Il mercato sembrava più tranquillo del solito oggi. Non morto — solo quella strana energia intermedia dove nulla sta pompando ma niente sta davvero sanguinando neanche. Alla fine, ho solo... scrollato. Guardando cose che avevo salvato ma che non avevo mai realmente letto.
È così che sono finito in OpenLedger.
Non lo cercavo specificamente. Stavo pensando al problema dei dati dell'IA in generale — sai, quella sensazione vaga e scomoda che ogni modello che usi sia diventato più intelligente consumando le cose create dalle persone, e nessuno ha ricevuto nulla in cambio. Scrittori, programmatori, ricercatori. Solo... contribuenti silenziosi a qualcosa che non possederanno mai un pezzo.
Quindi ho iniziato a leggere di $OPEN , e all'inizio sembrava un'altra proposta di "stiamo sistemando l'AI". Stavo quasi per chiudere la scheda.
Ma poi qualcosa di piccolo ha catturato la mia attenzione e non riuscivo a lasciarlo andare.
OpenLedger non sta solo cercando di pagare le persone per i dati. Sta cercando di rendere il contributo di dati tracciabile — come, permanentemente, verificabilmente tracciabile — ai modelli che realmente li hanno usati.
E ho dovuto riflettere su questo per un secondo. Perché queste sono due cose molto diverse.
La maggior parte delle persone, quando sente "fatti pagare per i tuoi dati," immagina qualcosa come un sondaggio. Invi un qualcosa, qualcuno ti paga una tariffa fissa, fatto. Transazionale. Disconnesso dal risultato.
Quello che OpenLedger sembra cercare è diverso: se un modello addestrato sul tuo dataset diventa più intelligente, viene utilizzato di più, genera valore — dovresti avere un diritto su quello. Non solo la tariffa di invio una tantum. Il contributo stesso viene registrato on-chain, legato alla performance del modello, tracciabile nel tempo.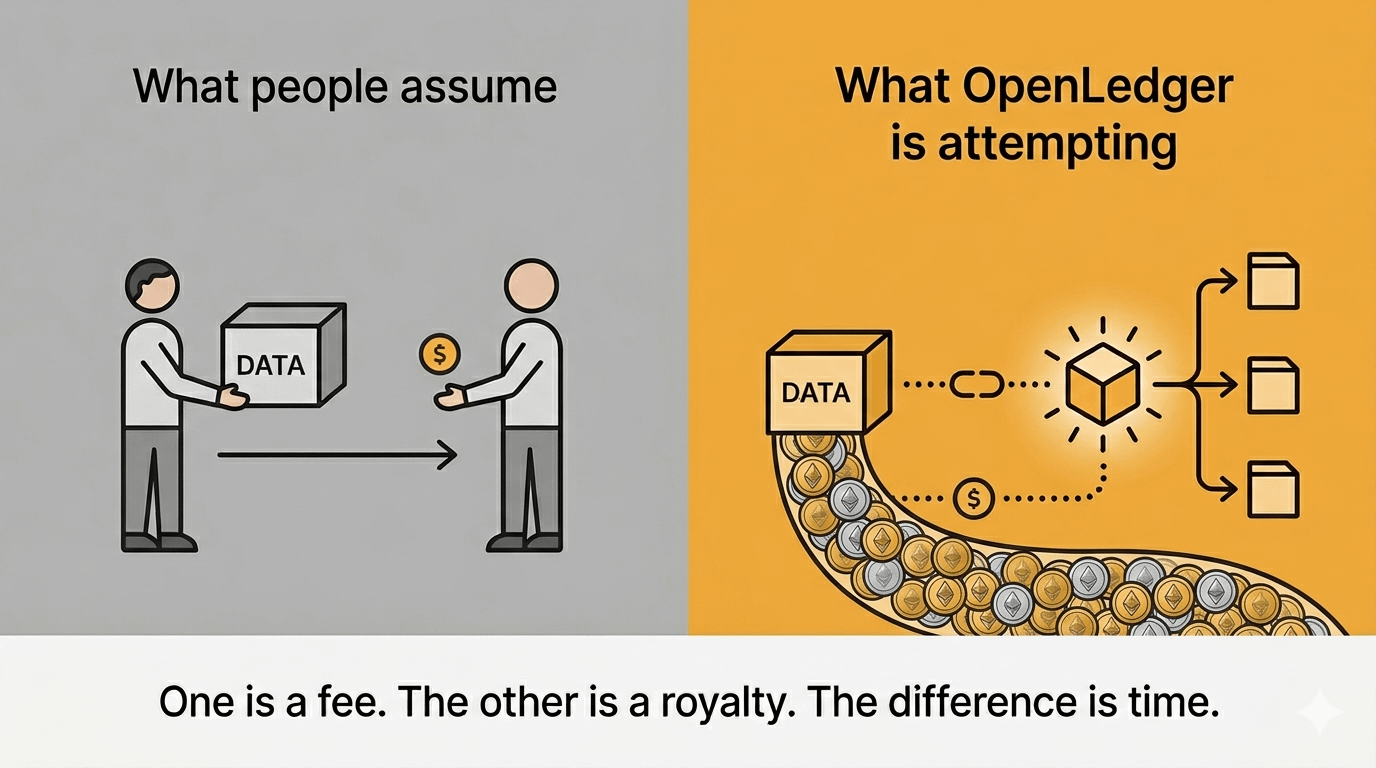
Pensavo fosse solo una versione più carina della stessa cosa. Ma in realtà non lo è.
