Avevo alcune ore senza nulla di urgente, quindi sono tornato a qualcosa che avevo intenzione di esaminare a fondo — @OpenLedger
Ci avevo già dato un'occhiata in passato. Ho controllato il dashboard, ho osservato un blocco o due che passavano, ho visto i micro-pagamenti arrivare. Era abbastanza interessante da aggiungerlo ai preferiti e poi dimenticarmene per un po'. Questa volta mi sono seduto con calma.
E intorno alla seconda ora, qualcosa è cambiato nel modo in cui lo leggevo.
Il modo in cui la maggior parte delle persone parla di OpenLedger — compreso gran parte del contenuto che ho visto — è fondamentalmente: possiedi i tuoi dati, vieni pagato quando l'IA li utilizza. Questo è il titolo. Il contributore di dati inserisce qualcosa, il modello si allena su di esso, il contributore guadagna. Storia pulita. Ha senso a prima vista.
Ma non è davvero ciò che sta accadendo meccanicamente.
Quello che fa il sistema di Proof of Attribution di OpenLedger è più vicino a: vieni pagato quando avviene l'inferenza. Non l'addestramento. Non il caricamento. Non quando i tuoi dati vengono assimilati in qualche modello. Il trigger di pagamento è l'inferenza attiva — un modello AI che esegue attivamente una query e attinge da fonti attribuite in tempo reale.
Pensavo che fossero la stessa cosa. Non lo sono.
L'addestramento è un evento una tantum. Accade, il modello assorbe i dati e il tuo contributo viene incorporato in qualcosa che non puoi davvero tracciare dopo il fatto. L'inferenza è continua. È ogni query, ogni chiamata, ogni output che il modello produce che tocca il tuo pool di dati attribuiti. Il meccanismo di royalty non guarda indietro a ciò che ha plasmato il modello — sta osservando ciò a cui il modello si rivolge in questo momento.
Quella distinzione è rimasta con me per un po'.
Perché ecco cosa significa realmente: il valore del tuo contributo non è fisso nel momento in cui carichi. Fluttua con la frequenza con cui il modello ha bisogno di ciò che gli hai dato. Se hai contribuito con qualcosa di altamente specifico — conoscenza di nicchia, formato raro, etichettatura di casi limite — e la domanda aziendale per quella cosa specifica aumenta, il tuo tasso di pagamento aumenta con essa. Non perché tu abbia fatto qualcosa di nuovo. Solo perché i modelli di utilizzo sono cambiati.
Che è davvero diverso da come ha funzionato la monetizzazione dei dati in precedenza. Non stai vendendo qualcosa una sola volta. Stai tenendo qualcosa che paga in base all'utilizzo. Più vicino a una struttura di royalty che a una vendita.
Ho iniziato a pensare meno a questo come a un "mercato dei dati" e più come a un'infrastruttura passiva. Il contributore di dati diventa qualcosa come un nodo in una rete che viene pagato in base al traffico delle query.
Ma ecco la parte che mi infastidisce.
Quel modello funziona solo se c'è una vera inferenza aziendale sostenuta su larga scala. E in questo momento — da quello che posso osservare — il lato dei contributori sta crescendo molto più velocemente del lato della domanda. Ci sono persone che caricano dati, guadagnando micro-pagamenti, guardando dashboard. L'infrastruttura di offerta è funzionale.
Il lato aziendale? Quella è la parte che sembra ancora precoce. E intendo davvero precoce. Non "sta arrivando" presto. Più come: le rotaie ci sono ma i treni non stanno ancora viaggiando al volume che renderebbe significativa la matematica delle royalty per la maggior parte dei contributori.
Non sono sicuro di quanto tempo duri questo divario prima che l'entusiasmo dei contributori inizi a raffreddarsi. Le tariffe di pagamento che stavo osservando non erano nulla — ma non erano nemmeno numeri "questo cambia il mio mese". E se la domanda non scala per soddisfare l'offerta già contribuita, l'intero sistema di attribuzione inizia a sembrare una soluzione elegante a un problema che non ha ancora abbastanza clienti.
