每次看 OpenLedger 讲它的 Datanet——领域专家众包数据,医生贡献医疗知识、律师贡献判例、金融分析师贡献市场洞察——我脑子里都在跑一个很基础的算式,关于这些专家的时间到底值多少钱。
OpenLedger 整套叙事有一个不被点破的前提:真正有价值的垂直领域数据,得真正的专家来贡献。一份病例分析的价值,取决于它是不是从临床实战来的;一份合同条款分析的价值,取决于它是不是有诉讼经验的律师写出来的。如果贡献者是个挂着医学头像的爱好者,这份数据的训练价值,可能还不如公开数据集里随便抓的一段。
这件事 OpenLedger 不会强调,但它整套激励机制的合法性,完全建立在"我们能吸引到真专家"这个假设上。
我们来算这个假设有多牢。
任何合理估算下,一个三甲主治医生的业余时间机会成本,都在每小时几百块人民币这个量级;一位顶级专科律师更高。这是他们业余时间的市场底价。然后看 OpenLedger 能给到什么:补贴期里一个数据贡献者通过 PoA 加 grant 拿到的 token,折算下来大概一份贡献几十到几百块——而且这是基金会激励池补贴出来的、价值含相当大泡沫的 token。补贴退潮后,真正靠"AI 调用归因"产生的分账,我前几天算过,长尾贡献的边际收益是 $0.001 这个量级。
把两边数字放在一起,真专家来 OpenLedger 贡献数据,在当前价格下完全不成立。
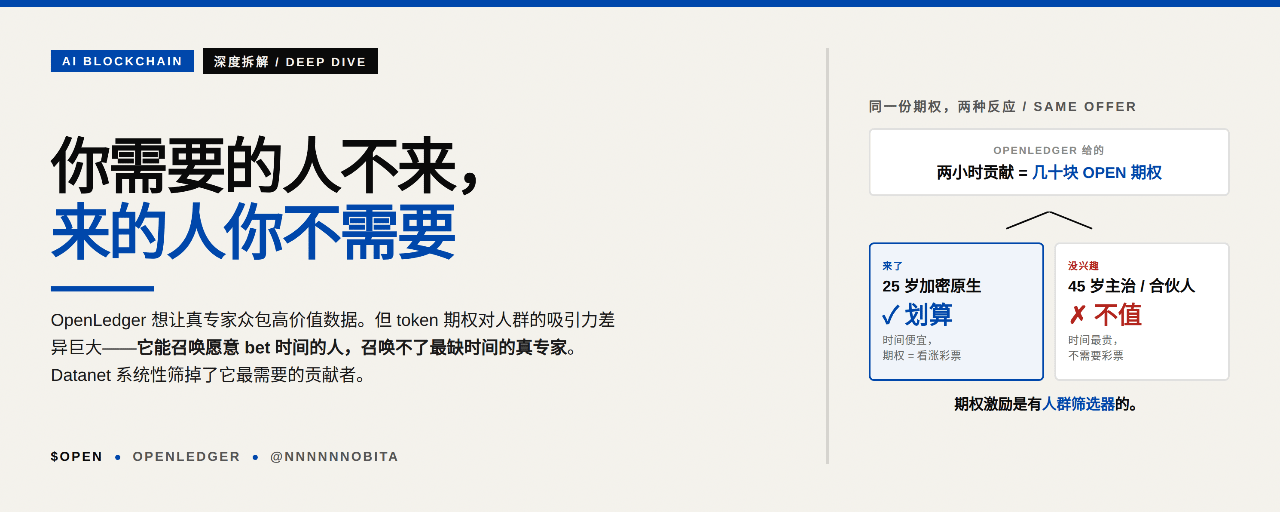
到这里有一个明显的反驳必须接住:token 是看涨期权。一份贡献现在值 $50,如果协议长成,token 10x、100x,这 $50 变成 $500 甚至 $5000。crypto 激励的全部聪明之处就在这里——它给贡献者发的不是工资,是看涨期权。早期以太坊矿工挖矿成本远高于 ETH 当时的现货价,但他们买的是一张未来的彩票。
这条逻辑成立,但它对 OpenLedger 这个特定场景的解释力其实有限。原因在于,期权对不同人群的诱惑力差异巨大。对一个 25 岁的程序员、一个加密信徒、一个手里有闲钱的早期用户——花两小时贡献一份看涨期权,完全划得来,这是他们的人群属性。但对一个 45 岁的三甲主治医生、一个忙得喝水都没空的合伙人律师——他不缺机会成本的现金兑现,他缺的是时间。把他业余的两小时换成一张可能归零、可能 10x 的彩票,在他的人生坐标里,这笔交易吸引力极低。期权激励能召唤的是愿意 bet 时间的人,不是最缺时间的真专家。
所以问题不是 token 激励本身没用,是它系统性地筛选出来的贡献者,跟 Datanet 想要的目标人群,是两个不太重叠的圈。
那谁会真的进来?
两种人。一种是没有 opportunity cost 的边缘人——退休的、转行的、本来就没什么咨询业务的、自封"行业人士"的。OpenLedger 给的那点 token 加上看涨期权对他们就有吸引力,但他们的专业水平跟"在临床/法庭/交易桌上每天处理真问题的人"之间,有不可忽略的差距。另一种是为 token 投机进来的——根本不是专家,但他们包装出"看起来像专家写的"数据。这类人在所有激励性协议里都泛滥过。
也就是说,OpenLedger 的激励机制系统性地筛掉了它最需要的那种贡献者,吸引来的恰恰是它最不需要的。这不是哪个机制设计错了,是基础的劳动经济学加上期权吸引力的人群差异。
这件事让我想起 Hugging Face 的高质量数据集。它们大部分不是 token 激励出来的,是研究机构、企业用预算雇专业人力做出来的——朴素的雇佣关系,按市场价付钱。这套机制不性感,但有效。OpenLedger 试图用 token 期权替代雇佣,在很多场景下成立(普通用户标注、低门槛任务),但在"垂直领域专家众包"这个它最想做的场景下,期权吸引的人群和真专家几乎不重叠。
任何 token 激励的数据网络,真专家进得来不,不看它给的名义数额,看它给的期权对哪类人有吸引力——这两者经常不是一码事。期权激励不是无差别的吸引力,它对早期、对加密原生、对愿意 bet 时间的人最有效,而这群人和真正的领域专家,交集很窄。
我对 OpenLedger 在 Datanet 上做的工程是认可的——可追溯、可归因这些都是真的。但我会盯一个具体的信号:看它公布的数据贡献者构成,有没有真名实姓的现任专家、有没有具备可验证从业背景的人。在这个比例之前,Datanet 上跑的"专业数据",更可能是一个由半专家和投机者组成的群体在生产——这跟它卖给市场的"真专家众包"叙事,中间隔着一道劳动经济学加期权人群差异的鸿沟。