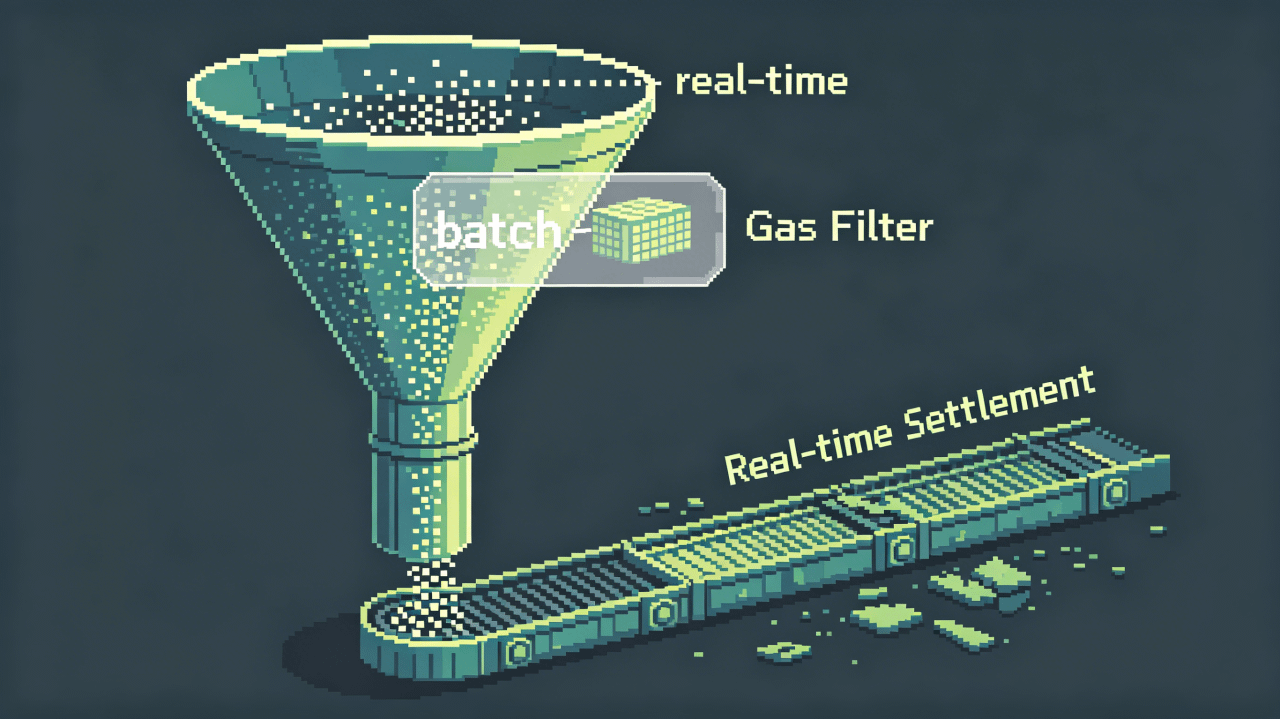
OpenLedger有一台演示机,一直在循环播放同一个画面——你的数据被AI调用了,归因引擎精准捕捉,智能合约自动执行,你的钱包里立刻多了一笔钱。这个画面里,每一份贡献都穿着“实时”的外套,每一笔分账都带着“立刻”的标签。
但演示机不会告诉你一件事:链上每记一笔账,是要付手续费的。而这份手续费的数字,跟你贡献一次能分到的钱,很可能不在同一个数量级。
OpenLedger跑在OP Stack上,数据可用性交给EigenDA。这种配置的单笔简单转账,大概在零点零零一美元到零点零一美元之间浮动,看网络拥不拥堵。但归因分账不是简单转账——它要写归因记录、触发分账合约、可能还涉及多个代币转移,是一笔带计算和存储的完整交易。取个保守中值,每笔归因结算的手续费大约零点零零五美元,换算过来就是三四分钱。

现在翻到另一边,看看一次AI调用能让长尾贡献者分到多少。大模型API调用的批发价,目前大概是几分到几毛美元。而在后缀数组归因机制下,你的数据要被系统识别为“有贡献”,得是模型这次输出里恰好有一段能匹配你贡献的文本。就算匹配上了,你这份贡献在本次调用总收益里的占比,可能只有千分之一、万分之一。两个数字乘在一起,长尾贡献者从一次AI调用里实际能分到的,大概率是零点零零一美元、零点零零零一美元这个量级——比那笔链上分账要付的零点零零五美元小了一到两个数量级。
数学不会哄人。数据被调用了一次,链上想把这笔钱分给你,分账的手续费比分给你的钱还多。从全网视角看,这笔交易是负的——网络花了几倍的成本,去完成一次几乎没人在乎的价值转移。这种负效率行为,在任何设计合理的微支付系统里都不会被允许逐笔发生。
所以系统的工程侧没有第二条路可走。把成千上万笔微归因攒进一个池子,攒到一个周期再一次性汇总上链。这是物理约束下的最优解,也是唯一解。批量结算、定期清算——这些词在技术上没有任何错,但它跟演示机里那个画面之间,隔着一道Gas费划出来的技术鸿沟。
“每一份贡献都被精确归因、自动分账”——这句话会在每个读到它的人脑子里种下一个默认假设:精确等于实时,自动等于立刻。但工程侧能做的是前者:归因引擎在链下把账算得明明白白,谁的贡献占比多少、该分多少钱,一清二楚。做不到的是后者:因为链上空间不免费,所以不能每算完一笔账就立刻往链上写一次。最后到用户端的体验,是某天钱包里多了一笔合并结算的金额,对应过去某个周期里自己也不太确定来源的若干次调用。归因是精确的,但精确不再等于“每一次都能被你看见”。
这不是项目方的问题。所有微支付协议都踩在同一块地板上,没有谁能绕开这道算术题。但作为观察者,在把PoA这套叙事放进自己的判断框架之前,应该先做一次概念替换:把“实时、每一次、每一笔”这些词,从脑子里拿掉,换成“批量、周期性、汇总结算”。这两套词汇描述的不是同一个系统。前者是宣传话术在你脑子里搭建的模型,后者是Gas费算式逼出来的工程现实。演示机里那个画面还在循环播放,但每次有新闻报道又在讲同一套“实时归因”的故事时,你手边只需要放一台计算器,按几下,就能听到机器背后那扇写着“物理约束”的门,轻轻关上的声音。$OPEN #OpenLedger @OpenLedger