Non è necessariamente un difetto fatale. Ma è la cosa che terrei d'occhio.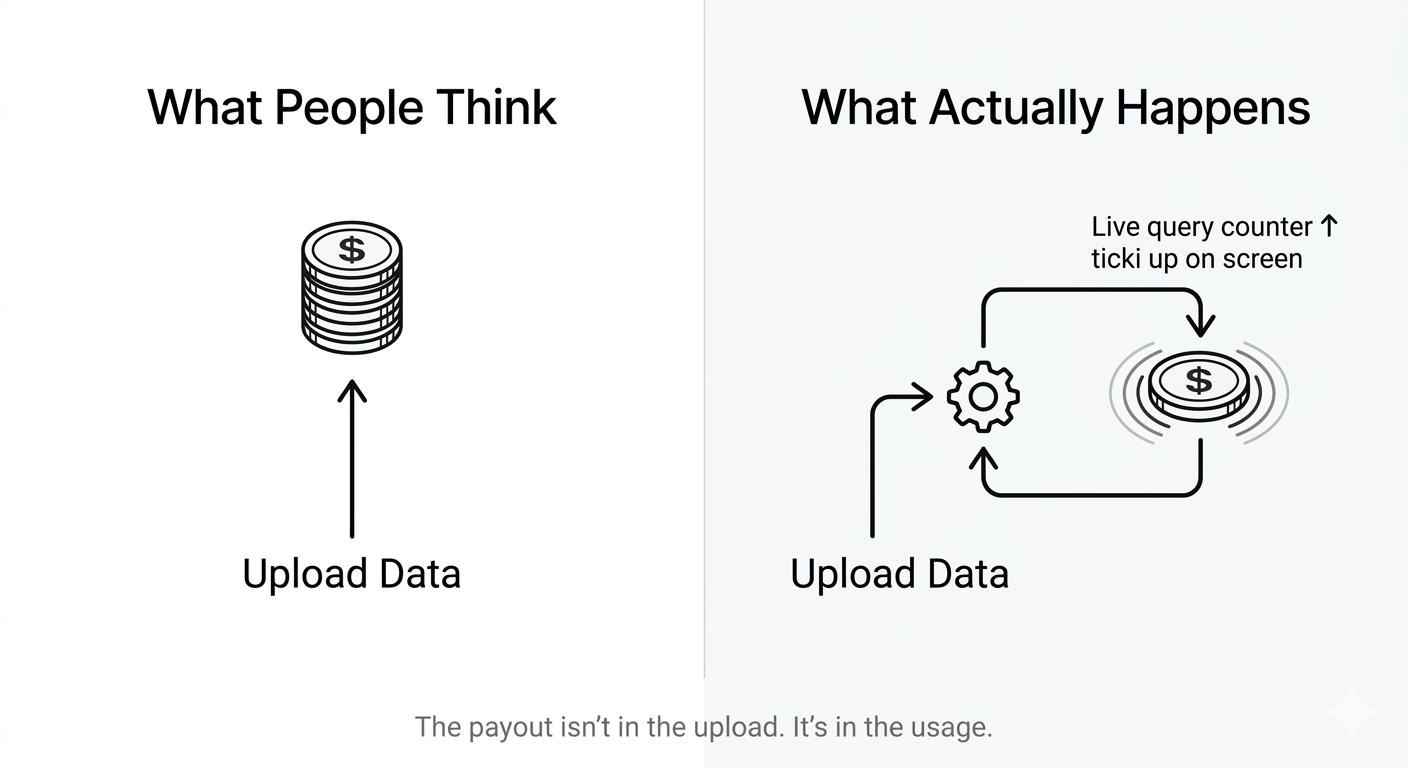
C'è anche uno strato a cui continuo a tornare: chi beneficia realmente di più da questo in questo momento? L'upload casuale — qualcuno che carica un documento o due nel sistema — probabilmente sta ottenendo più esperienza che reddito. La curva di pagamento favorisce pesantemente i contributori che operano a volume, con dati strutturati, in formati di cui il modello ha realmente bisogno. C'è un tetto sulla partecipazione passiva che la maggior parte delle persone non supererà.
Che forse va bene. La maggior parte delle prime infrastrutture ha questa forma. Ma vale la pena sapere fin dall'inizio che "puoi guadagnare dai tuoi dati" e "guadagnerai in modo significativo dai tuoi dati presto" sono ancora frasi piuttosto diverse.