Stavo guardando di nuovo @OpenLedger . Specificamente a questo concetto attorno al quale continuano a centrare tutto: la provenienza dei dati. L'idea che ogni pezzo di dati di addestramento usato in un modello di AI dovrebbe avere un'origine tracciabile. Che i contributori dovrebbero essere accreditati, compensati e verificabili on-chain.
Sembra pulito. Sembra quasi ovvio quando lo dici ad alta voce.
Ma poi ho iniziato a pensare — aspetta, cosa significa davvero "on-chain" qui?
Perché ecco il punto che mi ha fatto inciampare. Quando OpenLedger parla di provenienza, stanno descrivendo l'attribuzione. Chi ha contribuito con quali dati. Ma attribuzione e verifica non sono la stessa cosa. Continuavo a confonderli e penso che lo facciano anche molte altre persone.
L'attribuzione è l'affermazione. La verifica è la prova.
Se ti dico che ho contribuito con 10.000 righe di dati finanziari etichettati a un modello, quella è un'attribuzione. Se c'è un meccanismo che conferma in modo indipendente la qualità, l'unicità e l'effettivo utilizzo di quelle righe nell'addestramento del modello — quella è una verifica. Uno è un record. L'altro è prova.
Il modello di Proof of Attribution di OpenLedger registra il primo. Il secondo è... ancora un po' nebuloso per me.
Ho cercato dove avviene esattamente la validazione. Il sistema emette ricompense ai contributori basate sui punteggi di qualità dei dati. Ma quei punteggi — per quanto riesca a rintracciare — provengono da computazioni off-chain. Il numero arriva on-chain, ma il processo che genera quel numero non lo fa. Il che significa che ciò che viene registrato come provenienza è realmente solo una ricevuta verificata per un processo non verificato.
E non sto dicendo che sia fraudolento. Sto dicendo che è una scelta di design specifica che la maggior parte delle persone che leggono il whitepaper probabilmente ignoreranno. La trasparenza pubblicizzata è reale, ma è trasparenza sugli output, non sugli input.
Ecco la parte che mi preoccupa di più però.
La provenienza dei dati come concetto è stata presa in prestito dalla ricerca scientifica. In quel contesto, significa che puoi rintracciare un dataset attraverso ogni trasformazione che ha subito — pulizia, etichettatura, fusione — con la sorgente originale intatta. La catena di custodia, essenzialmente. OpenLedger sta usando il termine in un senso più ristretto: chi ha inviato i dati e se sono passati attraverso un filtro di qualità.
Non è sbagliato. Ma non è nemmeno ciò che qualcuno con un background in data science riconoscerebbe come una piena provenienza. E il divario tra queste due definizioni è dove viene implicitamente riposta molta della fiducia.
Ci ho pensato di più e penso che la versione onesta di ciò che OpenLedger sta costruendo sia un libro mastro dei contributori con staking di reputazione, non un sistema completo di tracciamento dei dati. Che è comunque utile. Potenzialmente ancora prezioso per lo sviluppo dell'IA. Ma è una cosa diversa da ciò che la parola "provenienza" suggerisce.
Se quella distinzione abbia rilevanza per la persona media che detiene $OPEN — Non lo so. Il prezzo del token non si muove su sfumature definitorie. Ma probabilmente avrà rilevanza alla fine, quando gli acquirenti aziendali iniziano a fare due diligence sui modelli di IA addestrati tramite questo sistema e pongono esattamente quelle domande.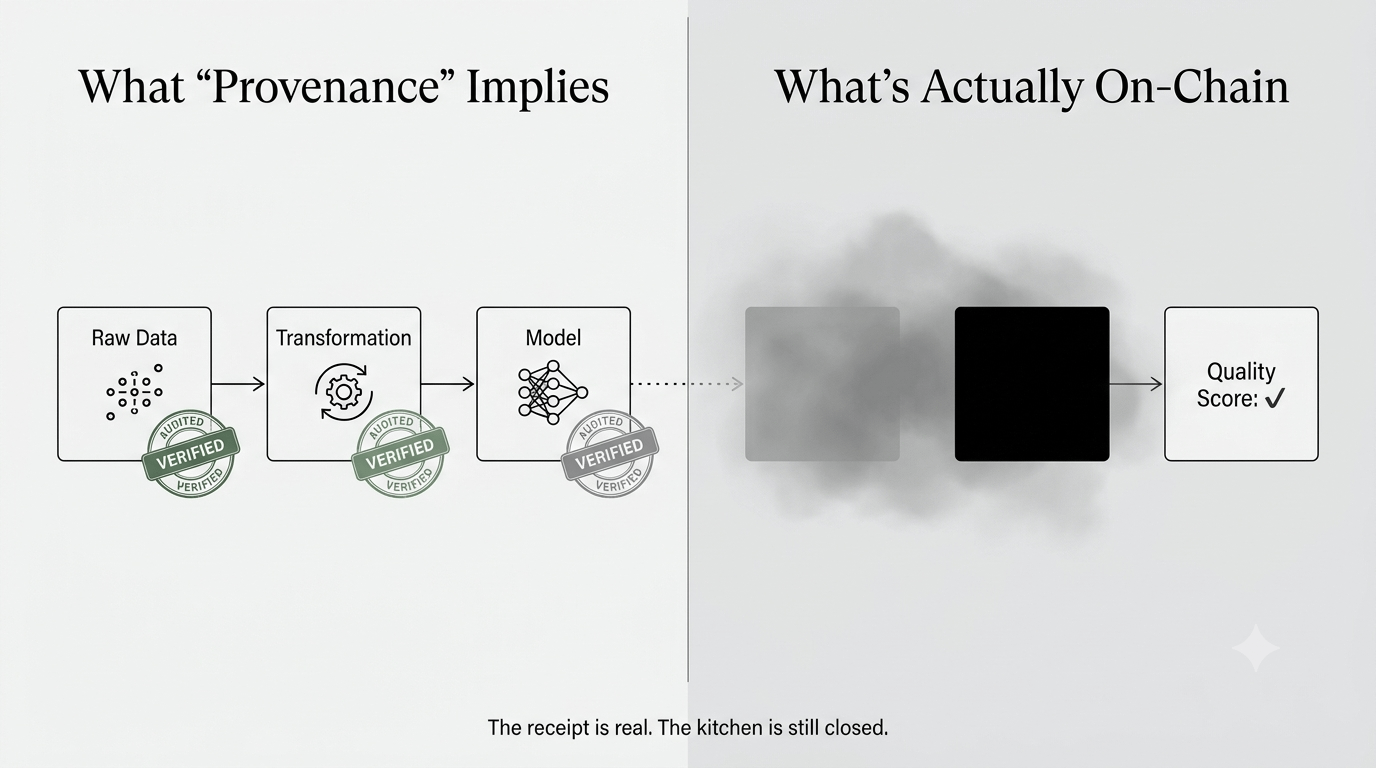
Non sono completamente convinto che questo regga sotto un'attenta analisi da parte degli acquirenti di dati istituzionali. L'argomento per loro è: usa modelli di IA con dati di addestramento verificabili e ottenuti in modo etico. Ma verificabili come? Attraverso il sistema di punteggio di OpenLedger? Questo non è una verifica di terza parte. È un fornitore che ti dice che la sua catena di approvvigionamento è pulita.
\u003cc-57/\u003e\u003ct-58/\u003e