È più vicino a come funzionano i diritti d'autore nella musica. Scrivi una canzone una volta, viene usata mille volte, continui a guadagnare. Tranne che la "canzone" qui è un dataset. E i "volte che viene usata" sono ogni esecuzione di inferenza a valle.
Quella realizzazione mi ha fatto sentire un po' a disagio. Perché se funziona davvero — se il contributo è veramente tracciabile a quel livello — allora tutto il modo in cui pensiamo ai mercati di dati AI sembra stranamente primitivo in questo momento.
Ma ecco la parte che mi disturba.
La tracciabilità suona pulita in teoria. In pratica, i modelli non usano i dati uno-a-uno. Li mescolano, li trasformano, fondono diecimila contributori in un aggiornamento di peso che non assomiglia a nessuna fonte singola. Quindi, come tracci il tuo contributo attraverso tutto ciò? Chi decide quanto credito riceve il tuo dataset rispetto agli altri 40.000 che si sono allenati insieme?
Non sono completamente convinto che questo regga sotto pressione. Il problema di attribuzione nel machine learning è genuinamente difficile — non "abbiamo bisogno di strumenti migliori" difficile, più come "questo potrebbe essere filosoficamente irrisolvibile" difficile. E se il modello di attribuzione è anche solo leggermente manipolabile, l'intera faccenda inizia a sembrare meno come un sistema di diritti d'autore e più come un sistema di punti che sembra giusto ma non lo è.
Non sto dicendo che fallisce. Non lo so ancora genuinamente. Ma penso che le persone che si tuffano in $OPEN senza porsi quella domanda stiano saltando la più importante.
Quello che rende interessante questa situazione — e continuo a tornare su questo — è chi ne è colpito se funziona.
Non sono i trader retail, davvero. Sono le persone che producono dati strutturati e di alta qualità. Ricercatori. Esperti di nicchia. Persone in campi dove i buoni dati di addestramento sono veramente scarsi e genuinamente preziosi. Se queste persone iniziano a essere compensate proporzionalmente a quanto i loro dati migliorano gli output dei modelli... questo cambia la struttura degli incentivi attorno allo sviluppo dell'AI in un modo difficile da pensare completamente in questo momento.
Riposiziona silenziosamente $OPEN da "token crypto AI" in qualcosa che potrebbe realmente avere una domanda ricorrente legata all'uso reale del modello. Non una domanda da hype. Domanda di utilità. Quella che non scompare quando la narrativa cambia.
Pensavo fosse solo un altro marketplace di dati. In realtà sta cercando di essere qualcosa di più simile a uno strato di attribuzione sotto l'AI.
Se questo sia raggiungibile è un'altra domanda.
Comunque. I grafici continuano a sembrare poco convincenti per me. Probabilmente continuerò a tenere d'occhio questo da lontano per ora — vedere come si sviluppa realmente il lato dei contributori di dati prima di formare un'opinione più forte.
Sto ancora pensando alla questione dei diritti d'autore però. Quella parte non mi ha lasciato.