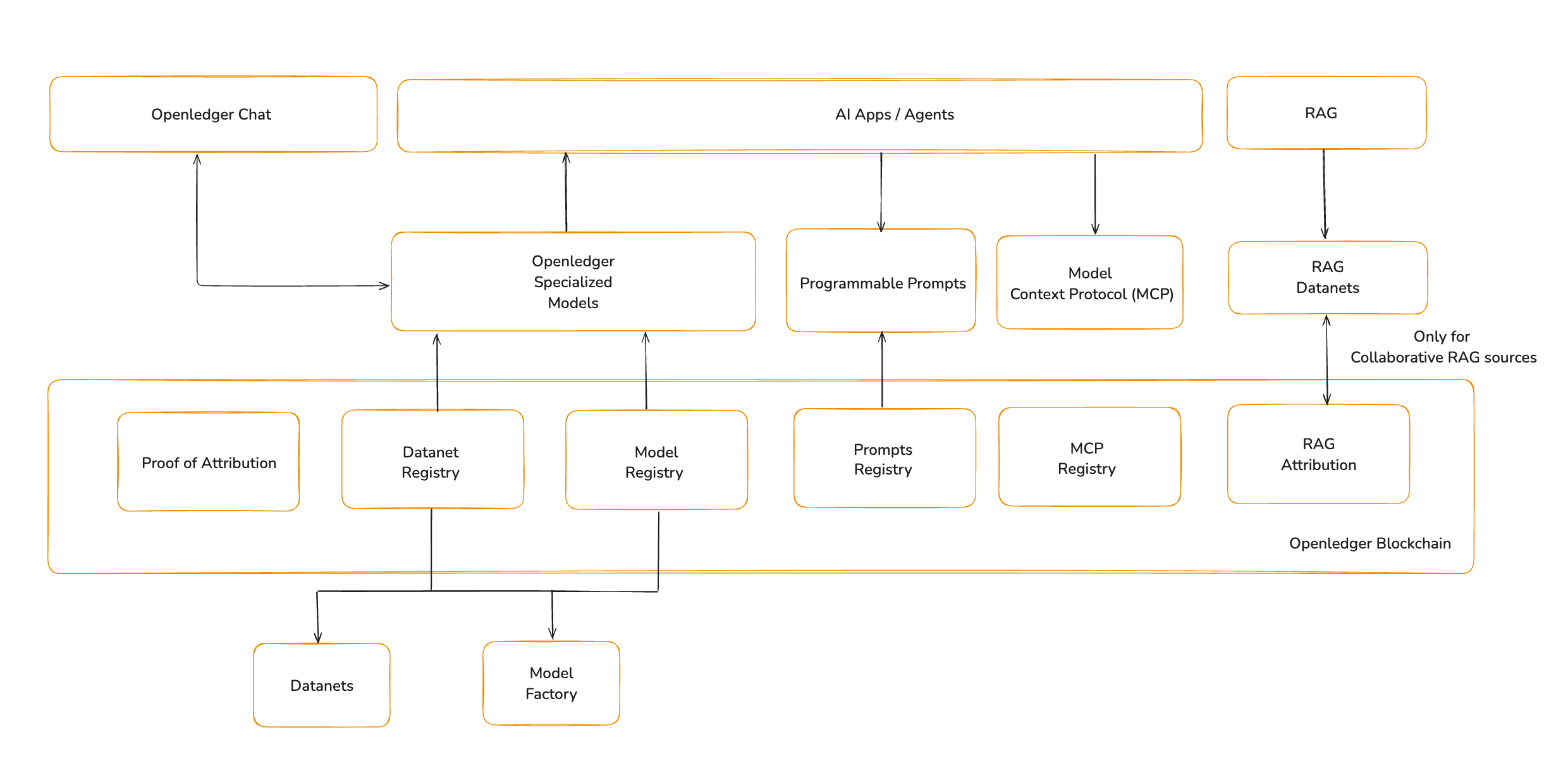
This is where the OpenLedger architecture became interesting to me.
The ecosystem starts with Datanets, where contributors provide domain-specific datasets that can be reviewed, scored, and attributed. Those datasets can then move through ModelFactory to create specialized models, while OpenLoRA makes it possible to serve many model variants efficiently without requiring every model to operate as its own isolated stack.
The technical pieces themselves are useful, but they weren't what caught my attention.
What stood out was the attempt to keep influence visible.
An agent operating inside OpenLedger can access external information through MCP, retrieve contextual knowledge through RAG systems, and execute behavior through prompts. According to OpenLedger's longer-term vision, these interactions don't have to disappear once execution is complete. MCP tools can be registered, versioned, and attributed onchain, creating a record of which tools participated in producing an outcome.
The same idea appears again inside RAG Attribution.
Normally, retrieved information becomes part of a response and the connection to its source fades into the background. OpenLedger proposes preserving that connection. When knowledge is retrieved during reasoning, the contribution behind that information can remain visible rather than becoming anonymous context.
Proof of Attribution extends the concept even further.
Instead of treating intelligence as something that appears magically from a model, the system attempts to measure influence itself. The goal is to understand which data contributed, which participants played a role, and how value should flow once the system begins generating useful outputs.
The more I looked at the stack, the less it felt like another AI platform and the more it felt like an attempt to answer a question most systems quietly ignore.
Once an output is generated, the trail usually ends.
OpenLedger seems to be trying to keep that trail alive long enough to see who contributed, what influenced the result, and where the value actually came from.
I think that distinction becomes more important as AI moves into areas where mistakes carry real consequences.
Research.
Finance.
Healthcare.
Governance.
In those environments, people will care about more than performance metrics. They will want to know what shaped the decision, which sources were involved, and whether the reasoning can be inspected afterward.
What worries me isn't an obviously bad answer.
Those are often easy to spot.
The harder problem is an answer that looks perfectly reasonable while hiding the path that produced it.
Because eventually trust may depend on more than accuracy alone.
Being right may not be enough if nobody can explain how the system got there.

