翻项目文档时,有一个信号能比路线图更早告诉我这团队在卖什么:他们反复往你脑子里刻的那个词。不是技术名词,是那种读起来让人心头一热、觉得“终于有人来解决这个问题了”的形容词。这种词的能量很大,大到有时候连用它的人也控制不住——它会把产品本来没打算解决的那部分期待,也一并吸过来。
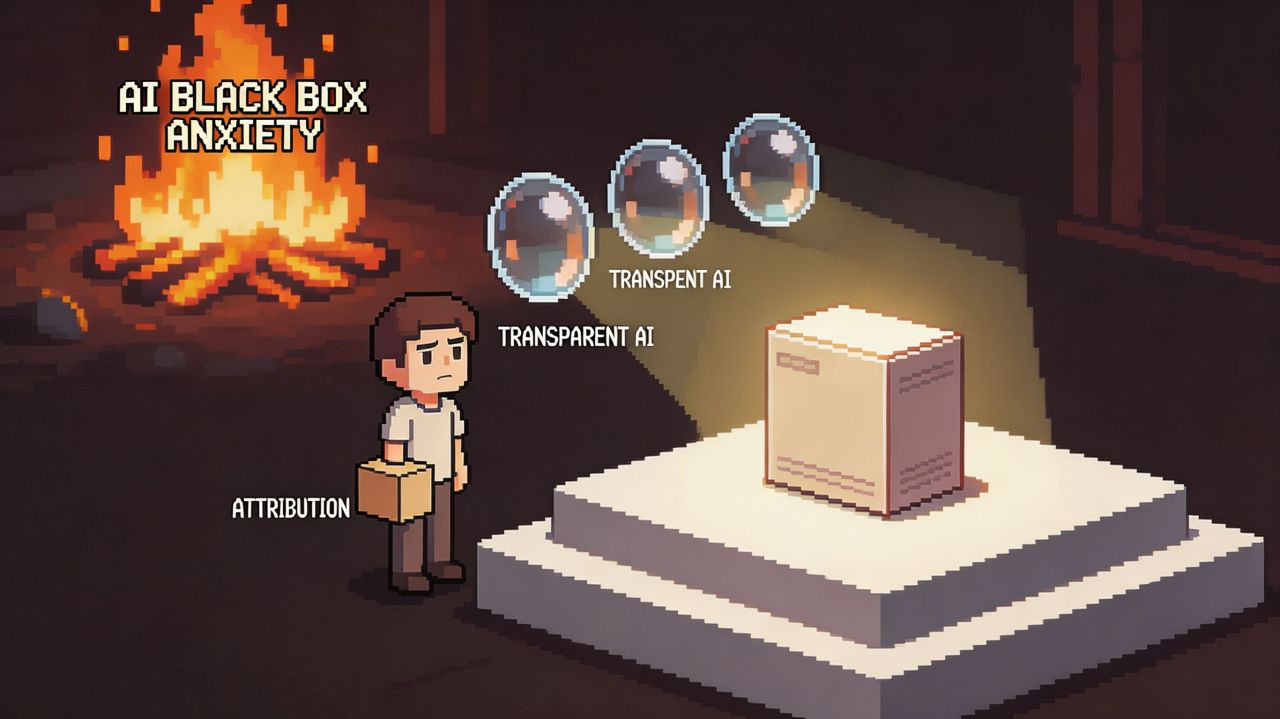
最近在翻OpenLedger的官方材料,我就被这样一个词反复击中:透明。透明AI、可验证AI、让AI摆脱黑箱。这三个词排在一起,任何一个关注AI行业的人都会在脑子里自动弹出一个画面:终于有人要拆开那个神经网络了,让我们看清楚模型内部到底在怎么思考、为什么在那个关头做了那个决定。这个画面值钱,因为它踩中的是整个AI行业最深的那道集体焦虑——我们正在把越来越多的决策权交给一个自己根本不理解的东西。
但OpenLedger的技术栈,其实讲的是另一个故事。
“透明AI”这个词,在真实语境里承载了两层完全不同的意思,只是碰巧叫了同一个名字。第一层,是治理和审计层面的透明——训练数据的来源可查、贡献的归属可追溯、利益分配有据可依。这一层,OpenLedger确实在做,而且做得不算差。它的PoA归因引擎、suffix-array数据追踪、链上不可篡改的贡献账本,全是对着“谁贡献了什么、谁该拿多少钱”这条线去的。
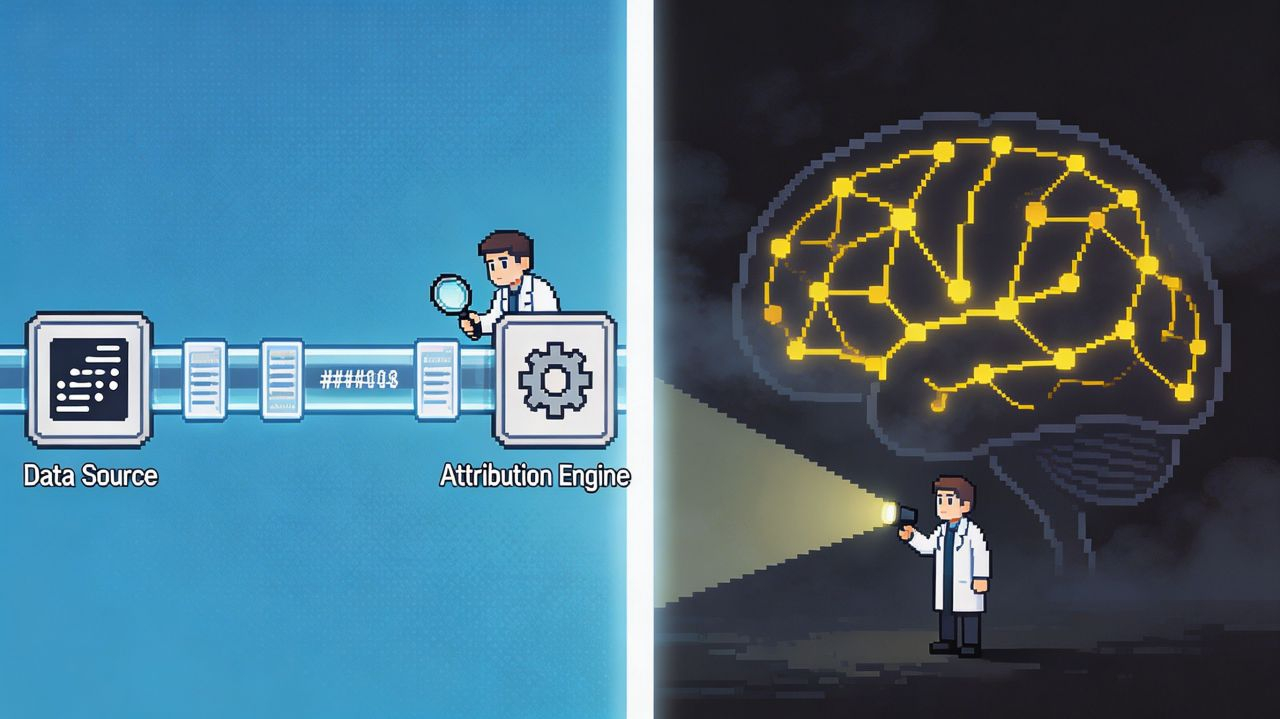
第二层,是认知层面的透明——打开模型内部的决策黑箱,让人类能理解AI在某个关键时刻是怎么推理的、激活了哪些知识、为什么选A不选B。Anthropic的CEO自己说过一句很重的话:“我们不知道我们造的AI是怎么工作的。”整个机制可解释性领域,就是在试图回答这个问题。这层透明至今没有任何人解决,它是一个仍然摆在AI学界前沿的开放课题。
这两层透明,一个是查账的透明,一个是读心的透明。前者问你用的是谁家的料,后者问你脑子里到底在转什么念头。它们指向的是完全不同的问题,需要的是完全不同的技术路径。OpenLedger的整个技术栈——OP Stack做底层、EigenDA做数据可用性、PoA做归因、suffix-array做文本匹配——全部是对着数据来源去的,没有任何一个工具是用来解读模型内部认知过程的。哪怕它把数据归因做到极致,做到每一次调用、每一份贡献都被完美记录,那个困扰所有人的“模型怎么思考”的黑箱,纹丝未动,从来不在它的射程之内。
而OpenLedger激起的那种情感共鸣,靠的恰恰是第二个版本。当你听到“透明AI”这四个字时,心里那个反应——“终于有人要解AI黑箱了”——指向的是认知层面的透明,是对未知决策过程的恐惧被缓解的期待。但它的产品实际交付的,是数据来源的可审计性。这两者之间的距离,就是那个词额外借来的光。
我不是说这是故意误导。在加密圈做项目,选一个能引发情感共鸣的大词是生存法则,不选反而是对自己残忍。但作为读文档的人,你的任务是把听到的“透明”拆开,分清楚哪个画面是真实产品撑得起来的,哪个画面是被词本身额外赠送的。
OpenLedger做的那层透明——数据可追溯、归因可审计——在工程上有价值,在逻辑上能自洽。但每次看到“transparent AI”这个词出现在它的首页上,我会自动在脑子里把它补成“transparent data attribution”。多三个词,描述的东西就从“打开黑箱的钥匙”变成了“数据来源的账本”。前者值千金,后者值硬功夫,两件事都值得被认真对待,但得先把它们分开看。混在一起,记下的就是一笔它没解决过的功劳。@OpenLedger